
强烈推荐!台大李宏毅自注意力机制和Transformer详解!

Self-attention
对于输入Seg中向量不确定多的情况,Self-attention会考虑所有向量。
(且可以多次交替使用)

Self-attention的输入是一组向量,输出也是一组向量,但考虑了整个seq产生的。步骤如下:
1、判断哪个和a1的关联性
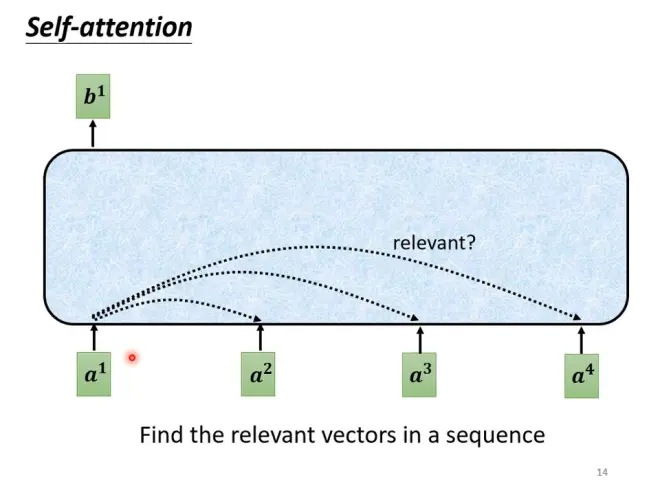
求关联性的方法 点积和相加:

点积法:将两个向量分别乘以权重矩阵,再进行点积。
2、把a1乘以W叫query,把a3-a4乘W叫key,计算出每个的关联性α,再用softmax得到α'。

3、然后再将所有向量v * α,再求和得到b
用矩阵相乘来理解一下:

多头注意力模型
相关有很多种,所以可能不止一个q,不同的q负责不同种类的相关性。有几个q就自然有几个k和v。
以两个head为例:

得到多个b,在将其接起来传到下一层。
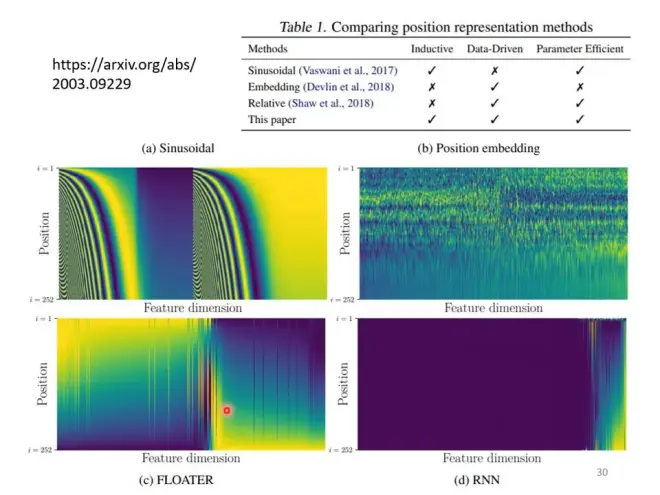
位置编码
没有包含位置信息,但有时位置资讯有时很重要。如第一个词一般不是动词。
所以,给每个位置加一个位置向量e,然后把e加到a上。
最早的论文中用的vector e:

但也可以学出来,如多种e的比较:
语音中使用Attention:
seg很长,而Attention矩阵的大小是L^2。
所以长序列的语音问题,会只取一小个范围。
图像中使用Attention:
把一张图片看做vector set,即1×3向量的集合。
CNN也可以看做一种简化版的self-attention(只考虑感受野内的相关性)。
Self-attention是CNN的广义。Self-attention弹性更大,可以从更大的数据量中得到好处。
Self-Attention vs RNN:

都会把序列扔给FC,Self-Attn考虑了整个Seq,RNN只有左边的,但其实RNN也可以用双向的,即Bi-RNN。
RNN中远距离的信息传递要经过一段时间。且RNN无法并行化,而Self-Attn可以并行处理。
运算速度上Self-Attn大于RNN。
图(Graph)中使用Self-Attetion:
边已经揭示了点的关联性,所以可以选择只计算边的顶点间的关联性。这也是一种GNN的变体。
//疑问:是否可以把注意力层理解为一个具有一定RNN功能的CNN层?
Transformer
一个Seq2Seq模型
输入一个序列,输出一个序列,输入输出序列的长度都不确定,由机器自己决定。
如:语音辨识,机器翻译,语音翻译(有些语言连文字都没有),聊天机器人,甚至文法剖析、多标签分类和目标识别。
如台语语音辨识、合成
硬train一发
大部分NLP都可以看做Seq2Seq。

