
vits声音合成-本地部署(windows)-自己组合ai的第二步
这些是vits的衍生版本(没有配置使用过):
https://github.com/PlayVoice/vits_chinese(不是教程版本)
https://github.com/Plachtaa/VITS-fast-fine-tuning(小白的最好选择)
https://github.com/svc-develop-team/so-vits-svc(三方维护衍生版)
本文档基于:
windows11
CUDA 12.1
Anaconda
Anaconda对于配置单个AI可有可无,这是用来用于虚拟多个python环境,防止之后组合别的ai出现环境和包不匹配导致安装多AI失败的情况,比如拟声鸟需要的是python3.9,而stablediffusion需要的是python3.10,以及各个包之间会有相同的依赖库但版本不同
nccl(无法在windows运行),windows使用的是gloo(无需下载文件)
Cmake(需要先下载microsoft visual studio【社区版就行(community)】)
FFmpeg
显卡2080ti(很慢,1500的训练用了一天,一般建议配置不好的各位后面配置config.json的时候填的虽然是10000,但可以在1500左右就使MogGoeGUI跑一下,一般好的训练材料已经可以出效果了)

开始(前置准备):
【这版教程很匆忙,我没有设置网盘资源】
查看当前电脑的CUDA版本:
打开“命令提示符(CMD)”
输入nvidia-smi

下载所用文件:
下载vits项目(Github)
https://github.com/jaywalnut310/vits(原版,非教程版,步骤差不多,但是缺少对于中文的支持,动手能力强的可以自己修改其中代码增加对于中文的支持,尤其是symbol.py和cleaner.py)
github.com/CjangCjengh/vits(Cj中文版vits【大部分改动在对于中文的处理上】)
下载AnaConda(Windows):
https://www.anaconda.com (主页)
https://repo.anaconda.com/archive/Anaconda3-2023.03-Windows-x86_64.exe
https://mirrors.bfsu.edu.cn/anaconda/(北京外国语大学开源软件镜像站)
msvc:
https://visualstudio.microsoft.com/zh-hans/downloads/
下载pytorch文件(以防各种莫名其妙的pytorch报错):
命令行方式:https://pytorch.org/get-started/locally/
Pytorch下载:
https://download.pytorch.org/whl/ (所有库下载)
pytorch:
https://download.pytorch.org/whl/torch
cp:python版本(cp310=python3.10版本)
cu:cuda版本(cu118=cuda11.8版本) 使用显卡
cu118可以适用于cuda12.1版本
cpu:cpu版本 使用CPU
cpu版本适用于显卡显存不足6g的电脑
2.0.0为最新版本
Pytorch Audio
https://download.pytorch.org/whl/torchaudio
Pytorch Vision
https://download.pytorch.org/torchvision/
CUDA下载(CUDA Toolkit):
https://developer.nvidia.com/cuda-downloads
Git下载(梯子在这个项目中非常重要,最好有梯子):
https://git-scm.com/downloads
需要的软件:
shotcut(导出音频文件):
https://www.shotcut.org
buzz(语音转文字,安装运行,基于openai的whisper,我项目里直接使用的代码制作训练集,放置于评论区)
https://github.com/chidiwilliams/buzz/releases/tag/v0.7.2
audio-slicer(视频切片,.exe文件运行,可以多切几次弄多一点训练材料,参数自己调整,最好每一条都在5秒以内)
https://github.com/flutydeer/audio-slicer/releases/tag/v1.1.0
Espeak:
https://github.com/espeak-ng/espeak-ng/releases/tag/1.51(只在环境变量中用到)
FFmpeg:
https://github.com/BtbN/FFmpeg-Builds/releases(win,文件大小126M的版本,只在环境变量中用到)
MoeGoeGUI:
https://github.com/CjangCjengh/MoeGoe_GUI/issues(用于使用训练好的模型)
配置环境变量:
按照自己的安装路径修改
PHONEMIZER_ESPEAK_LIBRARY
PHONEMIZER_ESPEAK_PATH


环境变量(path中):
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\libnvvp
D:\Microsoft\Microsoft Visual Studio\Visual Studio\Common7\IDE\CommonExtensions\Microsoft\CMake\CMake\bin
C:\Program Files\Microsoft SQL Server\Client SDK\ODBC\170\Tools\Binn\
C:\Program Files\NVIDIA Corporation\Nsight Compute 2023.1.0\
D:\Microsoft\Microsoft Visual Studio\Visual Studio\Common7\IDE\CommonExtensions\Microsoft\CMake\CMake\bin



