
Swin Transformer从零详细解读

整个视频四部分

回顾TRM模型

TRM的encoder并不改变输入和输出的形状,无论vit还是swin都一样
左边是encoder细节结构,抽象为右边灰色的框框

回顾vit模型

swin相对于vit的创新

如何把图像变成一个个token

问题:复杂度太大

vit问题

swin vs vit
vit:把一张图片分为若干patch(共9个),每个patch作为一个token输入encoder
swin:把一张大图片分为一个个window(共9个),window里每一个像素点作为一个token输入encoder

swintrm整体架构图

看一篇论文最好方法:搞清楚每一个零部件输入和输出的数据的形状和变化
整体形状变化

源代码实现的时候和原架构图不同

patch partition

第二个红色框里的重点内容:
1、相对位置编码如何实现?
2、移动窗口注意力机制如何实现?
3、patch融合如何实现?
相对位置编码的实现
1、TRM中的位置编码:在输入部分+位置编码(正余弦函数,不可以学习)
2、vit模型中划分为一个个patch后没有使用正余弦函数,而是初始化一个个索引,根据索引得到参数

3、swinTRM

swinTRM相对位置信息加在哪里

B的形状是什么
一个例子



什么是绝对位置信息

什么是相对位置信息

网格的绝对位置和相对位置
1种绝对位置信息

4种相对位置信息

怎么把4种相对位置信息加入attention矩阵




position embedding
原始的窗口注意力机制

存在问题

移动窗口注意力

移动前

移动后


当窗口滑动到最右端出现同一窗口不相邻的情况,右下端出现4、5、7、8不相邻
mask符号
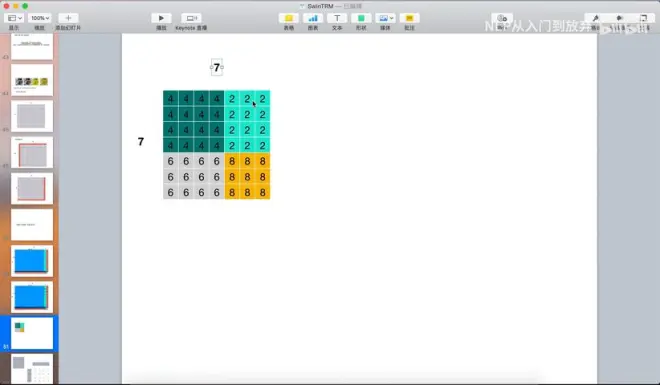
矩阵的信息:0元素代表同一窗口,非0元素代表本不相邻被框到一起

把非0元素置位-100或负无穷,得到mask矩阵


单头

多头

窗口注意力机制

patch merging降采样

