
MySQL_基础+高级篇- 数据库 -sql -mysql教程_mysql视频_

有bug。视频标识有时是不对应的。

MySQL数据库管理软件(开源)

重要性

内存 - 易失性

文件 - 大量、不易查询
=>DB管理系统 - 软件

数据库管理系统 安装

DB(数据库database):
存储数据的“仓库”。它保存了一系列有组织的数据。
DBMS(数据库管理系统Database Management System):
数据库是通过DBMS创建和操作的容器。
SQL(结构化查询语言Structure Language):
专门用来与数据库通信的语言。
管理系统听得懂的语言

DBA管理数据库的员工

总结
数据库的好处
1 持久化数据到本地
2 可以实现结构化查询,方便管理
数据库相关概念
DB:数据库,保存一组有组织的数据的容器
DBMS:数据库管理系统,又称为数据库软件(产品),用于管理DB中的数据
SQL:结构化查询语言,用于和DBMS通信的语言
如何存储数据?


一般的安装 是 安装数据库的服务端



删除残留文件


清理注册表


开发机占的内存小


Data - 文件目录
配置完成后
服务需要重新启动
开机自启 -> 手动


简写


如何输入SQL命令的
show database;

MySQL自带的四个数据库
information_schema用于 保存 源数据信息
performance_schema用于 搜集 性能信息
test代表一种测试数据库
use
show

select

create
desc

看数据select * from DB

insert

update

delete

查看当前数据库的版本
select version();
mysql --version
mysql -V


软件 会 自动规划

通过 root用户 连接到 本机


每行命令 加 分号

DQL查询
DML增删改
DDL库和表的定义
TCL事务控制语言

合法的 可以直接执行的


字段



在做查询之前 use DB;



特殊情况




连接




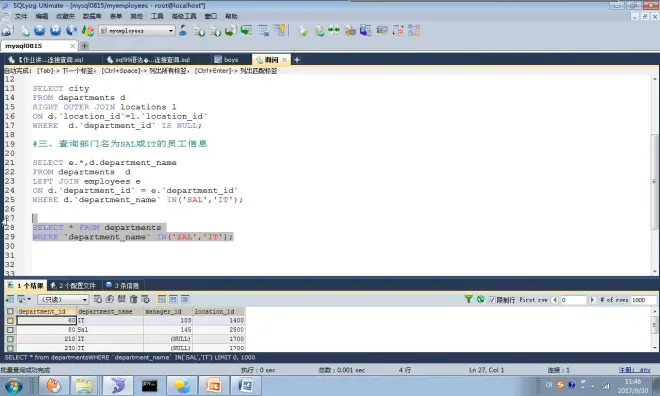
要查谁,就加谁
怎么判断?“的”后面的

员工信息 *



使用转义符 \

指定转义符 ESCAPE




③不支持通配符

有可能出现的值 都放在()里

等价关系



IS要和NULL搭配

判断NULL值

判断普通值

缺点
可读性差
区分




and 可能不一样
or 一样

使用like %%无法查出 NULL 的记录
正确处理的方式是 拼接SQL
拼接 sql 需要先定义 初始化sql where “1=1”
拼接:where += ......;