假设我的项目路径在
C:\Users\用户名\Desktop\AIS\vits-main\
Vits配置安装:
使用anaconda prompt
conda create -n 名字 想要安装的包(=指定版本)
首先使用conda创建一个3.9的python环境
示例:
conda create -n vits python=3.9
激活python环境
conda activate 你的环境名字

示例:
conda activate vits
cd 你的项目文件夹路径(之后操作只有安装依赖文件会改变路径到monotonic_align下)
示例:
cd C:\Users\用户名\Desktop\AIS\vits-main\
pip install 下好的torch,torchaudio,torchvision文件路径
示例:
pip install C:/torch.whl
由于我们安装好了pytorch,就不使用它自带的老版本了容易出错,所以我们需要修改安装依赖文件
requirement.txt文件内容修改为:
Cython==0.29.21
librosa==0.8.0
matplotlib==3.3.1
numpy==1.18.5
phonemizer==2.2.1
scipy>=1.5.2(可能是python版本问题导致无法安装1.5.2只能安装大于1.5.2的版本)
tensorboard==2.3.0
Unidecode==1.1.1
anaconda prompt在项目文件夹路径下输入
pip install -r requirement.txt
修改项目文件(极度重要【中文训练】),尽量避免之后的报错:
都是项目文件夹下
train.py
52行【原版需要修改】:
os.environ['MASTER_PORT'] = '8000'
67行【windows修改,nccl在windows用不了】:
dist.init_process_group(backend='gloo', init_method='env://', world_size=n_gpus, rank=rank)
104行【问题在下面】:
net_g = DDP(net_g, device_ids=[rank],find_unused_parameters=True)
105行【同104】:
net_d = DDP(net_d, device_ids=[rank],find_unused_parameters=True)
preprocess.py
这个文件中可以不用设置,但在使用预处理命令时需要加上参数
9行【设置为你制作好的数据集文件,_val文件是校验集】:
parser.add_argument("--filelists", nargs="+", default=["filelists/list.txt", "filelists/list_val.txt"])
10行【中文版设置,原版训练英文的不用管】:
parser.add_argument("--text_cleaners", nargs="+", default=["chinese_cleaners"])
mel_processing.py
pytorch包太新了导致的
66行,67行【onesided=True后增加,return_complex=False】
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device],center=center, pad_mode='reflect', normalized=False, onesided=True,return_complex=False)
104行,105行【onesided=True后增加,return_complex=False】
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[wnsize_dtype_device], center=center, pad_mode='reflect', normalized=False, onesided=True,return_complex=False)
utils.py
146行,147行【default中为训练时的config.json文件位置,可以不设置,训练的时候可以使用-c参数配置】
parser.add_argument('-c', '--config', type=str, default="./configs/base.json",help='JSON file for configuration')
146行,147行【help中为训练设置的模型名,可以不设置,训练的时候可以使用-m参数配置】
parser.add_argument('-m', '--model', type=str, required=True,help='Model name')
152行【训练设置的模型名是个文件夹,在这个文件夹下,实际用到的是G_*.pth这个文件】
model_dir = os.path.join("../drive/MyDrive", args.model)
datautils.py
323行【不设置一定报错】
for i in range(len(buckets) - 1, -1, -1):
训练材料(炼丹材料)和list.txt放置方式以及config配置:
训练集制作【最好没有背景杂音】
下载视频,然后使用Shotcut导出为wav,一定要是单声道不然训练容易报错
点击输出

参数为:采样22050Hz,16bit(16位),单声道

然后打开audio-slicer:

然后弹出界面,配置参数:

左上点击选择文件
参数:
Threshold(dB):低于这个分贝就会切割
Minimum Length(ms):最小的切割长度
Minimum Interval(ms):最小的切割间隔
Hop Size(ms):粗略理解为精确度(10-20就行了)
Maximum Silence Length(ms):最大沉默(无声)时间
最后这个是输出目录
进度条到100%就去文件夹里看看
【假设我导出的文件夹在C:\Users\用户名\Desktop\AIS\Vedios】
然后使用buzz(没有批量导出,批量导出还是自己想办法或者用python自己写,有人需要的话评论区留言,下一期我就写whisper的配置以及在python中的使用)
点击+号导入文件,可以按住shift批量选,
Tiny改选medium(模型,这个软件用的是CPU)
Language:选中文(其他语言也可以)
点击run就行

