
python实现统计学包Scipy所有语法
本文是基于统计学理论和scipy实践完成,是对统计学基本概念的讲解。我试图以一种有趣且互动的方式来呈现这些概念,鼓励你使用这些代码来更好地理解这些概念。

目录表
准备
随机变量
PMF (Probability Mass Function)
PDF (Probability Density Function)
CDF (Cumulative Distribution Function)
分布
均匀分布
正态分布
二项分布
泊松
对数正态分布
描述性统计方法
评价指标,偏差Bias、均方误差MSE、标准误差SE
采样方法
方差
相关性
线性回归
Anscombe's Quartet
Bootstrapping
假设检验
p-value
q-q plot
离群值
Grubbs Test
Tukey's Method
过拟合
防止过拟合
交叉验证
广义线性模型
Link函数
逻辑回归
概率论vs贝叶斯
文献
准备
随机变量
一个离散变量是一个只能接受“可数”的变量。如果你能数一组项目,那么它就是一个离散变量。离散变量的一个例子是扔骰子的结果。它只能有6种可能的结果中的1种,因此是离散的。一个离散随机变量可以有无限个值。例如,自然数(1、2、3等)的整个集合是可数的,因此是离散的。
连续变量具有“不可数”的值。连续变量的一个例子是长度。长度可以测量到任意程度,因此是连续的。
在统计中,我们用PMF(概率质量函数)和CDF(累积分布函数)表示离散变量的分布。我们用概率密度函数(PDF)和累积分布函数(CDF)表示连续变量的分布。
PMF定义了随机变量的所有可能值x的概率。PDF是相同的,但用于连续值。CDF表示随机变量X的结果小于或等于值X的概率。CDF这个名字既用于离散分布,也用于连续分布。
描述PMF、PDF和CDF的功能起初可能相当令人生畏,但它们的视觉对等物通常看起来相当直观。
i.PMF (Probability Mass Function)
在这里我们可以看到一个二项分布的PMF。可以看到,可能的值都是整数。例如,50 ~ 51之间没有值。
函数形式的二项分布的PMF:
有关二项分布的更多信息,请参见“分布”部分。

ii.PDF (Probability Density Functions)
PDF与PMF相同,但是是连续的。可以说,分布有无穷多个可能的值。这里是一个均值为0,标准差为1的简单正态分布。
正态分布的PDF:

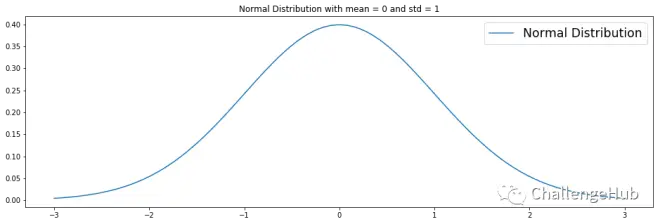
iii.CDF (Cumulative Distribution Function)
CDF映射随机变量X取小于或等于值X 的概率。CDF可以是离散的也可以是连续的。在这一节中,我们把连续的情况形象化。可以在图中看到,CDF累积了所有的概率,因此在0≤x≤1之间。
正态分布的CDF为:

注:erf表示“错误函数”

分布
概率分布告诉我们随机变量每个值的概率。
随机变量X是一个将事件映射到实数的函数。
本节中的可视化是离散分布,当然也可以是连续的。
i.均匀分布
均匀分布非常简单。每个值的发生变化相等。因此,分布由没有模式的随机值组成。在这个例子中,我们生成0到1之间的随机浮点数。
均匀分布的PDF:

均匀分布的CDF:



ii.正态分布
正态分布(也称为高斯曲线或钟形曲线)是非常常见和方便的。这主要是因为中心极限定理(CLT),该定理指出,当独立随机样本的数量(如多次抛硬币)趋于无穷时,样本均值的分布趋于正态分布。
正态分布的PDF:

正态分布的CDF:


iii.二项分布
二项分布有数个结果,因此是离散的。
二项分布必须满足以下三个条件:
a. 观察或试验的次数是固定的。换句话说,你只能计算出某件事发生的概率,如果你做了一定次数。
b. 每次观察或试验都是独立的。换句话说,你的任何试验对下一次试验的概率都没有影响。
c. 每次试验成功的概率都是一样的。
二项分布的一个直观解释是投掷10次硬币。如果是一枚均匀硬币,得到正面的概率是0.5。现在我们扔硬币10次,数一数出现正面的次数。大多数情况下,我们得到正面5次,但也有一个变化,我们得到正面9次。如果我们说N = 10,p = 0.5,那么二项分布的PMF将给出这些概率。我们说正面的x是1,反面的x是0。
伯努利分布是二项分布的一种特例。伯努利分布中的所有值不是0就是1。
例如,如果我们取一枚不均匀的硬币,有60%的概率是正面朝上,我们可以这样描述伯努利分布:
p (change of heads) = 0.6
1 - p (change of tails) = 0.4
其中:
heads = 1
tails = 0
形式上,我们可以用以下PMF(概率质量函数)来描述伯努利分布:


iv.泊松分布
泊松分布是一种离散分布,用于模拟一个事件在时间或空间间隔内发生的次数。
它取值为,等于分布的均值。
PMF:


v.对数正态分布
对数正态分布是连续的。对数正态分布的主要特征是它的对数是正态分布。它也被称为Galton分布。
PDF:

CDF:

其中Phi是标准正态分布的CDF。

描述性统计
i.均值,中值和众数
注:均值也称第一矩。

ii.矩
矩是一个定量的指标,它反映了分布的形状,有中心矩和非中心矩。这部分集中在中心矩上。
第0中心矩是总概率,总是等于1。
第一个矩是平均值(期望值)。
第二个中心矩是方差。
方差 = 均值距离平方的平均值。从数学意义上说,方差很有趣,但标准差通常是更好的衡量分布的分散程度的方法。

标准差 = 方差的平方根

第三个中心矩是偏态分布
偏度 = 描述一只尾巴与另一只尾巴对比的一种方法。例如,如果你的分布中高值比低值更多,那么你的分布就会向高值“倾斜”。

第四个中心矩是峰度
峰度 = 衡量分布中尾部有多“肥”

矩越高,就越难用样本进行估计。为了得到良好的估计,需要更大的样本。

评价指标,偏差、MSE、SE
偏差 是衡量样本均值偏离总体均值的程度。样本均值也称为期望值。
偏差公式:

从期望值(EV)公式可以看出,偏差也可以表述为期望值减去总体均值:


均方误差(Mean Squared Error) 是一个用来测量估计量偏离真实分布的公式。这对于评估回归模型是非常有用的。

**均方根误差(RMSE)**是MSE的根。


标准误差(SE) 测量分布从样本均值的扩散程度。
公式也可以定义为标准差除以样本数量的平方根。


采样方法
非典型抽样
方便取样 = 挑选最方便的样品,比如架子顶部或容易接近的人。
随机抽样 = 随意抽取样本。这常常给人一种你是随机挑选样本的错觉。
目的性抽样 = 为特定目的抽取样本。一个例子是关注极端情况。这是有用的,但有限的,因为它不允许你对整体进行陈述。
典型抽样
简单随机抽样=随机抽取样本(伪)
系统抽样=以固定的时间间隔抽取样本。例如每10个样本(0、10、20等)。
分层抽样=从人群中不同的群体(阶层)中选取相同数量的样本。
整群抽样=将总体分为组(整群),并从这些组中选取样本。


方差
协方差是衡量两个随机变量一起变化的程度。方差和协方差相似方差表示一个变量的变化量。协方差告诉你两个变量如何同时变化。
如果两个变量是独立的,它们的协方差是0。然而,协方差为0并不意味着变量是独立的。

相关性
相关性是协方差的标准化版本。在我们的数据集中,年龄和收入之间没有很强的相关性。
皮尔逊相关系数的公式由两个随机变量之间的协方差除以第一个随机变量的标准差乘以第二个随机变量的标准差组成。
Pearson相关系数公式:

另一种计算相关系数的方法是“Spearman Rho”。这个公式看起来不同,但它会给出与皮尔逊方法相似的结果。在本例中,我们几乎看不到任何区别,但这部分是因为数据集中的年龄和收入列显然没有相关性。
Spearman's Rho公式:


线性回归
线性回归可以通过普通最小二乘(OLS)或最大似然估计(MLE)进行。
大多数Python库使用OLS来拟合线性模型。


这里我们观察到线性模型是很好的拟合。然而,线性模型可能不适合我们的数据,因为数据遵循二次型。多项式回归模型可以更好地拟合数据,但这超出了本教程的范围。
我们还可以用简单的方法实现线性回归。在下面的例子中,我们测量一个随机数据点与回归线之间的垂直距离和水平距离。


线性模型的系数也可以用均方误差(MSE)来计算,无需迭代方法。我也为这种技术实现了Python代码。
i.Anscombe's Quartet
Anscombe's Quartet是四组数据集的集合,它们具有相同的描述性统计和线性回归拟合。然而,这些数据集彼此非常不同。
这概述了一个问题,即尽管汇总统计数据和回归模型确实有助于理解数据,但你应该始终将数据可视化,以了解实际发生了什么。同时一些异常值真的可以搞乱你的模型。Anscombe's Quartet更多资料:https://en.wikipedia.org/wiki/Anscombe%27s_quartet