排序


DESC 降序
ASC 升序 默认


可以按照 别名 进行排序

整体
局部 降序




常见函数 - 类似Java的方法


单行函数 可分为

length 用于 获取数值的字节个数
utf
一个字母一个字节
一个汉字三个字节
jdk
一个汉字两个字节

concat 拼接字符串

upper、lower 大小写

substr、substring 索引


instr 返回起始索引

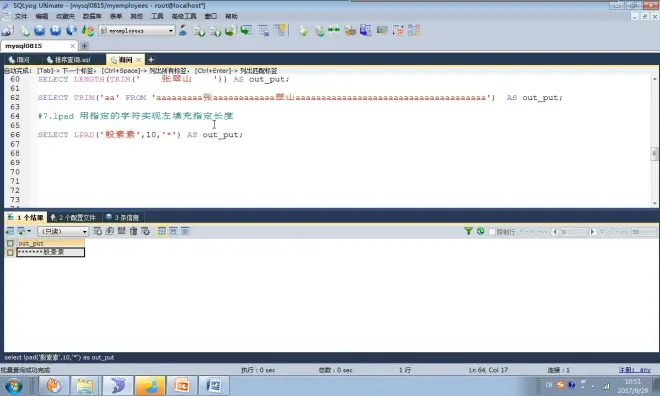
trim 去前后空格

lpad、rpad

replace

round
四舍五入
加绝对值,再加正负号

ceil
向上取整
floor
向下取整

truncate
截断

⭐mod
取余









⭐case




不是=
而是<、>的情况





分组函数 - 统计使用


搭配使用
如:round 保留小数






效率
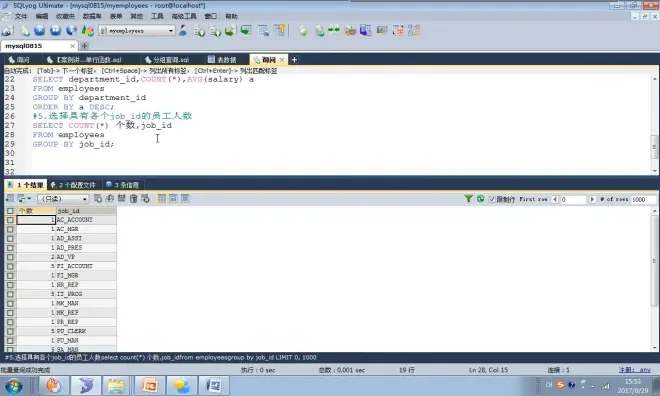
一般使用 count(*);
统计行数




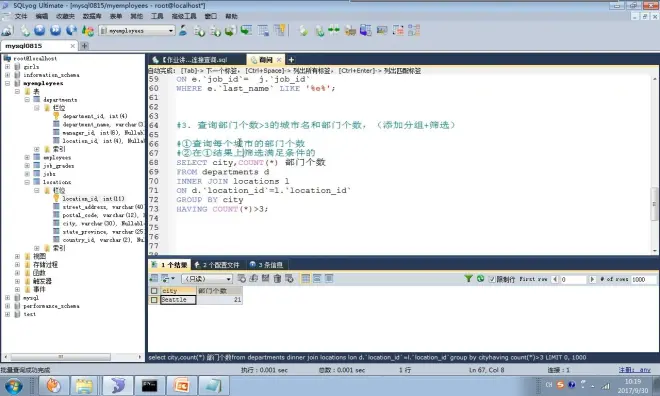
分组查询








筛选

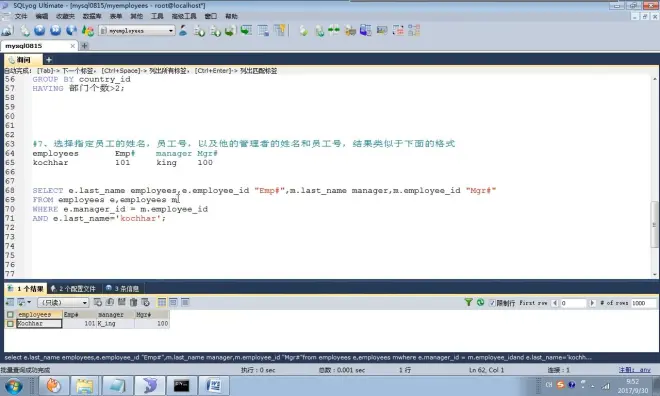
案例3



group by可以放什么




各个、每个
连接查询

笛卡尔积

连接条件

表名限定


案例1 - 等值连接
第一张表 匹配 第二张表
筛选

案例2
筛选


起别名
两个表的顺序是否可变? - 可以

4 是否可以加筛选
WHERE
AND
案例1

案例2

5 是否可以加分组
案例1


因为两个表里都有departmentID 所以要区分一下

6 可以加排序? √
案例

7 三表连接? √

总结

非等值连接

自连接(找自己) = 等值连接

把 原来的表 当成 两张,甚至 更多的表



排序查询

常见函数
字符函数

数字函数
日期函数

其他函数

流程控制函数

多重 if 实现区间判断

分组函数
分类

特点


统计 案例

count(1):统计是1的行数

分组查询

特点

连接查询


等值连接


非等值连接

自连接 - 表1、表2 都是一张表






SQL99


