
RVC AI翻唱保姆级教程

1.软件准备
首先需要RVC 软件,它是SVC软件的一种,特点就是门槛低效果好,作者是B站的花儿不哭大佬,最新整合包在这里:【AI变声器】RVC AI实时变声器717版,新增GPU系rmvpe算法,胎教级使用教程_哔哩哔哩_bilibili
提醒:RVC软件作为AI翻唱软件的一种,对电脑的配置要求比较高,你的电脑需要是N卡,且显存4GB以上才能顺畅推理(不是模型训练),配置差的朋友也不是没有路可走,可以使用autodl.com这个网站租用显卡,下面会讲使用教程。
然后需要一个人声伴奏分离软件,我使用的是UVR5,当然你使用别的如ripx什么的也没问题。最强伴奏人声提取工具 - 开源免费,一键安装,直接使用!| Ultimate Vocal Remover | UVR5_哔哩哔哩_bilibili
夸克网盘:https://pan.quark.cn/s/816a932fc26c
123云盘:https://www.123pan.com/s/RiyA-Z5U03 提取码:hjhj
人声伴奏得合并对吧,这里使用的是Adobe Audition,也可以用OneStudio等软件做多轨混音。这里Bing一下就容易搞到软件,我就不多赘述了
然后就可以开始了。
2.RVC的Windows本地使用
当你下载好了RVC整合包,将其解压
先别怕,往下翻

如果找不到的话,可以新建一个文本文件,然后键入
并把文件后缀改成.bat运行即可。
如果双击没反应,就把pause删掉试试。
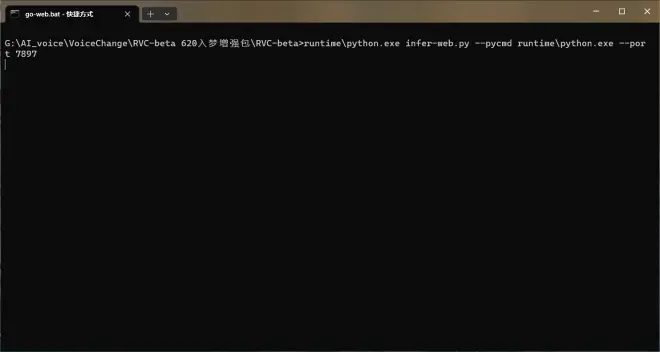
等一会会弹出一个网页,这就是软件的界面,你可以在这边进行模型推理和伴奏人声分离(虽然RVC用的也是UVR,但是独立的UVR软件毕竟模型更多更干净)
1.模型推理
准备好干声文件,选择推理音色(没有模型的话点我动态,置顶有TTF2模型和APEX模型)
模型下载好后放进RVC软件的weights文件夹内(不是UVR_weights)
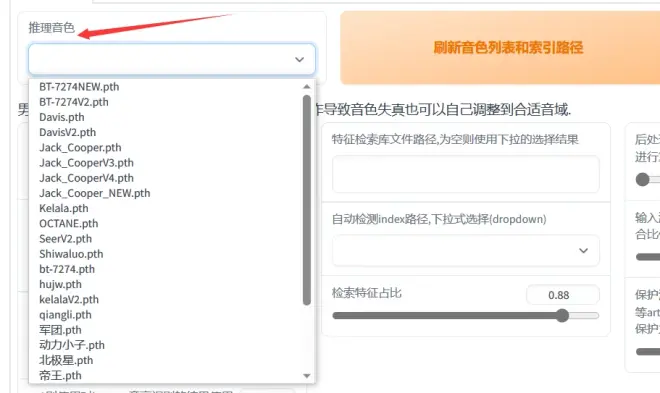
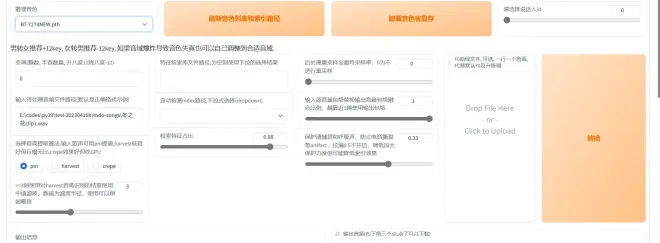
选择好你喜欢的音色后,输入音频完整路径(最好音频文件名字不要带中文,而且包括扩展名一并输入)
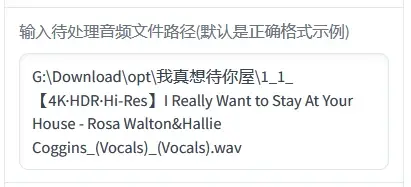
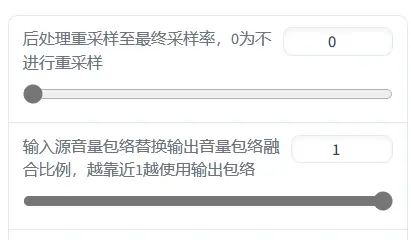
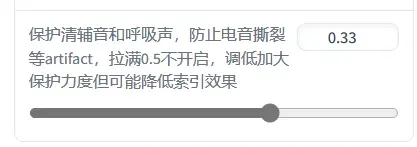
现在讲解一下各个参数什么意思
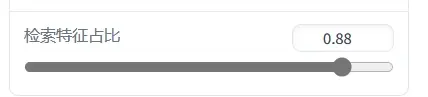
这个值越大转换输出的人声越接近你模型的音色
然后就可以点转换按钮了!