架构
Encoder 和 Decoder架构
Encoder:给一排向量,输出一排向量
Encoder的一个Block(在自注意力和FC上加了residual,并且使用了layer norm):

更具体地,Encoder的结构:

Decoder:
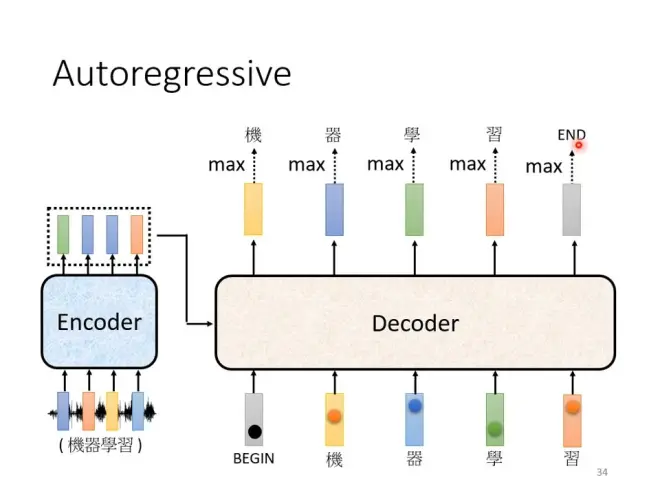
Autoregressive
Decoder会把自己的输出当做下一个输入。输入时加一个BEGIN符号。

Transformer的Decoder和Encoder的差别只在于中间部分,以及最后多了一个Softmax。
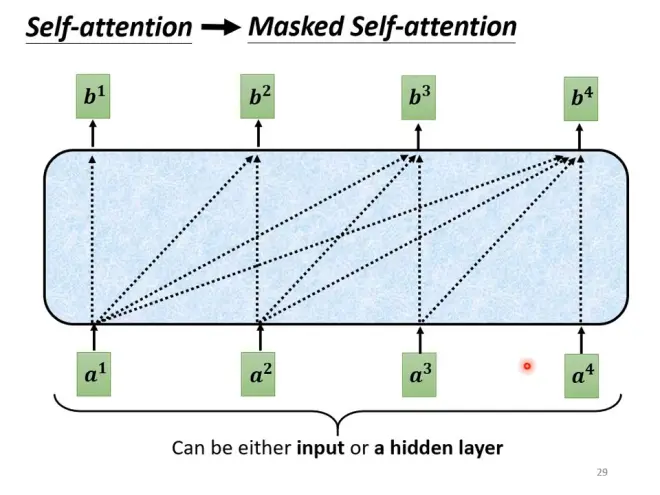
Decoder中的Masked,即在算bi时,不考虑i之后的aj。这样更接近于decoder的运作方式。
decoder如何决定输出序列的长度?
用特殊符号END表示"断"。让机器产生END的概率最大时表示结束。
AT vs NAT
NAT会给多个BEGIN,一次性生成完成完整的句子(注意位置嵌入的作用)。要由特殊方法判断终止。
NAT可以平行化,可以控制输出长度(在语音中可以据此控制说话速度)。但NAT通常不如AT。

Cross attention
decoder产生一个q,去和encoder的输出a'做注意力,结果进入FC。(原论文中decoder中每一层都是用encoder最后一层输出,但也可以变化)

每产生一个字就是从几千个字中进行的分类问题。训练时希望所有的字(含END)的交叉熵最少。
训练decoder时会给正确答案来训练,即teacher forcing。

Copy Mechanism:输出从输入中复制一部分,如聊天机器人、摘要。
Guided Attention:强迫要看到所有输入,要求机器有固定的方式,如训练时Attention必须从左到右。在语音辨识和语音合成中用。
Beam Search:每次找最多的是Greedy Decoding。可能开始选的不好,但是后面很好。Beam Search就是寻找这些路径的方法,但Beam Search有时有用、有时没用,因为有时找出分数最高的路不一定就是最好的,如需要一些创造力、没有单一答案的任务(如故事补全、语音合成,TTS加noise才能产生正常的声音,加入一些随机性反而是人类觉得较好的)
BLEU score:最小化交叉熵 ≠ 最大化BLEU score。但是BLEU无法微分!方法:当遇到无法optimize,就把它当做RL硬做!

训练和测试不一致(Exposure Bias):
一步错步步错
方案是给encoder的输入加一些噪声,称为Scheduled Sampling,在Transformer中为了不伤害其并行性会有一定改变。

