
花了2万多买的Python教程全套,现在分享给大家,入门到精通(Python全栈

#思凡的笔记——Python
Last Update Date:2023-8-9
更新至:89P
前言:争取简约而精确,欢迎大家借鉴、监督,共同进步
- Note1:该笔记为自用,按照自己的理解做了精简,没有太多解释性语言,需要配合视频使用;本人是英语专业大四学生,实习工作之余学习Python,更新也许会比较慢但不会放弃的!
- Note2:最近在忙毕业论文中期答辩的事,每天工作之余要写论文,Python的学习需要推后一阵了(5.15左右)。大家要坚持学哦,我们顶峰相见。
- Note3:哈喽,不知道有没有今年上半年就关注了我的笔记的朋友,会偶然回看这篇已经“停更”三个月的笔记,这段话是写给你们的。停更这么久,是因为我毕业之后一直在找工作,因为不想从事英语相关职业,就报了线下班在学习前端。所以,一是一周六天的课程和晚自习使我的时间精力难以继续学习和更新Python(虽然这个理由对于想学习的人来说只是借口),二是决定要学前端之后,Python的知识就变得不那么重要了,我就失去了再学下去的动力。感谢一些网友对我的私信催促或者几句关心,我也对一些力所能及的提问做了回复。希望仅存的这些拙作/笔记能够在有限的范围内最大程度的帮助到大家,哈哈也许哪天我还是想重拾Python就学完了把笔记也补完了。最后,希望大家能够想清楚自己想要的,坚持下去,每一个上进的人都是可敬的。
print()函数
输出:
①数字
②字符串(加引号)
③含运算符的表达式
转义字符
反斜杠+想要实现的转义功能首字母
①换行:\n (newline)
②回车:\r (return)
③水平制表符:\t (tab)——在不使用表格的情况下在垂直方向按列对齐文本。每8个字符可以看作一个水平制表符,如果遇到 \t 之前未满8个字符,则 \t 就补空格直到满8个
④退格:\b (backspace)
⑤原字符:r...(row)
常见的数据类型
1.整数类型-int (integer)-正数、负数和零
(十进制——默认;
二进制——以0b开头;
八进制——以0o开头;
十六进制——以0x开头)
2.浮点数类型-float-整数、小数
3.布尔类型-bool-True, False
4.字符串类型-str (string)
运算符
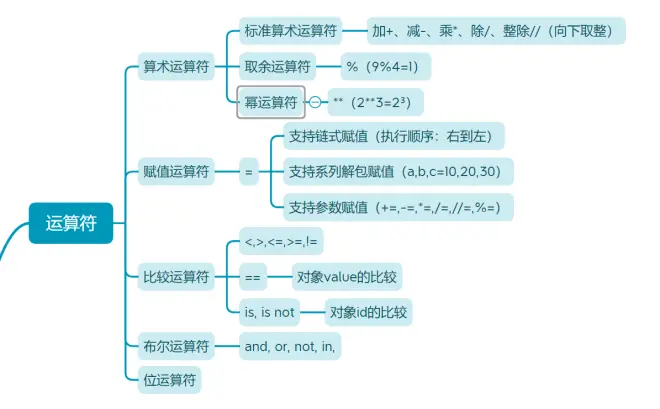
一、算术运算符
1.标准算术运算符
加+、减-、乘*、除/、整除//(向下取整)
2.取余运算符
%(9%4=1)
3.幂运算符
**(2**3=2³)
二、赋值运算符
1.=
支持链式赋值(执行顺序:右到左)
支持系列解包赋值(a,b,c=10,20,30)
支持参数赋值(+=,-=,*=,/=,//=,%=)
三、比较运算符
1.<,>,<=,>=,!=
2.==
对象value的比较
3.is, is not
对象id的比较
四、布尔运算符
- and, or, not, in,
五、位运算符
选择结构
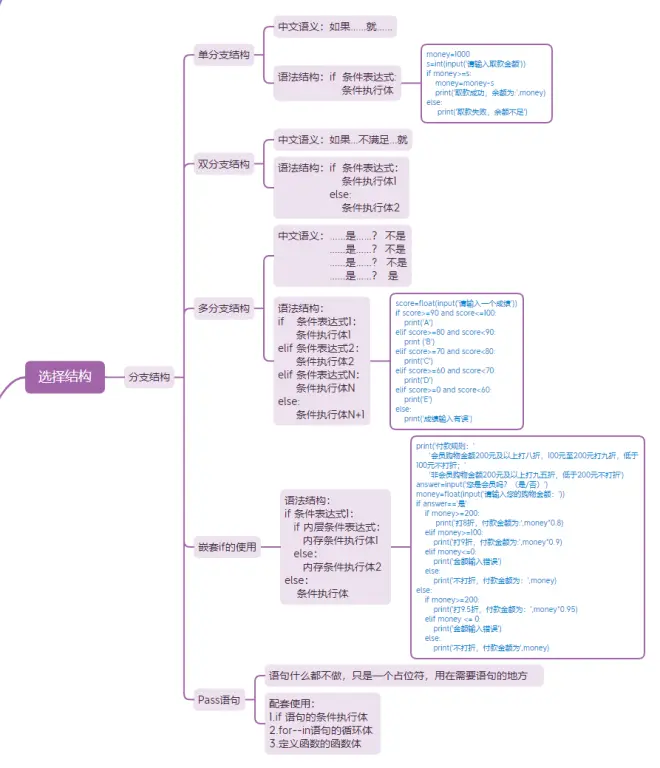
一、单分支结构
中文语义:如果……就……
语法结构:if 条件表达式:
条件执行体
money=1000
s=int(input('请输入取款金额'))
if money>=s:
money=money-s
print('取款成功,余额为:',money)
else:
print('取款失败,余额不足')
二、双分支结构
中文语义:如果…不满足…就
语法结构:if 条件表达式:
条件执行体1
else:
条件执行体2
三、多分支结构
- 中文语义:……是……? 不是
……是……? 不是
……是……? 不是
……是……? 是
- 语法结构:
if 条件表达式1:
条件执行体1
elif 条件表达式2:
条件执行体2
elif 条件表达式N:
条件执行体N
else:
条件执行体N+1
score=float(input('请输入一个成绩'))
if score>=90 and score<=100:
print('A')
elif score>=80 and score<90:
print ('B')
elif score>=70 and score<80:
print('C')
elif score>=60 and score<70:
