
【实时AI字幕】基于whisper的直播语音转字幕软件的安装与使用
写在前面:
本人非专业程序员,计算机技术为业余爱好。所以文中有关语音识别原理部分恕我无法讲解,只能对软件使用部分提出解决方案,欢迎阅读此篇文章的人提出修改意见。
这篇文章写于2022年10月15日,文中提到的工具还在持续开发中,不保证文章内容一直有效。
推荐直接跳到colab云端运行部分,快速上手体验whisper的神奇

方法简介:
Whisper(https://github.com/openai/whisper)是OpenAi最近公开的一个开源语音识别项目,依靠大量的数据学习有着媲美商业级的音频转录效果。本地化、可调节精度、多语种支持都是它的优点,而且因为主体使用的python也可以直接作为模块导入进行拓展开发,上线不到一个月已经快有上百个相关项目产生了。
Whisper可以用CPU和GPU(CUDA)两种方式来跑模型,具体显存需求可见如下:
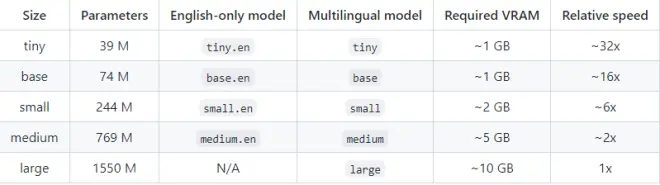
有关whisper的原理讲解可见官方博客:
https://openai.com/blog/whisper/
今天要介绍的stream-translator(https://github.com/fortypercnt/stream-translator)就是基于Whisper和streamlink开发的,可以将直播源导入并实时输出字幕的工具。
安装Whisper:
虽然stream-translator有自动安装whisper的设计,但我还是建议先安装Whisper测试可用,这样会减少很多麻烦。
1、 环境与依赖
Whisper使用python编写,用PyTorch训练模型,转录部分要利用到ffmpeg处理音视频。
所以这部分主要介绍这三个工具的安装,其余依赖numpy、transformers等一般不会有坑,跑官方脚本即可。
Python:
进入下载页(https://www.python.org/downloads/),点击那个大大的黄色按钮Download Python 3.10.8下载并按照步骤安装即可,现在的Python安装已经自带添加到环境变量的功能,安装的时候留意Add Python 3.10.8 to PATH就行。
非windows系统的按照官方的指引界面下载。
在下载过程中速度没速度或者太慢,可以选择国内镜像站,我一般用华为的:
https://repo.huaweicloud.com/python/
不知道下载那个文件可以对比你在官网下载的文件名。
PyTorch:
这里是第一个坑,按照官方的一键安装脚本很可能安装不到正确版本的torch,导致运行时报错或者出现CPU跑冒烟而GPU不工作的情况。
本部分教程来自于:https://github.com/pytorch/pytorch/issues/30664#issuecomment-757431613
如果已经安装了torch,请先卸载掉
清除pip缓存
安装支持CUDA版本的torch
ffmpeg:
官方给出的引导是使用包管理器,windows平台使用的Chocolatey和Scoop。但我实测中发现安装这两个工具的时候出现的问题可能比安装whisper还多,所以我推荐使用传统方式,下载编译好的包并手动设置环境变量。
官方给出的windows下载有两个,以https://www.gyan.dev/ffmpeg/builds/ 为例,找到ffmpeg-release-essentials.zip下载并解压即可,你应该可以在bin文件夹下找到编译好的ffmpeg.exe,如果没有说明你可能下载到了没做编译的开发版。
配置到环境变量这一步可以参考各种其他教学,这里主要说三点容易出问题的步骤。
注意是系统变量里的Path而不是用户变量里的。
文件夹路径要写到文件所在路径,也就是bin文件夹。
环境变量配置好后要重启命令提示符/终端才可生效。
2、 主程序安装
一键安装项目。
安装过程中可能遇到的问题大多都和网络有关,请查阅修复连接github的方法。
或者是在github上选择Download Zip之后,解压运行如下指令手动安装:
如果电脑上使用了代理软件,可以用输入如下配置可以让命令行窗口临时走代理。我用的clash默认端口是7890,读者请根据实际情况修改。
使用Whisper:
whisper提供了两种两种方式:命令行和作为模块在python文件中调用。这里面对非专业读者主要讲一下在命令行的使用。
有关命令行:
windows在项目所在文件夹的地址栏里直接输入cmd,会在当前文件夹下打开命令行
输入部分文件名后可以点击TAB键自动补全
命令行遇到的各种网络问题可以看
指令格式:
常见报错:
UserWarning: FP16 is not supported on CPU; using FP32 instead
这句提示的意思是现在在用CPU跑模型,如果你用的电脑没有显卡或者是显卡不支持CUDA/CUDA版本过低那么这个提示是正常的。否则请返回PyTorch的安装步骤,安装支持CUDA版本的torch。
FileNotFoundError: [WinError 2] The system cannot find the file specified
环境问题调用ffmpeg的部分出错了,可能的原因有两种:
没有安装ffmpeg
没有安装ffmpeg-python
如果已经安装请确认环境变量的配置是否正确,在命令提示符中输入ffmpeg测试一下。
ModuleNotFoundError: No module named 'torch._C'
依旧是PyTorch的问题,卸载重装八成有效
RuntimeError: CUDA out of memory.
你的显卡干不了这么多,换一个小点的模型吧(参考模型与显存需求对照表)
No module named 'setuptools_rust'
按照提示安装就行
stream-translator的使用:
对于完全新手/网络状况一般的朋友,非常推荐在colab云端运行。具体的操作方法我也写在了ipynb文档里,按照步骤进行基本都能运行成功
https://colab.research.google.com/drive/1SEhfzUSm07IUjMd5_HrbmXd9cyh0N-wW?usp=sharing
安装方式:
stream-translator的主要额外依赖是streamlink,此外还有一些优化显示效果的库
使用方法:
优化配置:
如果在国内使用需要设置一下代理,每次配置太过麻烦,可以直接把以下代码加入translator.py文件开头部分
此外有关其他优化可见我ipynb里所写。
需要注意的是,Whisper本身没有提供实时转录的接口,这个工具的实现原理其实是指定秒数的切片并调用Whisper,对上下文调整功能的支持并不算太好。作者的解释见:
https://github.com/openai/whisper/discussions/225
