
[AI对话]懒人包6.19更新(内容过长无法发动态) text-generation-webui

首先声明一点,我不是text-generation-webui的制作者,我只是懒人包制作者。
懒人包V1.5.0更新【6.19】:
1. 更新tgwebui版本,让懒人包支持最新的ggml模型(K_M和K_S等)

2. 增加exllama,一种比AutoGPTQ速度更快(生成速度上)的GPTQ量化模型加载方式。
在colab上使用T4显卡加载13B的4bitGPTQ模型,生成速度在12token/s~20token/s左右。Autodl下使用RTX3090显卡加载13B的4bitGPTQ模型,生成速度在30token/s~40token/s。


不过,目前要使用exllama加载模型的话,需要安装CUDA Toolkit11.7和Visual Studio生成工具(安装时勾选“使用C++的桌面开发”)


https://developer.nvidia.cn/cuda-11-7-0-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local
Visual Studio 生成工具下载:
https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/

启动器V1.8更新 【6.19】:
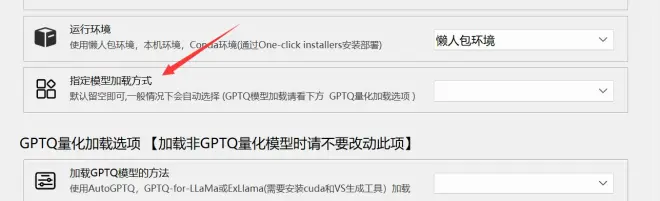
1. 针对--loader参数新增“指定模型加载方式选项”,一般情况下默认留空即可,除非你想要指定加载方式。

2. 新增llama.cpp选项(加载ggml模型),添加GPU加速选项和编译加速按钮。即通过CUBLAS编译的llama.cpp,可以将运算卸载到GPU上,实现GPU加速。

需要注意的是,首次使用该功能前必须先点击“编译加速"按钮,并需要安装Visual Studio生成工具(安装时勾选“使用C++的桌面开发”)
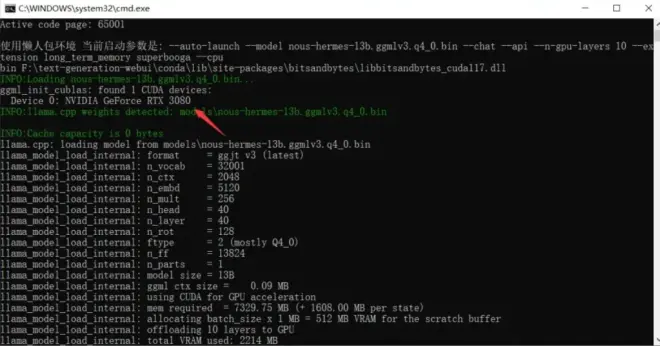
若成功启动GPU加速,会在控制台显示Found X CUDA devices: 你的显卡型号
另外,我发现在加载GPTQ量化模型的情况下,加载lora不止是GPTQ-for-LLaMa,目前三种GPTQ加载方式均可。