print('D')
elif score>=0 and score<60:
print('E')
else:
print('成绩输入有误')
四、嵌套if的使用
- 语法结构:
if 条件表达式1:
if 内层条件表达式:
内存条件执行体1
else:
内存条件执行体2
else:
条件执行体
print('付款规则:'
'会员购物金额200元及以上打八折,100元至200元打九折,低于100元不打折;'
'非会员购物金额200元及以上打九五折,低于200元不打折')
answer=input('您是会员吗?(是/否)')
money=float(input('请输入您的购物金额:'))
if answer=='是':
if money>=200:
print('打8折,付款金额为:',money*0.8)
elif money>=100:
print('打9折,付款金额为:',money*0.9)
elif money<=0:
print('金额输入错误')
else:
print('不打折,付款金额为:',money)
else:
if money>=200:
print('打9.5折,付款金额为:',money*0.95)
elif money <= 0:
print('金额输入错误')
else:
print('不打折,付款金额为',money)
五、Pass语句
- 语句什么都不做,只是一个占位符,用在需要语句的地方
- 配套使用:
- if 语句的条件执行体
- for--in语句的循环体
- 定义函数的函数体
循环结构
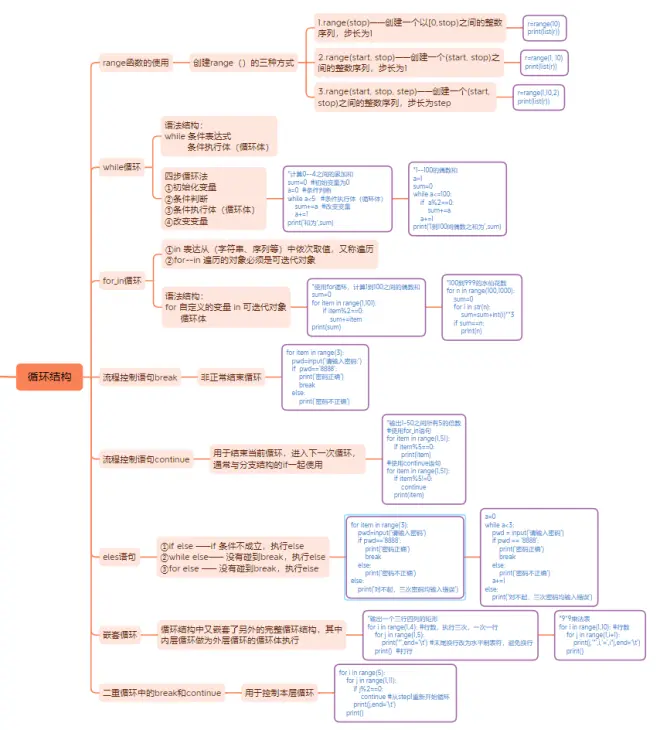
一、range函数的使用
- 创建range()的三种方式
1.range(stop)——创建一个以[0,stop)之间的整数序列,步长为1
r=range(10)
print(list(r))
2.range(start, stop)——创建一个(start, stop)之间的整数序列,步长为1
r=range(1, 10)
print(list(r))
3.range(start, stop, step)——创建一个(start, stop)之间的整数序列,步长为step
r=range(1,10,2)
print(list(r))
二、while循环
- 语法结构:
while 条件表达式
条件执行体(循环体)
- 四步循环法
①初始化变量
②条件判断
③条件执行体(循环体)
④改变变量
#计算0--4之间的累加和
sum=0 #初始变量为0
a=0 #条件判断
while a<5: #条件执行体(循环体)
sum+=a #改变变量
a+=1
print('和为',sum)
#1--100的偶数和
a=1
sum=0
while a<=100:
if a%2==0:
sum+=a
a+=1
print('1到100间偶数之和为',sum)
三、for_in循环
- in 表达从(字符串、序列等)中依次取值,又称遍历
- for--in 遍历的对象必须是可迭代对象
- 语法结构:
for 自定义的变量 in 可迭代对象
循环体
#使用for循环,计算1到100之间的偶数和
sum=0
for item in range(1,101):
if item%2==0:
sum+=item
print(sum)
#100到999的水仙花数
for n in range(100,1000):
sum=0
for i in str(n):
sum=sum+int(i)**3
if sum==n:
print(n)
四、流程控制语句break
非正常结束循环
for item in range(3):
pwd=input('请输入密码:')
if pwd=='8888':
print('密码正确')
break
else:
print('密码不正确')
五、流程控制语句continue
用于结束当前循环,进入下一次循环,通常与分支结构的if一起使用
#输出1-50之间所有5的倍数
#使用for_in语句
for item in range(1,51):
if item%5==0:
print(item)
#使用continue语句
for item in range(1,51):
if item%5!=0:
continue
