
CVPR Workshop - Scholars and Big Models
趁着今天的meeting比较少,花时间看了下CVPR中的一个workshop,叫Scholars and Big Models - How Can Academics Adapt (https://sites.google.com/view/academic-cv/),学到了很多,也做了些思考,简单记录下,以免后面忘了。
1. 在计算机视觉高速发展中,大家shared concern,excitement。




Random Thought - 1:
最近会被学生问到,我实验室的工作时长,我的回答:这是你们自己的PhD项目,我只负责最大程度上提供帮助,但我不是监工,如果自己不上心,不能够在规定的时间内完成某个project,整个community会为你提供penalty signal,意味着你前期的所有时间,准备工作都付之东流。另外,更遗憾的是,你的advisor还会放心把好的idea给你来做吗? Unfortunately,this is how the community works at the moment.
2. 计算机视觉研究中各行业的角色

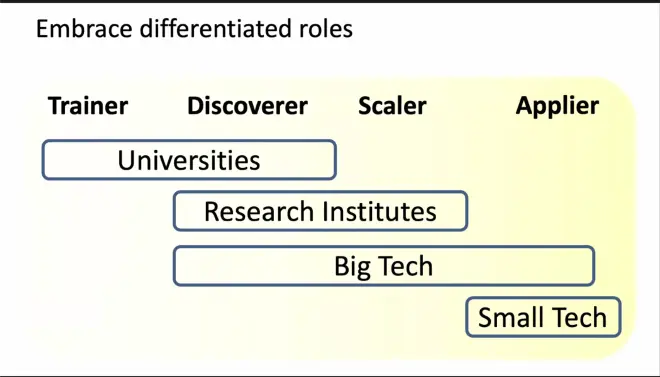
3. 有太多的领域/问题值得去进一步探索和解决,



Random Thought - 2:
在最近几个月中,伴随着几个大模型的开放使用,例如,ChatGPT,SAM,CLIP等,整个视觉领域的研究范式的确发生了颠覆性的改变,别的不说,几乎所有研究都从之前vision-only research,转为vision-language joint representation learning,因为在language的空间中,人类先验知识能够更兼容易的被编码,能够更好的用来guide visual representation learning。
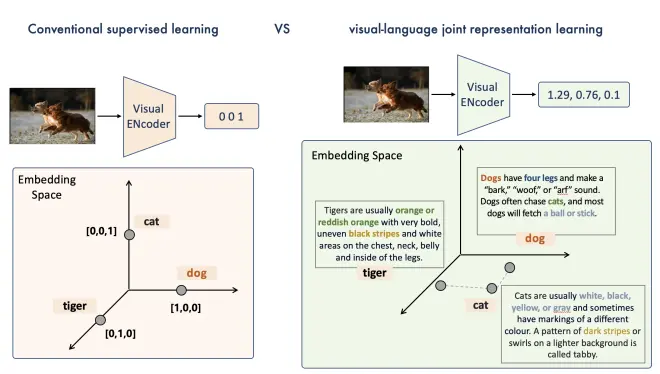
但实话说,目前的CV model,总是给我一种一瓶子不满,半瓶子逛游的感觉,为什么这么说哪,比如
(1)我想对图像进行编码或分类,想着来用用CLIP,全局编码,没有细节,分类也并不是很准,
(2)我想对图像进行caption,想着用用BLIP2,用了一下,发现就那么回事儿,大体说的话不是很离谱,但完全没有任何细节,例如颜色, 大小,形状等,
(3)我想对图像或视频提取object-centric representation,来个SAM模型用用吧,也就那么回事儿,依然是难以处理extreme pose,occlusion,large vocabulary,
(4)生成一张图,来个diffusion model吧,生成的怎么样哪?sometimes impressive,sometimes rubbish, 连几只狗,品种都搞不清楚,
尽管public benchmark上看起来一片大好,perception解决了吗,没觉得.......
Personal Notes:
Anyway,看了大家激烈的讨论,还是很受益的,逼迫自己坐下来花时间思考思考。同时也感到很惭愧,反思自己每天都在瞎忙活,真正坐下来读论文和思考的时间被挤压的很少。后面一定要多思考,多拒绝,少答应一些没用的事儿。。。。。
