
PaddleOCR实现批量文件识别和输出(存入Excel)
前言

为找到一款自用的开源OCR,体验百度的PaddleOCR基础功能后,可以满足图片文字识别的需求;本篇总结一些在Windows 10(64位)环境下的使用经验,实现批量文件识别和输出(存入Excel)。
PaddeOCR安装
登陆官网(https://www.paddlepaddle.org.cn),进入相应页面查看安装教程,按操作说明安装部署PaddleOCR(需要python环境),本篇不作介绍。
修改说明
PaddleOCR安装部署完成后,可以使用教程中的脚本运行,对一个指定的图片进行文字识别,并生成一个新图片,该图片包含识别结果和说明。

所以按教程的脚本使用,无法直接使用提取出的文字(因为包含在图片中);其次每次运行只操作一个文件,不够效率。基于以上两个原因,需要我们自己修改来实现以下效果:
(1)启动OCR
每次要运行教程脚本,需要先打开命令行,进入anaconda3的PaddleOCR环境(教程推荐使用anaconda3),再用python运行.py教程脚本;所以将以上过程编辑为.bat文件,双击运行就可以简化以上重复步骤。
(2)文件批量操作
教程脚本代码只执行一次文件操作,所以修改代码使其对文件批量操作。
(3)将所有结果输出至Excel
修改教程脚本代码,使输出结果(文字部分)存入Excel,方便使用。
具体操作
(1)编辑启动脚本
新建一个txt文件,并写入以下脚本,再修改后缀名为.bat文件。
(2)修改OCR源代码
在PaddleOCR安装目录下,找到并用记事本打开paddleocr.py,修改其中对应的函数,事先备份paddleocr.py。
(3)编辑运行文件
新建一个txt文件,并写入以下脚本,再修改后缀名为.py文件(例:OCRoutput.py),再放入PaddleOCR安装目录下。
(4)使用过程(案例)
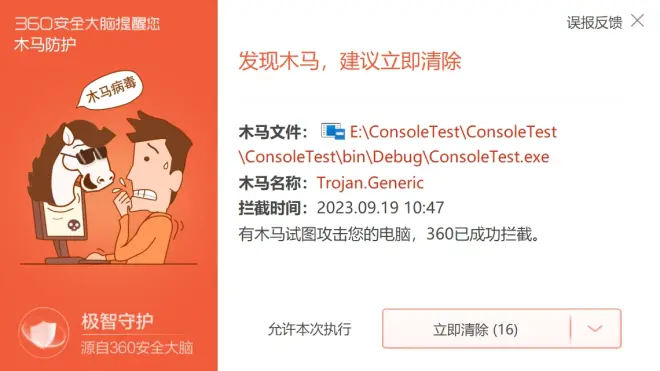
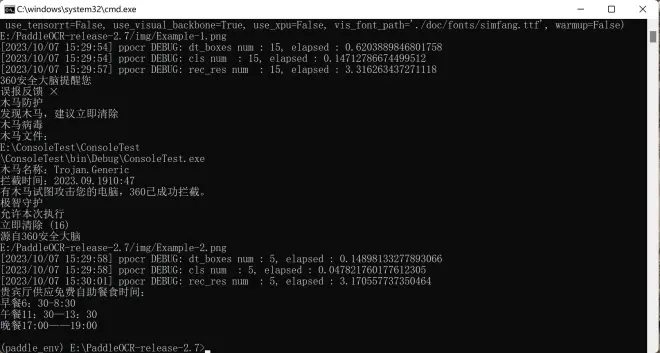
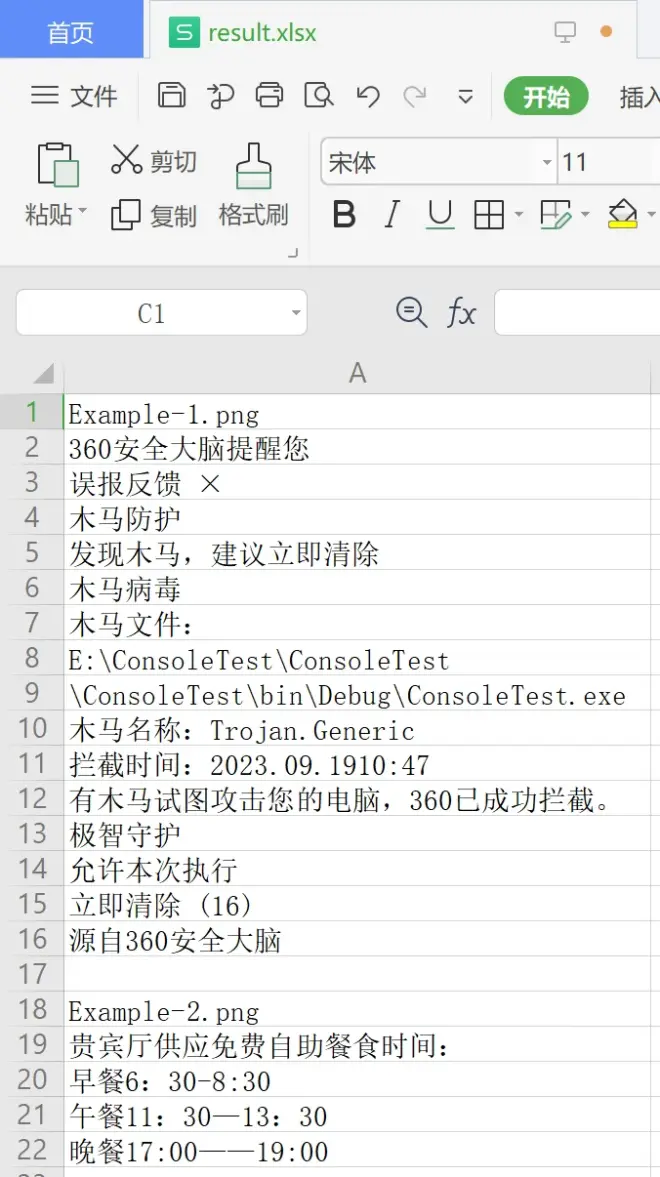
PaddleOCR安装目录下新建的img文件夹,放入2个测试图片:Example-1.png和Example-2.png,运行第一步中的脚本(OCRBat.bat),等待程序运行完,打开result.xlsx确认结果。


总结
本篇仅使用教程中【快速开始】介绍的基础识别功能,还不涉及深度学习和训练等功能,有进一步需求的小伙伴可以继续深入研究和使用。