print(item)
六、eles语句
①if else ——if 条件不成立,执行else
②while else—— 没有碰到break,执行else
③for else —— 没有碰到break,执行else
for item in range(3):
pwd=input('请输入密码')
if pwd=='8888':
print('密码正确')
break
else:
print('密码不正确')
else:
print('对不起,三次密码均输入错误')
a=0
while a<3:
pwd = input('请输入密码')
if pwd == '8888':
print('密码正确')
break
else:
print('密码不正确')
a+=1
else:
print('对不起,三次密码均输入错误')
七、嵌套循环
循环结构中又嵌套了另外的完整循环结构,其中内层循环做为外层循环的循环体执行
#输出一个三行四列的矩形
for i in range(1,4): #行数,执行三次,一次一行
for j in range(1,5):
print('*',end='\t') #末尾换行改为水平制表符,避免换行
print() #打行
*9*9乘法表
for i in range(1,10): #行数
for j in range(1,i+1):
print(j,'*',i,'=',i*j,end='\t')
print()
八、二重循环中的break和continue
用于控制本层循环
for i in range(5):
for j in range(1,11):
if j%2==0:
continue #从step1重新开始循环
print(j,end='\t')
print()
列表


一、列表对象的创建
- 方法一:[ ]
lst1=['hello','world',98]
- 方法二:使用内置函数list
lst2=list(['hello','world',98])
- 列表特点
①列表元素按顺序有序排序
lst=['hello','world',98]
print(lst)
②索引映射唯一个数据
lst=['hello','world',98]
print(lst[0],lst[-3])
③列表可以存储重复数据
lst=['hello','world',98,'hello']
print(lst[0],lst[-4])
二、列表的查询操作
1.获取列表中指定元素的索引——index()
- 如查列表中存在N个相同元素,只返回相同元素中的第一个元素的指引
- 如果查询的元素不在列表中,会抛出ValueError
- 可以在指定的start和stop之间查找
lst=['hello','world',98,'hello']
print(lst.index('hello',0,4))
2.获取单个元素
- 正向索引从0到N-1
- 逆向索引从-N到-1
- 指定索引不存在,抛出IndexError
3.获取多个元素
- 语法结构:
列表名[start:stop:step]

4.列表元素的判断及遍历
①判断-语法结构:
元素 in/not in 列表名
lst=[10,20,'python','hello']
print(10 in lst)
print(100 in lst)
print(10 not in lst)
②遍历-语法结构:
for 迭代变量 in 列表名
for item in lst:
print(item)
三、列表元素的增加
1.append()
在列表的末尾添加一个元素
lst=[10,20,30]
print('添加元素之前',lst,id(lst))
lst.append(100)
print('添加元素之后',lst,id(lst))
2.extend()
在列表的末尾至少添加一个元素
lst2=['hello','world']
lst.extend(lst)
print(lst)
3.insert()
在列表的任意位置添加一个元素
lst.insert(1,90)
print(lst)
4.切片
在列表的任意位置至少添加一个元素
lst3=[True,False,'hello']
lst[1:]=lst3
print(lst)
四、列表元素的删除
1.remove()