表 交换位置 查询结果一样





两个表的关联列 类型 最好一样,或者可以隐形的转换

分组 + 筛选
排序


三表连接

有顺序:有连接条件





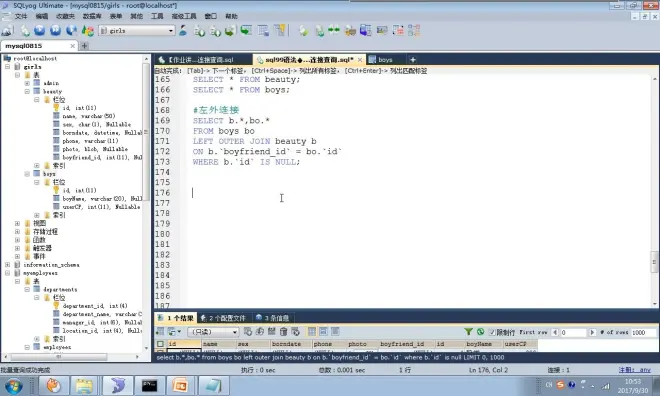
外连接





左外连接


全外 是 三部分组成


cross join

⭐





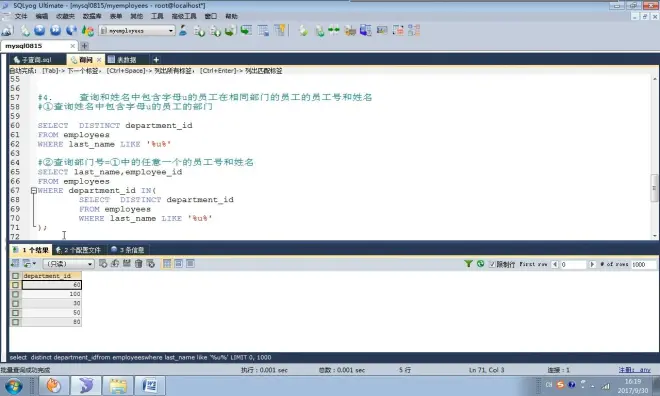
子查询



案例1

案例2


一个查询里可以放两个子查询

案例3 - 分组函数


案例4 - HAVING

子查询


筛选


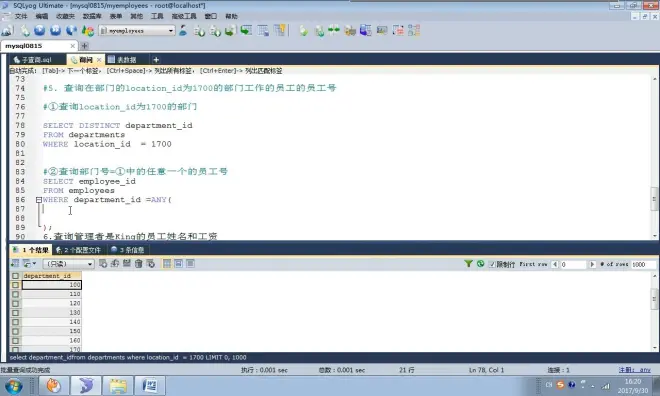
any任意一个
all所有
列子查询 - 单列多行
IN

or
= any,即 等于里面任意一个

案例二


or
小于最大的

案例三

or
小于最小的

行子查询 结果集是 一行多列 或 多行多列
案例一:不一定存在

两个判断条件都是用的 =

or使用行子查询
虚拟字段,多个字段当成一个使用

个数的值 应该对应 部门号


案例2

将 子查询的结果集 充当 数据源 来使用
且必须 起别名 不然找不到

相关子查询









多行的时候使用IN
类似自连接
不知道单行还是多行 使用IN

CONCAT(将多个字符串连接成一个字符串)

⭐分页查询
一页显示不全,需要分页提交sql请求
limit分页递交请求
1-10、11-20...页

【】里的不一定有
【offset】:起始索引
size:要显示的条目个数
执行步骤:
每一步都会生成一个虚拟的结果集

特点

案例



在1的结果上筛选使用having



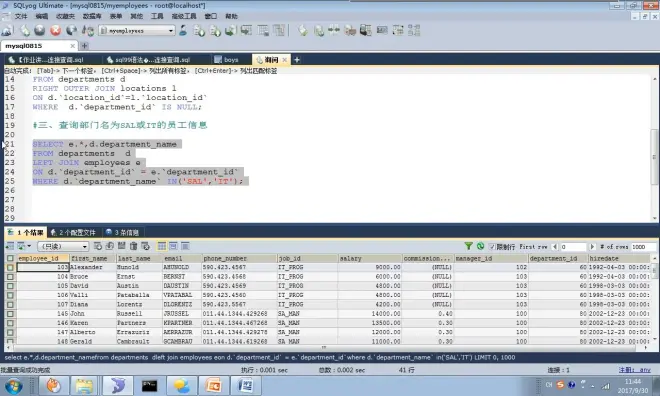
内连接语法

内连接特点

分类

外连接

特点

交叉连接

子查询(逻辑上偏难)


exists
有值返回true,没值返回false


案例 - 标量子查询

案例 - 列子查询

分页查询







方式二
②处没有使用子查询
升序 limit 1 = 最低

平均**最高的##的查询
思路:
先查每个##的信息
再将其作为一个表,进行查询其中最高的
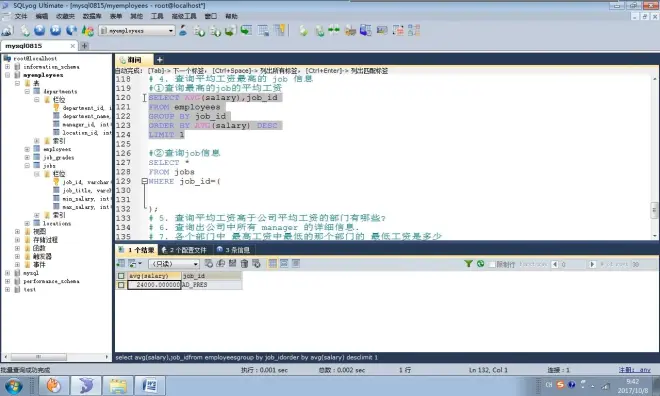