这样就是完成

双击这条数据,然后右下角选TXT导出到文件夹中,作为训练音频的文本数据
【假设我导出的文件夹在C:\Users\用户名\Desktop\AIS\Txt】
然后制作两个文件,文件名随意,但一个是训练集一个是验证集,而且是txt文件(无BOM头),不然训练时会报错,文件中的格式参考官方【两个文件格式一样】

【官方为多人多训练数据格式】
黄色:audio-slicer切割好的wav音频文件路径(绝对路径最好,相对路径会计算也可以)
绿色:说话人数大于一个人时设置,第一个说话的为0,第二个为1以此类推(只有一个人时不写)
天蓝色(湖蓝色):文字语言类型(可以不写)
橙色:音频文本(涉及训练质量)
紫色:文字语言类型(可以不写)
【单个人说话的基本格式】(|:分割符)
音频文件路径|音频文本
示例:
C:\Users\用户名\Desktop\AIS\Vedios\test.wav|示例文本
(默认说话人为0)
【假设我导出的文件夹在C:\Users\用户名\Desktop\AIS\vits-main\filelist】
文件名为【list.txt,list_val.txt】
文件路径为:
【C:\Users\用户名\Desktop\AIS\vits-main\filelist\list.txt】
【C:\Users\用户名\Desktop\AIS\vits-main\filelist\list_val.txt】
训练参数文件:
以下操作全在
【C:\Users\用户名\Desktop\AIS\vits-main\】文件夹下(假设的项目文件夹)
config下创建文件(原版基于ljs_base.json,中文版基于chinese_base.json)
【可以复制粘贴然后直接改名】,文件名自定义:
【假设文件名:chinese_config.json】
重要训练参数:
查看中文版官方给的chinese_base.json为例

eval_interval【保存间隔】:
默认的1000即可以满足保存的需求,设置过小会训练过程会耗费大量时间在保存上,设置过大出现问题无法及时保存最近的模型。
epochs【迭代次数】:
比较好的数据集训练1500次就能出现效果,2000已经勉强可以使用,这里建议一万到两万效果最佳,但是那是显卡好的情况,差的话可能要训练好几天,甚至一个月。
batch_size【使用显存,4:6GB,6:10GB】
(除非富哥或者租卡的,不然不设置就等着一直爆显存了):
请按照你的显存酌情修改,否则开始训练就爆显存。
fp16_run【半精度训练】:
默认开启即可,配置足够优秀可以尝试关闭。

data部分:
training_files:训练数据文本文件preprocess(预处理)后文件路径
示例:
C:\Users\用户名\Desktop\AIS\vits-main\filelist\list.txt.cleaned
validation_files:训练数据验证文件preprocess(预处理)后文件路径
示例:
C:\Users\用户名\Desktop\AIS\vits-main\filelist\list_val.txt.cleaned
text_cleaners【text文件夹下cleaner.py中的def方法,就是这里的名称】
n_speakers【说话人数】:
单人改为0
cleaned_text【保持默认的true即可】
【假设配置文件路径:C:\Users\用户名\Desktop\AIS\vits-main\config\chinese_config.json】
开始训练:
回到anaconda prompt:

按照官方给的方式使用:
安装训练依赖:
切换到项目下的monotonic_align文件夹
cd monotonic_align
python setup.py build_ext --inplace
小坑:
monotonic_align下还要建立一个文件夹叫monotonic_align,不然报错
回到项目文件夹:
cd ..
预处理:
python preprocess.py --text_index 1 --filelists 两个list.txt文件的位置,中间用空格分开
示例:
python preprocess.py --text_index 1 --filelists C:\Users\用户名\Desktop\AIS\vits-main\filelist\list.txt C:\Users\用户名\Desktop\AIS\vits-main\filelist\list_val.txt
训练
python train.py -c 自定义config.json文件路径 -m 输出后的model名称
# LJ Speech(常用)
python train.py -c configs/ljs_base.json -m ljs_base
示例:
python train.py -c C:\Users\用户名\Desktop\AIS\vits-main\config\chinese_config.json -m TestModel【之前文件设置过的话直接python train.py就行了】
# VCTK
python train_ms.py -c configs/vctk_base.json -m vctk_base
示例:
python train_ms.py -c C:\Users\用户名\Desktop\AIS\vits-main\config\chinese_config.json -m TestModel【之前文件设置过的话直接python train_ms.py就行了】
训练模型使用
====> Epoch:1【显示这个就是开始训练了】