一次删除一个元素,重复元素只删除第一个
lst=[10,20,30,40,50,60,30]
lst.remove(30)
print(lst)
2.pop()
删除一个指定索引位置上的元素,不指定索引则删除列表最后一个元素
lst.pop(1)
print(lst)
3.切片
一次至少删除一个元素(会产生一个新的列表对象)
new_list=lst[1:3]
print('原列表',lst)
print('切片后的列表',new_list)
4.clear()
清空列表
lst.clear()
print(lst)
5.del
删除列表
del lst
五、列表元素的修改
1.为指定索引的元素赋予一个新值
lst=[10,20,30,40]
lst[2]=100
print(lst)
2.为指定的切片赋予一个新值
lst[1:3]=[300,400,500,600]
print(lst)
六、列表元素的排序
1.方法一:调用sort(),列中所有元素默认按照从小到大顺序(升序)排序,可以指定reverse=True进行降序排序
lst=[20,40,10,98,54]
print('排序前的列表',lst)
#开始排序,默认升序
lst.sort()
print('排序后的列表',lst,id(lst))
#通过指定关键字参数,将列表元素降序排序
lst.sort(reverse=True) #T:降序;F:升序
print(lst)
2.方法二:调用内置函数sorted(),可以指定reverse=True进行降序排序。该方法会产生新的列表对象,原列表不变
lst=[20,40,10,98,54]
print('原列表',lst)
#开始排序,默认升序
new_list=sorted(lst)
print(lst)
print(new_list)
#通过指定关键字参数,将列表元素降序排序
desc_list=sorted(lst,reverse=True)
print(desc_list)
七、列表生成式
- 语法格式:
[i*i for i in range(1,10)]
(i*i→表示列元素的表达式
i→自定义变量
range(1,10)→可迭代对象)
lst=[i*2 for i in range(1,11)]
print(lst)
#输出[2,4,6,8,10]
字典
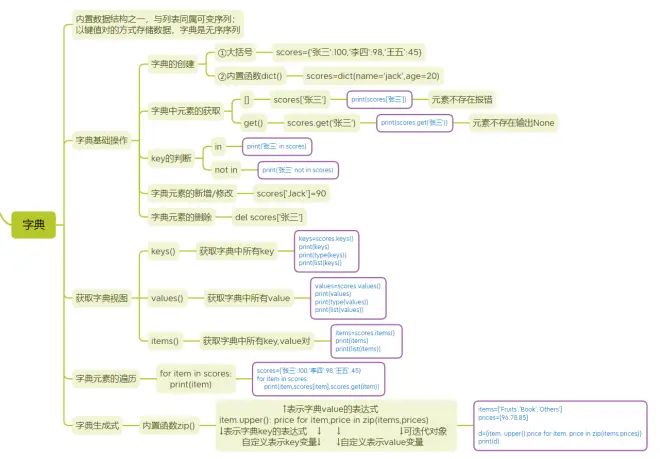
- 内置数据结构之一,与列表同属可变序列;
- 以键值对的方式存储数据,字典是无序序列
一、字典基础操作
1.字典的创建
①大括号{}
scores={'张三':100,'李四':98,'王五':45}
②内置函数dict()
scores=dict(name='jack',age=20)
2.字典中元素的获取
①[]
scores['张三']
print(scores['张三'])
(元素不存在将报错)
②get()
scores.get('张三')
print(scores.get('张三'))
(元素不存在将输出None)
3.key的判断
①in
print('张三' in scores)
②not in
print('张三' not in scores)
4.字典元素的新增/修改
scores['Jack']=90
5.字典元素的删除
del scores['张三']
二、获取字典视图
1.keys()
- 获取字典中所有key
keys=scores.keys()
print(keys)
print(type(keys))
print(list(keys))
2.values()
- 获取字典中所有value
values=scores.values()
print(values)
print(type(values))
print(list(values))
3.items()
- 获取字典中所有key,value对
items=scores.items()
print(items)
print(list(items))
三、字典元素的遍历
- for item in scores:
print(item)
scores={'张三':100,'李四':98,'王五':45}
for item in scores:
print(item,scores[item],scores.get(item))