Chromium内核的浏览器应该都能下载吧(如Edge/Chrome)

下载完长这样,记得重命名一下
2.模型训练
注意,模型训练极度吃显存大小,显存8GB以下的就只能观望了(或者云端租用显卡训练)
模型训练,你需要准备模型的训练集,由于目前只支持单人语音训练,训练集要求3分钟以上单人干净的说话语音(不带背景音),训练集可以是多个文件,只要在同一文件夹内即可。
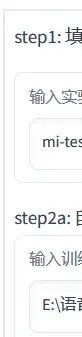
然后打开RVC软件

“实验名”就是模型名字,支持中文。采样率影响不大(主要是对显存占用的影响,咱反正听不出区别),用默认的就好了,V1V2的话我趋向于选择V2,当然也有人说V2不如V1什么的,看你实际效果啦。
他这里有Step 1 2这样的,咱可以不用理step2

由于RVC训练每保存一次模型就会吃1GB左右空间,你可以提高一点保存频率。救救硬盘空间
Epoch我一般是60起步,120左右。
Batch Size指的是AI在学习的过程中一次学习参照的音频文件数量,越大越吃显存,我这里拿云端的3060 12G炼的话batch size选8基本上能吃满
别的软件本身介绍挺详细的,自己看一下应该也懂了。
OK然后点一键训练即可
3.RVC的云端训练(autodl.com)
租显卡嘛,鼠标悬停到用户名上,你就可以看见充值按钮了,先充10块钱试试也行。
(这个平台也是可以让你跑AI绘画的)
充值好后点击算力市场
(炼这个显卡不用多强,显存大就行,所以挑个便宜一点的玩玩就行,3090 1.66元一小时左右。)
这个手速得快,机子得抢的,别愣着。
