
详细的数据可视化库之Seaborn教程—catplot:分类型数据作坐标轴画图

用分类数据绘图¶
在关系图教程中,我们看到了如何使用不同的视觉表示来显示数据集中多个变量之间的关系。在示例中,我们关注主要关系在两个数值变量之间的情况。如果主要变量之一是“分类的”(分为离散组),则使用更专业的可视化方法可能会有所帮助。
在 seaborn 中,有几种不同的方式来可视化涉及分类数据的关系。以之间的关系类似relplot(),要么scatterplot()或者lineplot(),有两种方法可以让这些地块。有许多轴级函数用于以不同方式绘制分类数据,还有一个图形级界面catplot(),可提供对它们的统一更高级别访问。
将不同的分类情节类型视为属于三个不同的系列会很有帮助,我们将在下面详细讨论。他们是:
分类散点图:
stripplot()(使用kind="strip"; 默认值)
swarmplot()(与kind="swarm")
分类分布图:
boxplot()(与kind="box")
violinplot()(与kind="violin")
boxenplot()(与kind="boxen")
分类估计图:
pointplot()(与kind="point")barplot()(与kind="bar")countplot()(与kind="count")
这些系列使用不同的粒度级别表示数据。在决定使用哪个时,您必须考虑要回答的问题。统一的 API 使您可以轻松地在不同类型之间切换并从多个角度查看您的数据。
在本教程中,我们将主要关注图形级界面,catplot(). 请记住,此函数是上述每个函数的高级接口,因此我们将在显示每种绘图时引用它们,并保留更详细的特定于类型的 API 文档。
分类散点图¶
中数据的默认表示catplot()使用散点图。seaborn 中实际上有两种不同的分类散点图。他们采用不同的方法来解决用散点图表示分类数据的主要挑战,即属于一个类别的所有点将落在对应于分类变量的轴上的相同位置。使用的方法stripplot(),它是中的默认“种类”,catplot()是通过少量随机“抖动”调整分类轴上点的位置:

该jitter参数控制抖动的幅度或完全禁用它:

第二种方法使用防止它们重叠的算法沿分类轴调整点。它可以更好地表示观察的分布,尽管它只适用于相对较小的数据集。这种情节有时被称为“蜂群”,是在 seaborn by 中绘制的swarmplot(),通过设置kind="swarm"in激活catplot():

与关系图类似,可以通过使用hue语义向分类图添加另一个维度。(分类图目前不支持size或style语义)。每个不同的分类绘图函数以hue不同的方式处理语义。对于散点图,只需要改变点的颜色:

与数值数据不同,如何沿其轴对分类变量的级别进行排序并不总是很明显。通常,seaborn 分类绘图函数会尝试从数据中推断类别的顺序。如果您的数据具有 pandasCategorical数据类型,则可以在此处设置类别的默认顺序。如果传递给分类轴的变量看起来是数字,则将对级别进行排序。但数据仍被视为分类数据并绘制在分类轴上的序数位置(特别是在 0、1、...),即使使用数字来标记它们:

选择默认排序的另一个选项是采用出现在数据集中的类别级别。也可以使用order参数在特定于绘图的基础上控制排序。在同一个图中绘制多个分类图时,这很重要,我们将在下面看到更多:

我们已经提到了“分类轴”的概念。在这些示例中,它始终对应于水平轴。但是将类别变量放在纵轴上通常会有所帮助(特别是当类别名称比较长或类别较多时)。为此,请交换对轴的变量分配:

类别内观察值的分布¶
随着数据集大小的增长,分类散点图在它们可以提供的关于每个类别中值分布的信息方面变得有限。发生这种情况时,可以采用多种方法来汇总分布信息,以便于跨类别级别进行轻松比较。
箱线图¶
第一个是熟悉的boxplot()。这种图显示了分布的三个四分位数和极值。“胡须”延伸到位于下四分位数和上四分位数 1.5 IQR 内的点,然后独立显示超出此范围的观测值。这意味着箱线图中的每个值都对应于数据中的一个实际观察值。

添加hue语义时,语义变量每个级别的框沿分类轴移动,因此它们不会重叠:

这种行为被称为“躲避”,默认情况下是打开的,因为它假定语义变量嵌套在主分类变量中。如果不是这种情况,您可以禁用闪避:

相关函数boxenplot()绘制类似于箱线图但经过优化以显示有关分布形状的更多信息的图。它最适合更大的数据集:

小提琴图¶
一种不同的方法是 a violinplot(),它将箱线图与分布教程中描述的核密度估计过程相结合:

这种方法使用核密度估计来提供对值分布的更丰富的描述。此外,箱线图中的四分位数和晶须值显示在小提琴内部。缺点是,由于 violinplot 使用 KDE,因此可能需要调整一些其他参数,相对于简单的箱线图增加了一些复杂性:

当色调参数只有两个级别时,也可以“拆分”小提琴,这样可以更有效地利用空间:
kind="violin", split=True, data=tips)

最后,在小提琴内部绘制的图有几个选项,包括显示每个单独观察而不是汇总箱线图值的方法:
kind="violin", inner="stick", split=True,
palette="pastel", data=tips)

结合swarmplot()或striplot()与箱线图或小提琴图一起显示每个观察结果以及分布摘要也很有用:
sns.swarmplot(x="day", y="total_bill", color="k", size=3, data=tips, ax=g.ax)

类别内的统计估计¶
对于其他应用程序,您可能希望显示值集中趋势的估计值,而不是显示每个类别内的分布。Seaborn 有两种主要方式来显示这些信息。重要的是,这些函数的基本 API 与上面讨论的那些相同。
条形图¶
实现这一目标的一种熟悉的情节风格是条形图。在 seaborn 中,该barplot()函数对完整数据集进行操作并应用一个函数来获得估计值(默认取平均值)。当每个类别中有多个观测值时,它还使用自举法计算估计值的置信区间,该区间使用误差线绘制:
sns.catplot(x="sex", y="survived", hue="class", kind="bar", data=titanic)

条形图的一个特例是当您想要显示每个类别中的观察数而不是计算第二个变量的统计量时。这类似于分类变量而非定量变量的直方图。在 seaborn 中,使用countplot()函数很容易做到这一点:

既barplot()和countplot()可以被调用以所有的选项上面所讨论的,与他人被每个功能的详细文档中所示沿着:
palette="pastel", edgecolor=".6",
data=titanic)

点图¶
该pointplot()函数提供了一种用于可视化相同信息的替代样式。此函数还使用另一个轴上的高度对估计值进行编码,但不是显示完整的条形图,而是绘制点估计值和置信区间。此外,pointplot()连接来自同一hue类别的点。这可以很容易地看出主要关系是如何作为色调语义的函数而变化的,因为你的眼睛非常擅长观察斜率的差异:

虽然分类函数缺乏style关系函数的语义,但改变标记和/或线型以及色调以使图形最易于访问并在黑白中重现良好仍然是一个好主意:
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic)

绘制“宽格式”数据¶
虽然首选使用“长格式”或“整洁”数据,但这些函数也可以应用于各种格式的“宽格式”数据,包括 Pandas DataFrames 或二维 numpy 数组。这些对象应该直接传递给data参数:
sns.catplot(data=iris, orient="h", kind="box")

此外,轴级函数接受 Pandas 或 numpy 对象的向量,而不是 a 中的变量DataFrame:

要控制由上述函数绘制的图形的大小和形状,您必须使用 matplotlib 命令自己设置图形:
sns.countplot(y="deck", data=titanic, color="c")
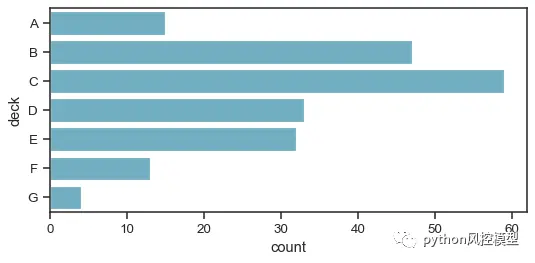
当您需要一个分类图形与其他类型的图在更复杂的图形中愉快地共存时,这是您应该采用的方法。
显示多个方面的关系¶
就像relplot(),catplot()建立在一个事实之上FacetGrid意味着很容易添加分面变量来可视化更高维的关系:
col="time", aspect=.7,
kind="swarm", data=tips)

为了进一步自定义绘图,您可以使用FacetGrid它返回的对象上的方法:
kind="box", orient="h", height=1.5, aspect=4,
data=titanic.query("fare > 0"))
g.set(xscale="log")

catplot-用分类数据绘图就为大家介绍到这里,欢迎各位同学报名《呆瓜半小时入门python数据分析》https://ke.qq.com/course/3064943,学习更多相关知识