四、字典生成式
- 内置函数zip()
- item.upper(): price for item,price in zip(items,prices)
items=['Fruits','Book','Others']
prices=[96,78,85]
d={item. upper():price for item, price in zip(items,prices)}
print(d)
元组
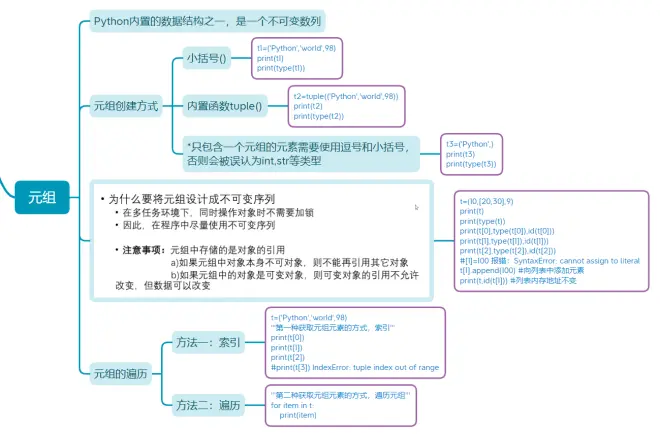
- Python内置的数据结构之一,是一个不可变数列
一、元组创建方式
1.小括号()
t1=('Python','world',98)
print(t1)
print(type(t1))
2.内置函数tuple()
t2=tuple(('Python','world',98))
print(t2)
print(type(t2))
- 只包含一个元组的元素需要使用逗号和小括号,否则会被误认为int,str等类型
t3=('Python',)
print(t3)
print(type(t3))
二、元组对象是否可以引用
- 若元组中的对象本身是不可变对象,则不能再引用其他对象
- 若元组中的对象本身是可变对象,则可变对象的引用不允许改变,但数据可以改变
t=(10,[20,30],9)
print(t)
print(type(t))
print(t[0],type(t[0]),id(t[0]))
print(t[1],type(t[1]),id(t[1]))
print(t[2],type(t[2]),id(t[2]))
#[1]=100 报错:SyntaxError: cannot assign to literal
t[1].append(100) #向列表中添加元素
print(t,id(t[1])) #列表内存地址不变
三、元组的遍历
1.方法一:索引
t=('Python','world',98)
'''第一种获取元组元素的方式,索引'''
print(t[0])
print(t[1])
print(t[2])
#print(t[3]) IndexError: tuple index out of range
2.方法二:遍历
'''第二种获取元组元素的方式,遍历元组'''
for item in t:
print(item)
集合


一、集合的创建
1.使用{}
s={2,3,4,5,5,6,7,7}
print(s) #不允许重复
2.使用内置函数set()
s1=set(range(6))
print(s1,type(s1))
s2=set([1,2,4,5,5,5,6,6])
print(s2,type(s2))
s3=set((1,2,4,4,5,65)) #集合中的元素是无序的
print(s3,type(s3))
s4=set('Python')
print(s4,type(s4))
二、集合基础操作
1.判断
①in/not in
s={10,20,30,405,60}
print(10 in s)
print(100 in s)
print(50 not in s)
2.新增
①add()
s.add(80)
print(s)
②update()
s.update({200,400,300})
print(s)
s.update([100,123,456])
s.update((12,52,48))
print(s)
3.删除
①remove()
一次删除一个指定元素,若指定元素不存在抛出KeyError
②discard()
一次删除一个指定元素,若指定元素不存在不抛异常
③pop()
一次删除一个任意元素
④clear()
清空集合
三、集合间关系判断
1.是否相等
- ==/!=
s={10,20,30,40}
s1={30,40,20,10}
print(s==s1) #True
print(s!=s1) #False
2.一个集合是否为另一个集合的子集
- issubset
s1={10,20,30,40,50,60}
s2={10,20,30,40}
s3={10,20,90}
print(s2.issubset(s1)) #True
print(s3.issubset(s1)) #False
