
大数据 | Hadoop集群搭建(完全分布式)
知识目录
一、前言
二、配置三台虚拟机
2.1 克隆三台虚拟机
2.2 配置克隆的虚拟机
2.3 使用Xshell连接虚拟机
2.4 配置SSH免密登录
三、Hadoop集群准备
3.1 安装 rsync
3.2 安装xsync分发脚本
3.3 安装JDK和安装Hadoop
3.4 配置环境变量
3.5 分发
四、Hadoop集群搭建
4.1 修改配置文件
4.2 配置workers
4.3 格式化集群
4.4 启动集群
4.5 关闭集群
五、结语
💕欢迎大家:这里是我记录知识的地方,喜欢的话请三连,有问题请私信😘
在集群搭建期间我经历了各种各样的错误,困难和BUG,不过都被我收割了。成功搭建之后,为了加深对Hadoop集群环境搭建的理解,我决定推翻重做,这次重做的过程就顺利多了!终于,历时两小时,我再次搭建好了Hadoop环境,而这篇文章就是我两次搭建总结出来的方法,分享出来希望能帮助到大家。
二、配置三台虚拟机
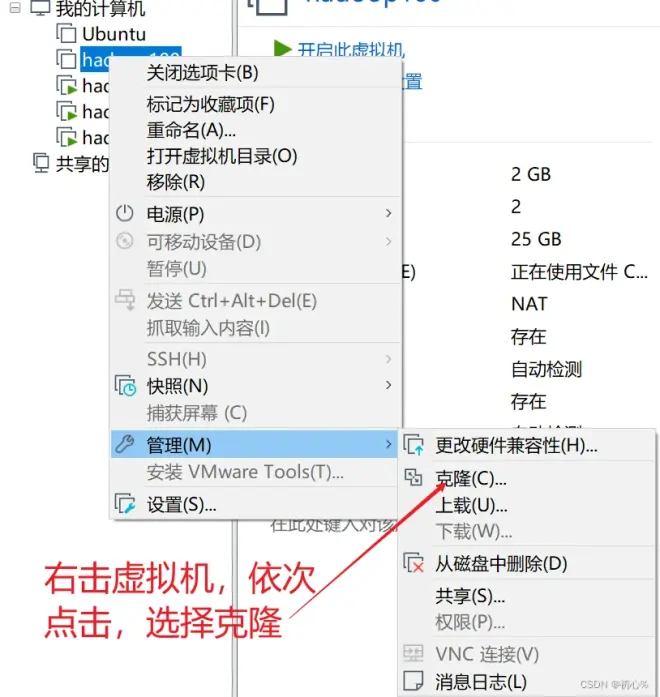
2.1 克隆三台虚拟机
先从一台虚拟机克隆出三台虚拟机,作为搭建Hadoop完全分布式的三个节点。这里我的三个节点分别叫 hadoop102 hadoop103 hadoop104,克隆这里需要注意的地方:
虚拟机要是关机状态才可以克隆
从虚拟机当前状态克隆
创建完整克隆,之后填写虚拟机名称和存放位置就好
2.2 配置克隆的虚拟机
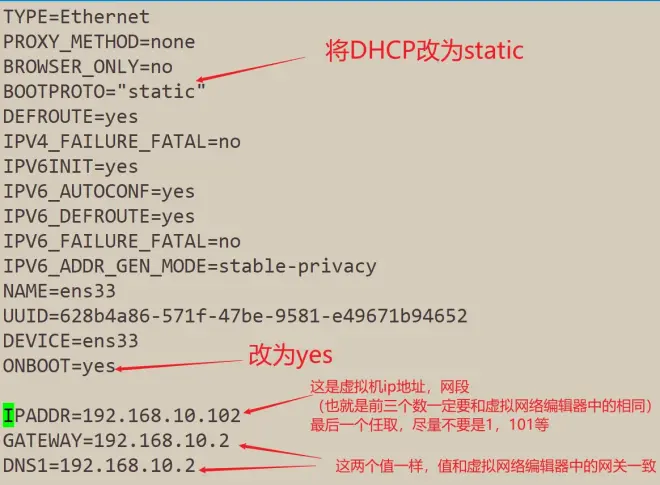
修改网络配置文件
sudo vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改主机名
sudo vim /etc/hostname