查询的是领导信息






联合查询 union
将多条查询语句的结果合并成一个结果
拆分
目录

没有分号


应用场景:
当 要查询的结果来自多个表
且 表之间没有联系
但 查询的信息一样 的时候
特点
1.要求多条查询语句的查询列数是一致的
2.要求多条查询语句的查询的每一列的类型和顺序最好一致
3.union关键字默认去重,
如果使用union all可以包含重复项
查”每张表“需要的信息


===========================
DML - 数据操作语言
插入:insert
修改:update
删除:delete
-----------------
插入语句
语法:
表已经存在了 - 表名
插入到哪一列 - 列名
insert into 表名(列名,...)
value();
特点
方式一:
1.类型一致

2.不可以为null的列必须插入值
可以为null的列如何插入值?
如果不想插入:
方式一:插入null
方式二:列名和值都不写

3.列的顺序是否可以调换? √

4.列数和值的个数必须一致
bug:列和值不匹配

5.可以省略列名,默认所有列,
而且列的顺序和表中列的顺序一致

方式二:
语法:
insert into 表明
set 列名 = 值,列名 = 值,...

方式一 VS 方式二
1
方式一 支持插入多行。使用逗号分隔
是一条语句,批量插入三行
方式二 不支持插入多行

2.
方式一 支持子查询
方式二 不支持


将select的结果集对应的插入到表里
--------
修改
1.修改单表记录⭐
语法
① update 表名
③ set 列= 新值,列= 新值,...
② where 筛选条件;

2.修改多表的记录【补充】
sql92语法
update 表1 别名,表2 别名
set 列= 值,...
where 连接条件
and 筛选条件;
sql99语法
update 表1 别名
inner / left / right join 表2 别名
on 连接条件
set 列 = 值
where 筛选条件
sql92,sql99里的列都是对应的多表


------
删除
方式一:delete
语法
- 单表的删除⭐
delete from 表名 where 筛选条件

2.多表的删除【补充】
连接
sql92语法
delete 表1的别名,表2的别名
from 表1 别名,表2 别名
where 连接条件
and 筛选条件;
sql99语法
delete 表1的别名,表2的别名
from 表1 别名
inner / left / right join 表2 别名
on 连接条件
where 筛选条件;

两个表都删的 - 级联删除

方式二:truncate - 清空
语法:
truncate table 表名;
不允许加where
什么时候使用?
当要 删除表中所有数据 的时候使用

⭐⭕truncate VS delete
1
delete可以加where条件
truncate不能加
2
truncate删除,效率高
3
如果要删除的表中有自增长列
若 用delete删除后,再插入数据,自增长列的值 从断点开始

而 truncate删除后,再插入数据,自增长列的值 从1开始

4
truncate删除没有返回值

delete删除有返回值

5
truncate删除不能回滚
delete删除可以回滚

1、2

3

方式一:value

方式二:union
insert支持子查询的情况
select可被认为是一条查询语句 - 因为被union合并了

4


5

6

7


8

9

10

==========================
DDL - 数据定义语言
库和表的管理
一、库的管理
创建、修改、删除
二、表的管理
创建、修改、删除
创建:create
修改:alter
删除:drop
一、库的管理
1 库的创建
语法
create database 库名;

默认存储在

2 库的修改

不安全 数据会丢失 - 不再使用
若要修改:
停止服务,修改名称,重新启动

更改库的字符集

3 库的删除

二、表的管理
⭐1 表的创建
语法
create table 表明{
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
列名 列的类型【(长度) 约束】,
...
列名 列的类型【(长度) 约束】
}


2 表的修改
核心语法
ALTER TABLE book CHANGE / MODIFY / ADD / DROP COLUMN 列明 【列类型 约束】;
① 修改列名 CHANGE COLUMN

② 修改列的类型或约束 MODIFY COLUMN

③ 添加列 ADD COLUMN

④ 删除列 DROP COLUMN

⑤ 修改表名 RENAME COLUMN

3 表的删除

通用的写法:
DROP DATABASE IF EXISTS 旧库名;
CREATE DATABASE 新库名;
--------------------------------------------------
DROP TABLE IF EXISTS 旧表名;
CREATE TABLE 表名();
4 表的复制

① 仅仅复制表的结构
- LIKE

② 复制表的结构 + 数据
- SELECY * FROM 表名

只复制部分数据

仅仅复制某些字段
0:false
1:true




跨库 储存表结构




修改类型







==========
数据类型
常见的数据类型 - 对数据的限制