3.一个集合是否为另一个集合的超集(母集)
- issuperset
print(s1.issuperset(s2)) #True
print(s1.issuperset(s3)) #False
4.两个集合是否没有交集
- isdisjioint
print(s2.isdisjoint(s3)) #False
s4={100,200,300}
print(s2.isdisjoint(s4)) #True
四、集合的数学操作
- 示意图

1.交集
- intersection / &
s1={10,20,30,40}
s2={20,30,40,50,60}
print(s1.intersection(s2))
print(s1 & s2)
2.并集
- union / |
print(s1.union(s2))
print(s1 | s2) #union=|
print(s1)
print(s2)
3.差集
- difference / -
print(s1.difference(s2))
print(s1-s2) #difference=-
print(s1)
print(s2)
4.对称差集
- symmetric_difference / ^
print(s1.symmetric_difference(s2))
print(s1^s2) #symmetric_difference=^
五、集合生成式
- {i*i for i in range()}
- 将列表生成式中的[]改为{}即可
#列表生成式
lst=[i*i for i in range(10)]
print(lst)
#集合生成式
lst={i*i for i in range(10)}
print(lst)
字符串



一、字符串的创建与滞留机制
- 驻留机制的几种情况:
1.字符串长度为0或1时
2.符合标识符的字符串(字母、数字、下划线)
3.字符串只在编译时驻留,运行时不会
4.[-5,256]之间的整数数字
二、字符串常用操作
1.查询
①index()
查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError
s='hello,hello'
print(s.index('lo')) #3
print(s.find('lo')) #3
print(s.rindex('lo')) #9
print(s.rfind('lo')) #9
②rindex()
查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError
③find()
查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1
④rfind()
查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1
2.大小写转换
①upper()
把字符串中所有字符转成大写字母
s='hello,python'
a=s.upper() #转成大写后,会产生一个新的字符串对象
print(a,id(a))
print(s,id(s))
②lower()
把字符串中所有字符转成小写字母
b=s.lower() #转成小写后,会产生一个新的字符串对象
print(b,id(b))
print(s,id(s))
print(b==s)
print(b is s) #False
③swapcase()
把字符串中所有大写字母转成小写字母,小写字母转成大写字母
s2='hello,Python'
print(s2.swapcase())
④capitalize()
把第一个字符转换为大写,把其余字符转成小写字母
print(s2.capitalize())
⑤title()
把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写
print(s2.title())
3.对齐
①center()
居中对齐,第一个参数指定宽度,第二个参数指定填充符,第二个参数可选,默认空格,如果设置宽度小于实际宽度则返回原字符串
s='hello,Python'
print(s.center(20,'*'))
②ljust()
左对齐,第一个参数指定宽度,第二个参数指定填充符,第二个参数可选,默认空格,如果设置宽度小于实际宽度则返回原字符串