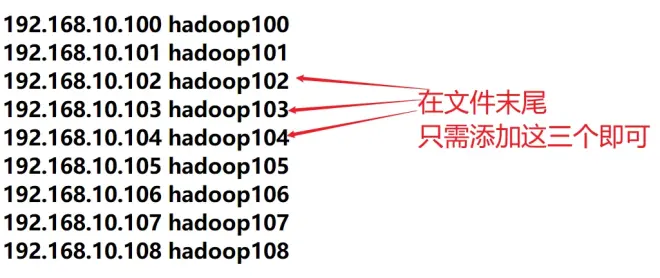
修改客户机内容
sudo vim /etc/hosts

重启reboot,在另外两台虚拟机并上将步骤再重复两次
sudo reboot
Windows配置IP和主机名对应
进入到这个文件夹下,修改hosts文件
C:\Windows\System32\drivers\etc

将这个文件拖动到桌面,使用记事本打开,进行编辑后放回覆盖原文件。
2.3 使用Xshell连接虚拟机
在xshell中新建一个连接,重复三次,分别用xshell连接上三台虚拟机
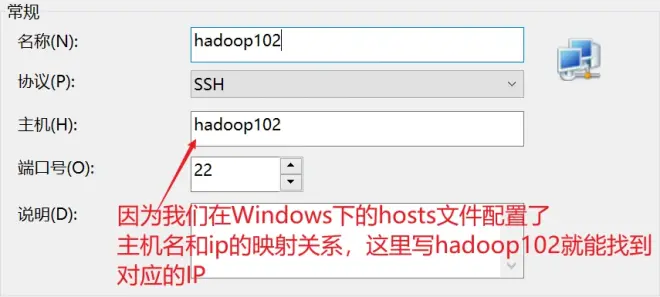
至此,创建三个虚拟机节点,以及使用Xshell连接虚拟机工作我们就做好了。这是搭建Hadoop集群前的准备工作,这里我的 hadoop102 hadoop103 hadoopp104 分别对应的ip为 192.168.10.102/103/104.
2.4 配置SSH免密登录
在搭建Hadoop集群之前,我们还要为三台虚拟机搭建免密登录,这是基础,否则后面会不断提示输入密码。这是一个繁琐的操作,因此配置了免密之后我们就可以省略这些步骤,节省时间。
使用hadoop102登录hadoop102
ssh localhost
接下来会提示问题,输入yes就好,之后输入本机的密码,就可以连接上本机。我们登录本机的目的是在 home 目录下生成 .ssh 隐藏文件夹,以便进行下一步操作,下面退出刚才的登录。
exit
进入到ssh文件夹(centos-1是我的普通用户名,如果虚拟机只有root用户,一定要创建一个普通用户,否则找不到这个文件夹)。
cd /home/centos-1/.ssh/
在ssh文件夹下生成私钥
执行下面的命令生成本机的私钥
ssh-keygen -t rsa
执行完这个命令之后,查看当前文件夹的文件,可以看到多出这两个文件

公私钥对拷
执行下面的命令,将Hadoop102的私钥拷贝到Hadoop102 Hadoop103 Hadoop104上
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
最后,在Hadoop103,Hadoop104上重复上面的步骤,这样就能实现三台机器之前的相互免密登录。
思考:root用户进行免密登录需不需要输入密码?
答案是要。因为root用户下的.ssh文件夹和普通用户是不一样的,如果想要在 root 用户下还能免密登录,也要重复上面的步骤,个人认为hadoop102的root用户配置了免密就可以了,其他的两台也可以配置
三、Hadoop集群准备
3.1 安装 rsync
安装同步工具rsync,这是安装xsync脚本的基础
sudo yum install -y rsync
1
3.2 安装xsync分发脚本
查看环境变量
echo $PATH