提醒:别选北京地区的,因为部分原因,你点不开自定义服务,还要端口映射什么的,比较麻烦。
抢完马上选"社区镜像"
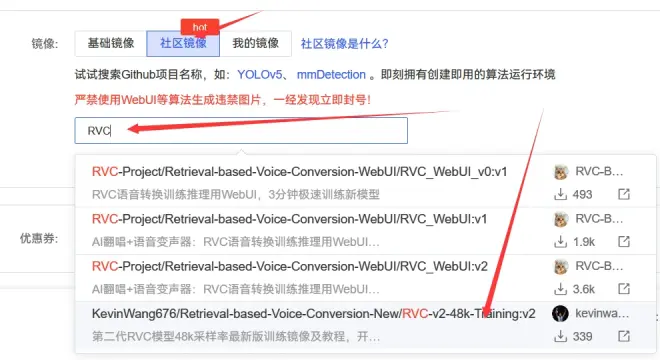
选完点立即创建

点击JupyterLab
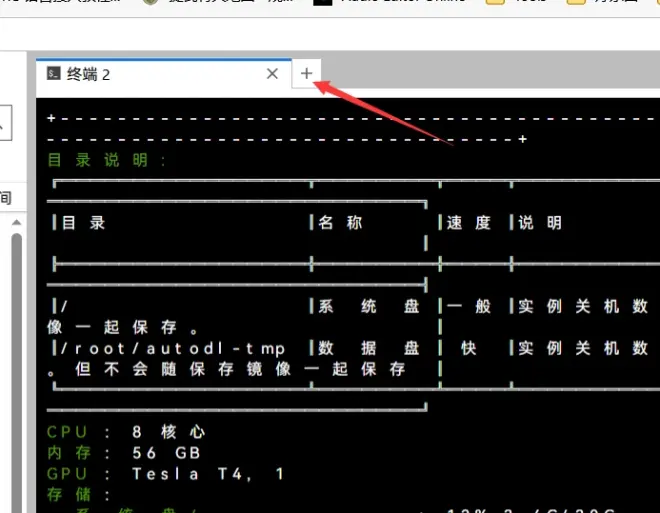
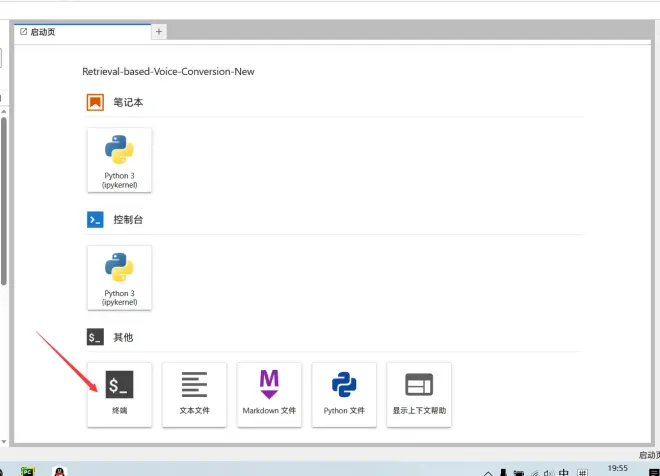
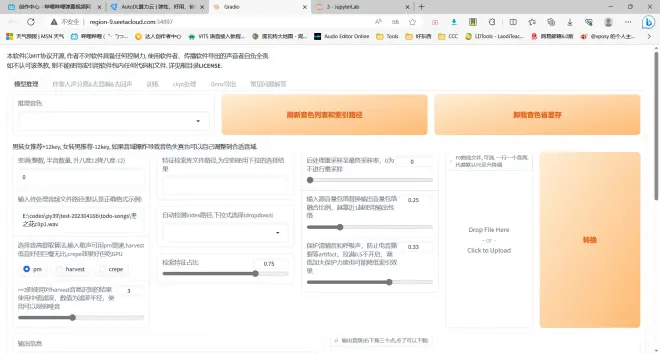
由于它默认的端口号是7865,不是autodl自定义服务的6006,因此我们需要先修改文件
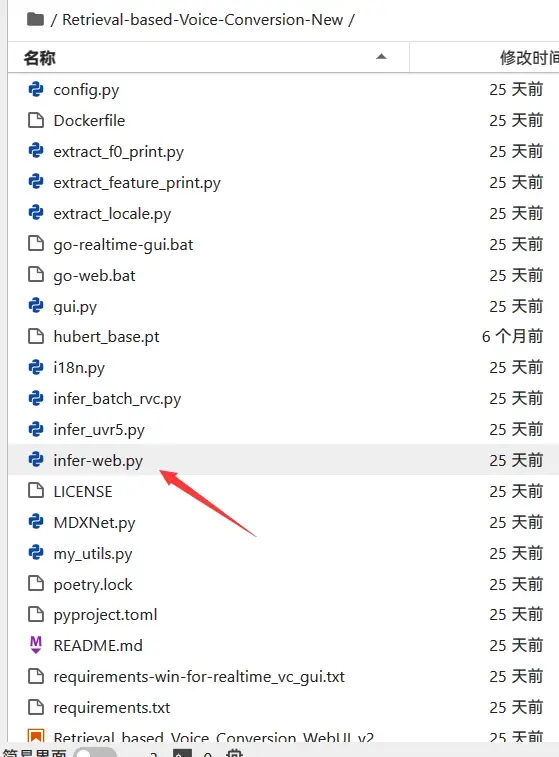
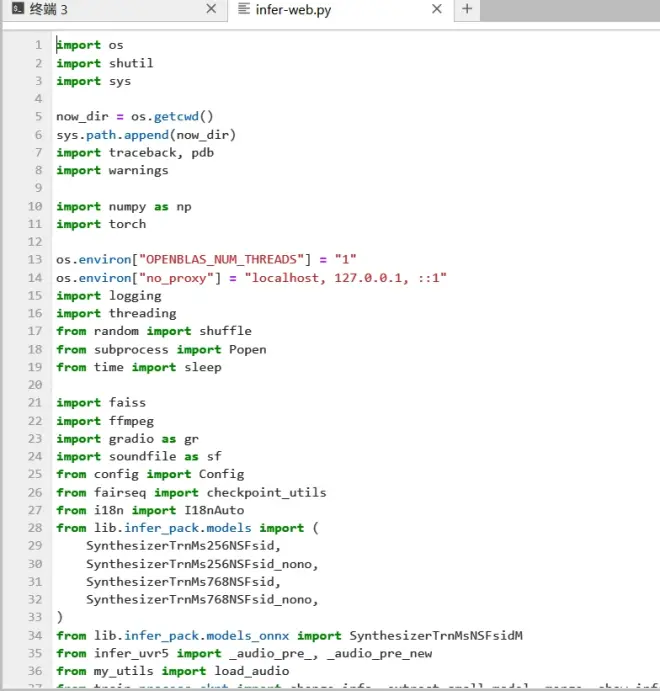