print(s.ljust(20,'*'))
print(s.ljust(10))
③rjust()
右对齐,第一个参数指定宽度,第二个参数指定填充符,第二个参数可选,默认空格,如果设置宽度小于实际宽度则返回原字符串
print(s.rjust(20,'*'))
print(s.rjust(10))
④zfill()
右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于字符串的长度,则返回字符串本身
print(s.zfill(20))
print(s.zfill(10))
print('-8910'.zfill(8))
4.劈分
①split()
- 从字符串的左边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表
- 以通过参数sep指定劈分字符串是的劈分符
- 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独做为一部分
s='hello world Python'
lst=s.split()
print(lst) #未指定劈分字符,默认空格
s1='hello|world|Python'
print(s1.split(sep='|'))
print(s1.split(sep='|',maxsplit=1))
②rsplit()
- 从字符串的右边开始劈分,默认的劈分字符是空格字符串,返回的值都是一个列表
- 以通过参数sep指定劈分字符串是的劈分符
- 通过参数maxsplit指定劈分字符串时的最大劈分次数,在经过最大次劈分之后,剩余的子串会单独做为一部分
print(s.rsplit())
print(s1.rsplit(sep='|'))
print(s1.rsplit(sep='|',maxsplit=1)) #产生区别
5.判断
①isidentifier()
判断指定的字符串是不是合法的标识符
②isspace()
判断指定的字符串是否全部由空白字符组成(回车、换行,水平制表符)
③isalpha()
判断指定的字符串是否全部由字母组成
④isdecimal()
判断指定字符串是否全部由十进制的数字组成
⑤isnumeric()
判断指定的字符串是否全部由数字组成
⑥isalnum()
判断指定字符串是否全部由字母和数字组成
6.替换
- replace()
第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数
s='hello,Python'
print(s.replace('python','Java'))
s1='hello,Python,Python,Python'
print(s1.replace('Python','Java',2))
7.合并
- join()
将列表或元组中的字符串合并成一个字符串
lst=['hello','java','Python']
print('|'.join(lst))
print(''.join(lst))
t=('hello','Java','Python')
print(''.join(t))
print('*'.join('Python'))
三、字符串的比较操作
- 运算符:>,>=,<,<=,==,!=
- 比较规则
首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较
- 比较原理
两上字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。与内置函数ord对应的是内置函数chr调用内置函数chr时指定ordinal value可以得到其对应的字符
print('apple'>'app')
print('apple'>'banana')
print(ord('a'),ord('b'))
print(chr(97),chr(98))
四、字符串的切片操作
- 字符串是不可变类型;不具备增删改等操作;切片操作将产生新的对象

s='hello,Python'
s1=s[:5] #未指定起始位置,从0开始切
s2=s[6:] #未指定结束位置,切到字符串最后一个元素
s3='!'