进入到在PATH中的一个目录
cd /usr/local/bin
复制下面的分发脚本 xsync.sh ,再使用下面的命令创建xsync文件并粘贴,保存退出
sudo vim xsync
分发脚本xsync.sh

授予可执行权限
sudo chmod 777 xsync
至此,虚拟机的任意目录就可以使用xsync命令。如果不可以使用,则证明安装失败,请仔细检查。
3.3 安装JDK和安装Hadoop
进入centos操作目录
cd /opt
创建JDK和Hadoop的压缩包存放目录和文件存放目录
sudo mkdir module
sudo mkdir software
在Xshell中通过Xftp文件上传工具(或者lrzsz、finalShell等),上传JDK和Hadoop的压缩包到software目录
解压JDK和Hadoop到module目录
tar -xzvf jdk-8u202-linux-x64.tar.gz -C /opt/module/
tar -xzvf hadoop-3.1.3.tar.gz -C /opt/module/
3.4 配置环境变量
进入到/etc/profile.d文件夹
cd /etc/profile.d
my_env.sh文件

新建文件my_env.sh,将my_env.sh文件内容复制进来
sudo vim my_env.sh
刷新环境变量
source /etc/profile
测试环境变量是否配置成功
java
hadoop
如果输出一大片信息说明配置好了
3.5 分发
使用xsync将hadoop102的jdk、Hadoop以及环境变量分发到另外两台虚拟机上。
分发JDK和Hadoop
xsync /opt/module/
分发环境变量
xsync /etc/profile.d/my_env.sh
四、Hadoop集群搭建
4.1 修改配置文件
首次搭建Hadoop完全分布式,要分别修改下面四个文件,这里仅展示configuration标签内的内容。
首先进入到Hadoop的etc目录的hadoop目录
cd /opt/module/hadoop-3.1.3/etc/hadoop/
vim core-site.xml
core-site.xml
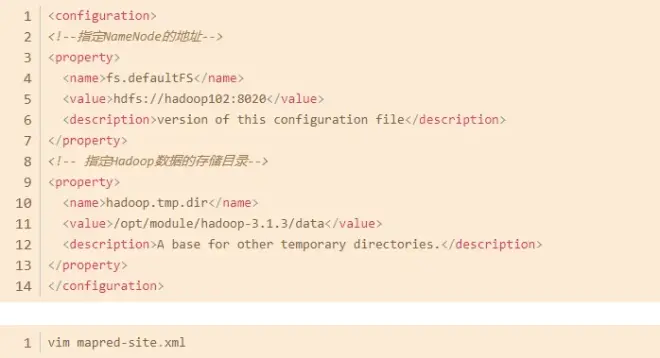
mapred-site.xml
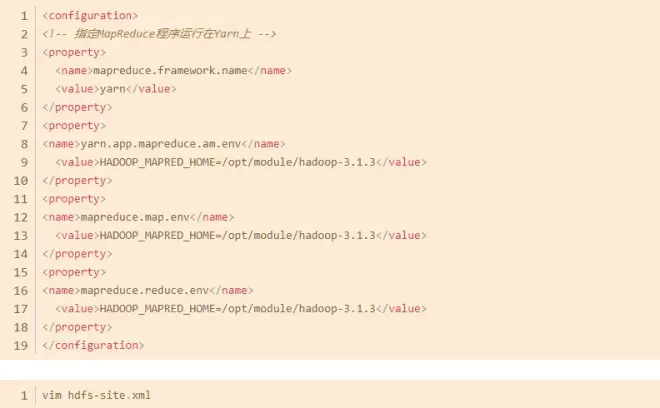
hdfs-site.xml
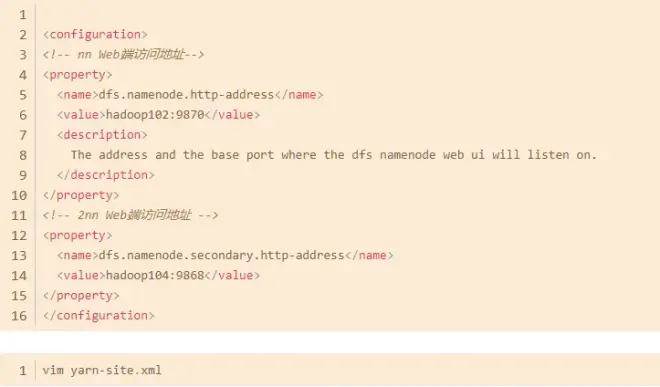
yarn-site.xml
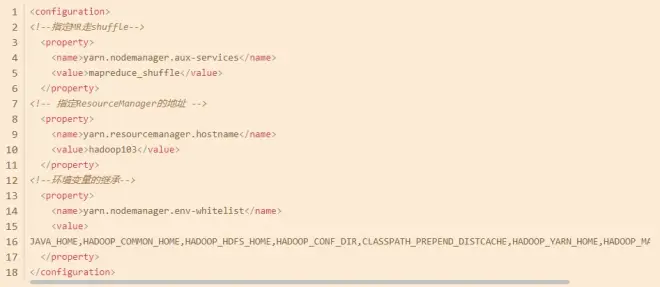
修改完成之后,退出到hadoop目录
cd /opt/module/hadoop-3.1.3/etc
执行分发,将etc下的hadoop目录的四个配置文件同步
xsync hadoop
4.2 配置workers
进入到配置文件目录
cd /opt/module/hadoop-3.1.3/etc/hadoop/
修改workers文件,将文件内容改成三台主机名即可,之后再次分发,将修改同步。
vim workers
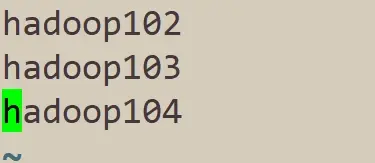
xsync /opt/module/hadoop-3.1.3/etc/hadoop/
4.3 格式化集群
在hadoop102上进行格式化
hdfs namenode -format
1
至此,Hadoop完全分布式(集群)就搭建好了。
4.4 启动集群
下面这张图就是我们搭建的Hadoop集群的集群规划。首先进入到hadoop目录