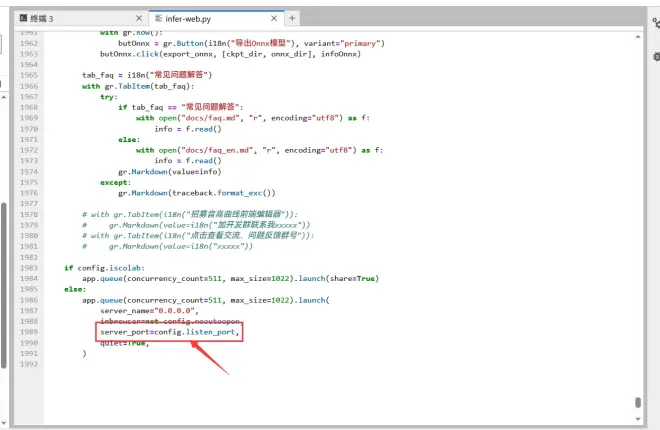

好,现在返回终端



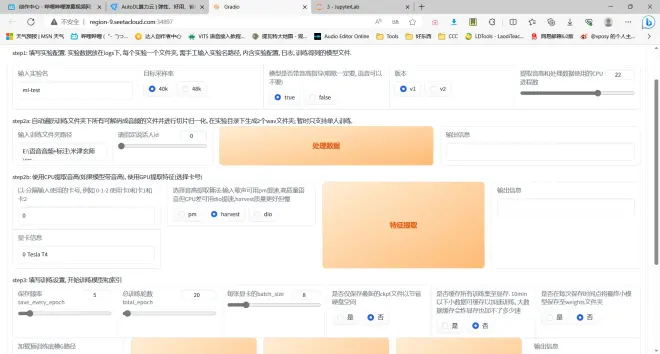
点模型训练
上传训练集:
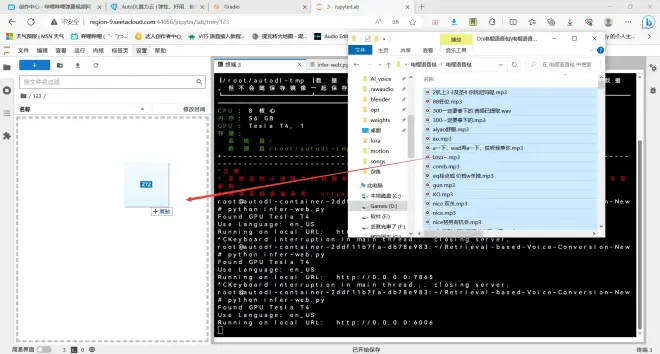
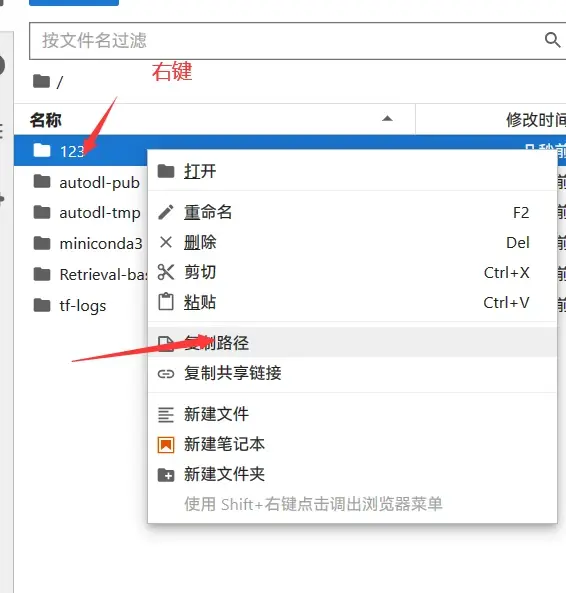
接下来的操作和本地训练没有太大区别,唯一区别是云端是Linux系统,文件路径会有所区别,在JupyterLab里上传好训练集,复制训练集路径
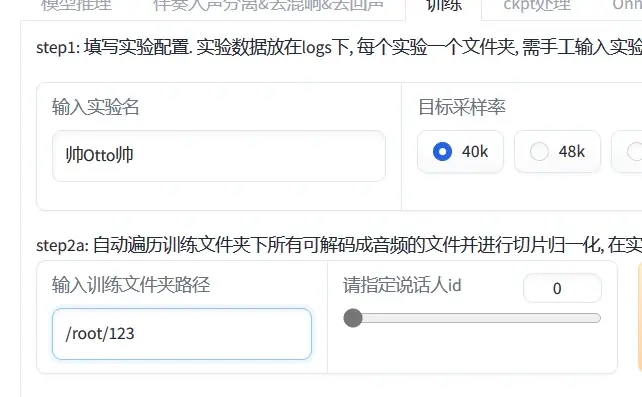
路径前面都要加/root/,不然识别不到,会报错
然后照前面的方式就可以开始训练了
保存模型:
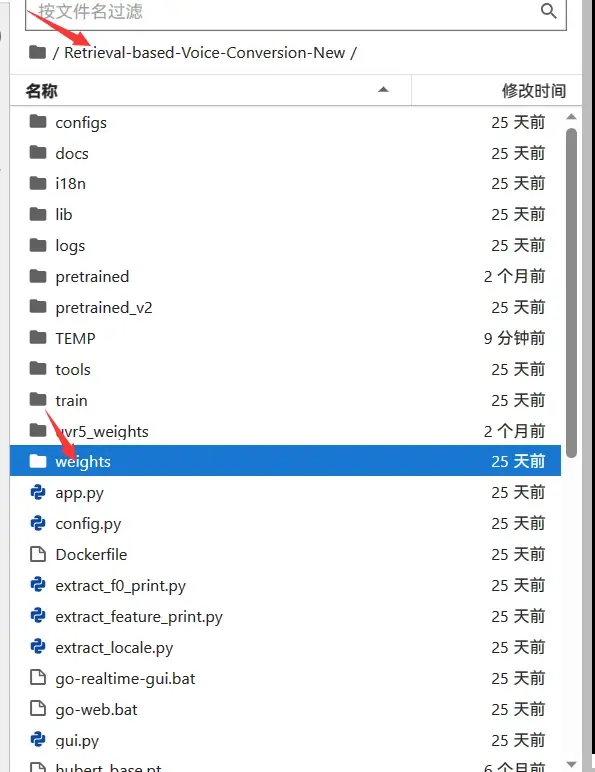
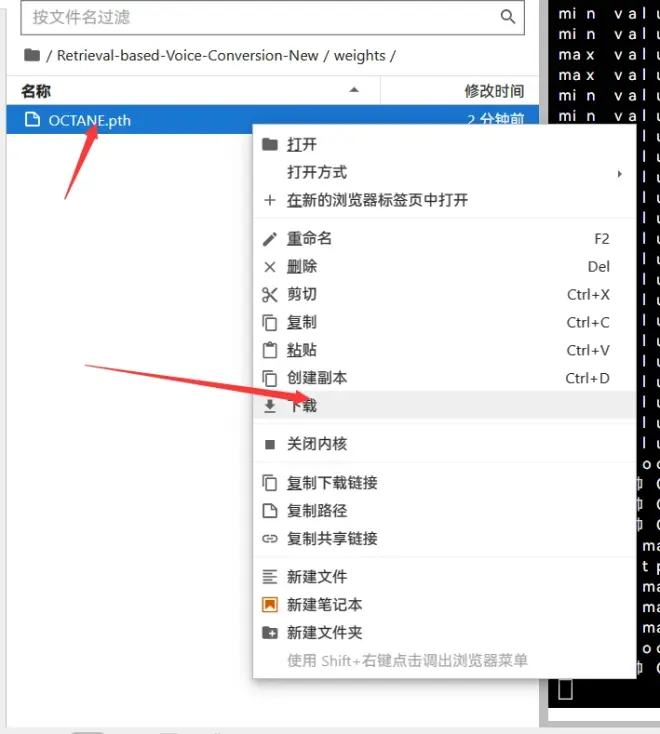
然后把模型pth文件转移到本地的RVC软件的weights文件夹里就行了
4.UVR伴奏人声分离软件的使用

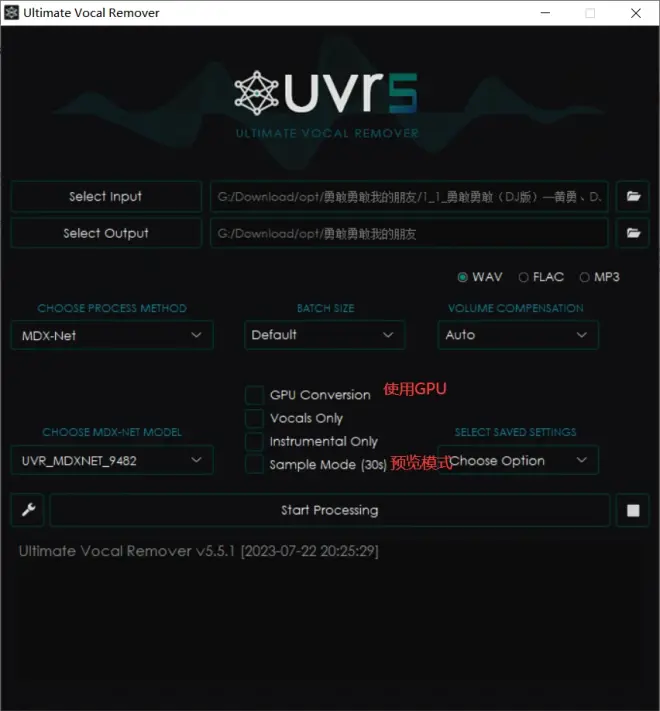
然后拿处理好后的人声
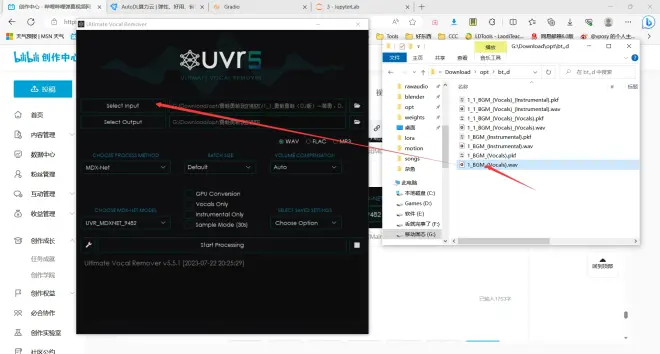
再处理一遍时,需更换模型,我们已经将人声分离出来了,但是人声依旧带和声和混响,这是我们应该去除的。
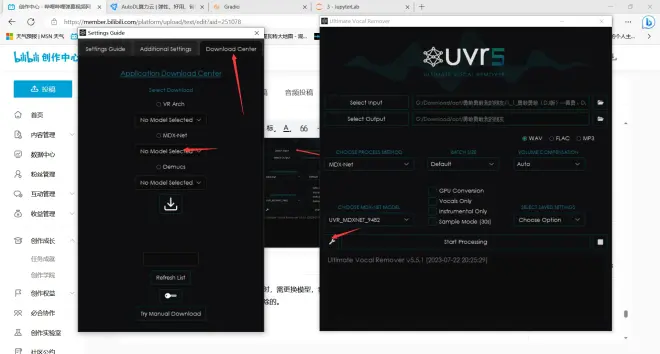
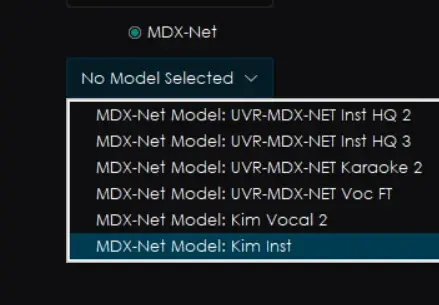