newstr=s1+s3+s2
print(s1)
print(s2)
print(newstr)
print(id(s))
print(id(s1))
print(id(s2))
print(id(newstr))
print(s[1:5:1]) #从1开始截到5(不含5),步长1(0→)
print(s[::-1]) #从字符串最后一个元素开始(←-1)
五、格式化字符串
1.%作占位符

name='张三'
age=20
print('我叫%s,今年%d岁' % (name,age))
2.{}作占位符

print('我叫{0},今年{1}岁'.format(name,age))
3.f-string
print(f'我叫{name},今年{age}岁')
print('%10d' % 99) #10表示的是宽度
print('%.3f' % 3.1415926) #.3表示的是精度(小数点后几位)
print('%10.3f' % 3.1415926) #同时表示宽度和精度
print('{0:.3}'.format(3.1415926)) #此处.3表示一共三位有效数字
print('{0:.3f}'.format(3.1415926)) #此处,.3f表示小数点后三位
print('{:.3f}'.format(3.1415926)) #0表示占位符顺序,可省略
六、字符串的编码转换
- 编码:将字符串转换为二进制数据(bytes)
- 解码:将bytes类型的数据转换成字符串类型

s='天涯共此时'
#编码
print(s.encode(encoding='GBK')) #在GBK这种编码格中,一个中文占两个字节
print(s.encode(encoding='UTF-8')) #在UFT-8这种编码格式中,一个中文占三个字节
#解码
byte=s.encode(encoding='GBK')
print(byte.decode(encoding='GBK'))
函数
一、函数的创建与调用
1.创建
def 函数名([输入参数])
函数体
[return xxx]

2.调用
函数名([实际参数])
result=calc(10,20)
print(result)
def calc(a,b):
c=a+b
return c
result=calc(10,20)
print(result)
二、函数调用的参数传递
1.位置实参
根据形参对应的位置进行实参传递

def calc(a,b):
#a,b称为形式参数,简称形参,位置在函数的定义处
c=a+b
return c
result=calc(10,20)
#10,20称为实际参数的值,简称实参,位置在函数的调用处
print(result)
2.关键字实参
根据形参名称进行实参传递
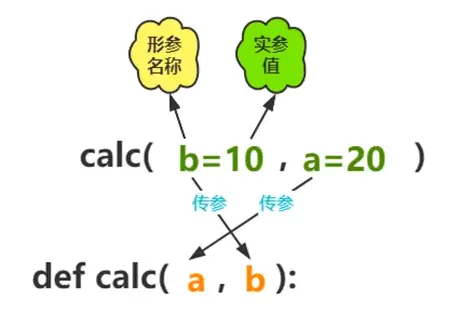
res=calc(b=10,a=20)
print(res)
三、函数参数传递的内存分析
在函数调用过程中,进行参数的传递:
- 如果是不可变对象,在函数体的修改不会影响实参的值
- 如果是可变对象,在函数体内的修改会影响到实参的值
#函数的定义
def fun(arg1,arg2): #形参
print('arg1=',arg1)
print('arg2=',arg2)
arg1=100
arg2.append(10)
print('arg1=',arg1)
print('arg2=', arg2)
#函数的调用
n1=11 #实参
n2=[22,33,44]
fun(n1,n2) #位置传参,形参与实参名称不一致,按从左到右位置传参
print('n1=',n1)
print('n2=',n2)