cd /opt/module/hadoop-3.1.3/
在Hadoop102启动HDFS(Hadoop分布式文件系统)
sbin/start-dfs.sh
在Hadoop103启动YARN(Hadoop资源调度管理)
sbin/start-yarn.sh
使用jps命令来查看进程,验证是否和集群规划一致。
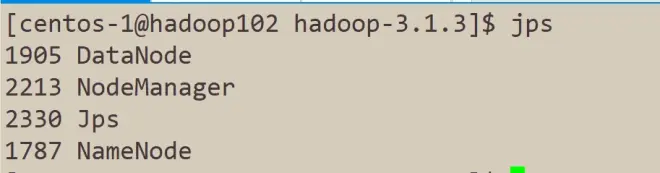
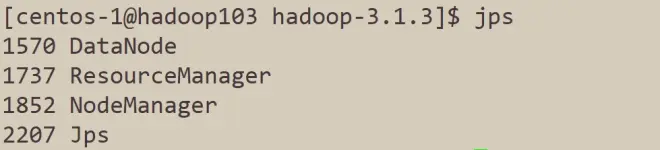
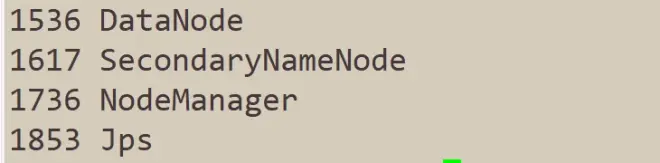
如果按照教程来,执行jps命令得到的结果和上图不一致,请仔细检查是否哪一步出现了问题,再进行下一步。
4.5 关闭集群
首先关闭YARN,再关闭HDFS,至此,Hadoop集群搭建(完全分布式搭建)成功。
sbin/stop-yarn.sh
sbin/stop-dfs.sh
五、结语
学习是一个漫长且持续渐进的过程,其中不免遇到很多困难,有时候让你头痛,让你心慌。有人选择逃避,有人选择全力以赴,希望大家的每一天都变得充实。