训练模型存放位置默认为项目文件的上一级文件夹的drive文件夹中
打开MoeGoe
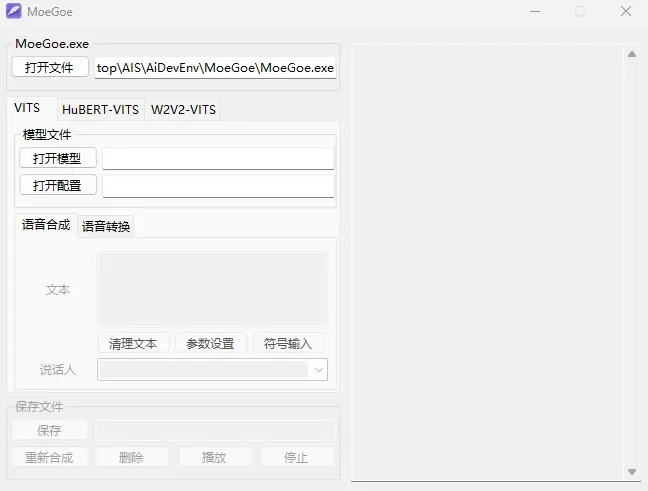
打开文件是他自己的.exe
打开模型选择【G_数字.pth】
示例:G_81000.pth
打开配置选择【config.json】
config.json是在训练后的模型这个文件夹中的,不要选项目文件夹中的那个,虽然文件格式一样,但就怕出bug
然后说话人选之前文本中设置过的,单人为0
点击保存,保存后的文件为wav文件
问题总览:
包问题【No module named】(一律使用pip解决)
No module named 'numpy.random.bit_generator'
pip install numpy==1.19.3
TypeError: Descriptors cannot not be created directly. If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. If you cannot immediately regenerate your protos, some other possible workarounds are: 1. Downgrade the protobuf package to 3.20.x or lower. 2. Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and will be much slower).
pip install protobuf==3.20.0
问题:
ValueError: port must have value from 0 to 65535 but was 80000.
解决方法:
修改train.py或train_ms.py文件
os.environ['MASTER_PORT'] = '80000'
改为没被占用的端口号(80,3306,22,21,20,443等常用端口不要去设置,比如:网页常用端口,后端和数据库常用端口,应用服务已占用端口如微信、MC服务器等,服务占用的端口,数据库常用端口,文件传输常用端口,各种协议如邮件传输协议的常用端口等端口,一定需要避免设置这些端口,且范围控制在0~65535中)
例子:os.environ['MASTER_PORT'] = '5321'
问题:
导致vits在windows上无法一次启动的原因:
RuntimeError("Distributed package doesn't have NCCL " "built in")
RuntimeError: Distributed package doesn't have NCCL built in
解决方法:
(Linux)
https://developer.nvidia.com/nccl
https://docs.nvidia.com/deeplearning/nccl/install-guide/index.html
(windows)
修改train.py或者train_ms.py文件
init_process_group(backend="gloo", init_method="env://")
问题:
opencc的包导入问题
解决方法:
注释所有text文件夹中使用opencc的地方,因为很难装,有成功装好的希望给出解决方式在评论区
问题:
NotImplementedError: Only 2D, 3D, 4D, 5D padding with non-constant padding are supported for now
解决方法:
重新制作数据集,数据集需要是22050Hz,16bit,单声道(重要!!!)
问题:
stft will soon require the return_complex parameter be given for real inputs, and will further require that return_complex=True
解决方法:
修改mel_processing.py文件
spec = torch.stft(y, n_fft, hop_length=hop_size, win_length=win_size, window=hann_window[str(y.device)], center=center, pad_mode='reflect', normalized=False, onesided=True,return_complex=False)
在出现STFT处增加False消除警告
问题
RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. This error indicates that your module has parameters that were not used in producing loss
解决方法:
修改train.py或者train_ms.py文件
将104和105行模型的参数后加上find_unused_parameters=True
注:但是find_unused_parameters=True的设置会带来额外的运行时开销(而且还不小)。
其他问题解决方案:
https://www.bilibili.com/read/cv22206231/(多错误集合)
https://www.bilibili.com/read/cv21153903(很有用)
https://github.com/jaywalnut310/vits/issues(github评论区)