注意:因为我已经下载了Deverb模型所以下载中心中并没有显示MDX-Net Model:Deverb HQ-By FoxJoy,不要下错了
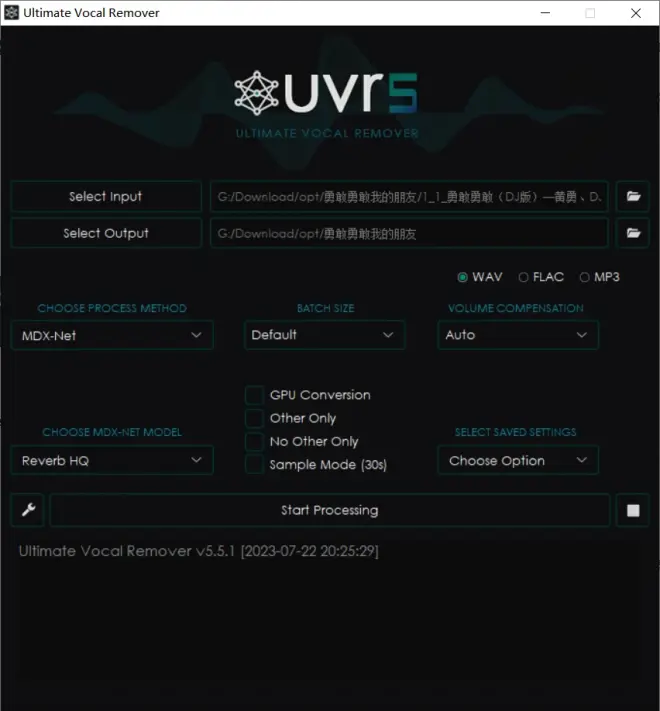
然后再处理一遍,最后拿Karaoke模型再对这种(No Other)后缀的处理一遍


得到最后的干净人声和和声(上面是和声,下面是人声)
然后就可以丢进RVC里面进行推理了。
5.混音
这个可能得看一些教程学Au 不过Au用起来也不难
打开Au
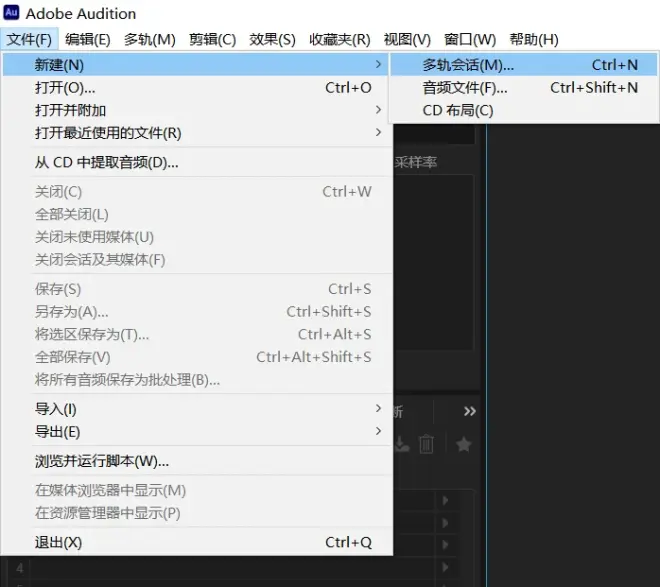
2.
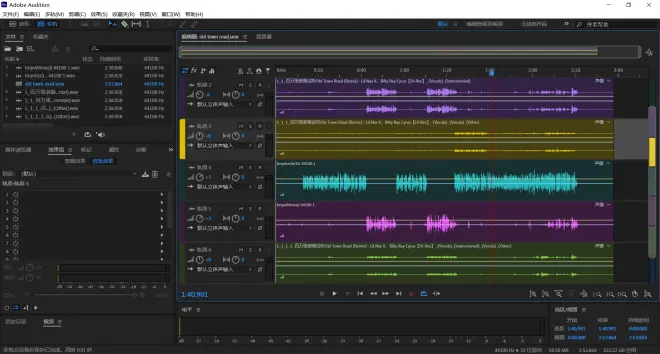
把推理好的人声、伴奏、和声和混响拖进去就行
3.保存文件
选格式、路径导出即可