Bootstrapping
Bootstrapping是一种对给定样本数据的估计量的不确定性进行量化的重采样技术。换句话说,我们有一个数据样本我们从这个样本中取多个样本。例如,我们可以为每个采样样本取均值,从而做出均值的分布。
一旦我们创建了一个估计值的分布,我们就可以用它来做决策。
Bootstrapping可以:
a. 非参数(样本中随机抽取样本)
b. 参数(取样本均值和方差的(正态)分布)。缺点:你对分布做了假设。优点:计算上更轻
c. Bootstrapping引导(从数据流中获取样本)
下面的代码实现了一个简单的非参数Bootstrapping,以创建我们的Toy数据集中收入分布的平均值、中值和中值的分布。我们可以用这个来推断哪些收入意味着对后续的样本有意义。


假设检验
我们建立了两个假设,H0(原假设)和Ha(备择假设)。
我们可以通过假设检验做出四种不同的决定:
a. 拒绝H0且H0不正确(没有错误)
b. 接受H0且H0为真(无错误)
c. 拒绝H0且H0是真的(一类错误)
d. 接受H0和H0不正确(二类错误)
一类错误也称为Alpha错误。二类错误也称为Beta错误。


i.p-values
p值是当零假设(H0)为真时找到相等或更极端结果的概率。换句话说,一个低的p值意味着我们有令人信服的证据来拒绝零假设。
p值小于5% (p < 0.05)。我们经常拒绝H0,而接受Ha是真的。我们说p < 0.05具有统计学意义,因为我们拒绝零假设错误的概率小于5%。
一种计算p值的方法是通过t检验。我们可以使用Scipy的ttest_ind函数来计算两个独立样本得分的均值的t检验。在这个例子中,我们计算了两个随机样本的t统计量和p值10次。
我们看到p值有时很低,但这并不意味着这两个随机样本是相关的。这就是为什么你必须小心过度依赖p值的原因。如果你多次重复一个实验,你可能会陷入一种错觉,认为只有随机性存在相关性。

ii.q-q plot (quantile-quantile plot)
许多统计技术要求数据来自正态分布(例如,t检验)。因此,在应用统计技术之前验证这一点是很重要的。
一种方法是对分布进行可视化和判断。q-q图对于确定一个分布是否正态是非常有用的。还有其他测试“正态”的方法,但这超出了本教程的范围。
在第一个图中,我们可以很容易地看到这些值很好地对齐。由此我们得出结论,数据是正态分布的。
在第二个图中,我们可以看到这些值没有对齐。我们的结论是数据不是正态分布的。在这种情况下,数据是均匀分布的。


离群值
离群值是一种与其他观测值有偏差的观测值。一个异常值通常很突出,可能是一个错误。
离群值会打乱你的统计模型。但是,只有当你建立了移除离群值的良好理由时,才应该移除离群值。
有时,离群值是我们感兴趣的主题。这是欺诈检测的一个例子。异常值检测方法有很多,但这里我们将讨论Grubbs测试和Tukey方法。两种测试都假设数据是正态分布的。
i.Grubbs test
在Grubbs检验中,零假设是没有观察值是离群值,而备择假设是有一个观察值是离群值。因此,格拉布斯检验只寻找一个异常的观察值。
Grubbs Test公式:

其中Y_hat是样本均值,s是标准差。Grubbs检验统计量是在样本标准差单位内与样本均值的最大绝对偏差。
ii.Tukey's method
Tukey认为,当一个观察值是低于第一个四分位数的四分位数范围的1.5倍或高于第三个四分位数的四分位数范围的1.5倍时,该观察值就是异常值。这听起来可能很复杂,但如果你直观地看到它,就会觉得很直观。
对于正态分布,如果没有异常值,Tukey关于异常值观测的标准是不太可能的,但是对于其他分布使用Tukey的标准应该持保留态度。
Tukey方法的公式:

其中Ya是两个均值中较大的一个,SE是均值之和的标准误差。

过拟合
如果我们的模型也建模了数据中的“噪声”,那么它就是过拟合。这意味着该模型不能很好地推广到新数据,即使训练数据上的误差变得非常小。线性模型不太可能过拟合,但随着模型变得更加灵活,我们必须警惕过拟合。我们的模型也可以欠拟合,这意味着它对训练数据有很大的误差。
寻找过拟合和欠拟合之间的最佳点被称为偏差方差权衡。知道这个定理很好,但更重要的是理解如何防止它。
i.防止过拟合
a. 将数据划分为训练数据和测试数据
b. 正则化:限制模型的灵活性
c. 交叉验证
ii.防止过拟合
交叉验证是一种估计统计模型准确性的技术。它也被称为样本外测试或旋转估计。交叉验证将帮助我们识别过拟合,并检查我们的模型是否适用于新的(样本外)数据。
一种流行的交叉验证技术称为k折交叉验证。这个想法很简单,我们把我们的数据集分割成k个数据集,从每个数据集k个中我们选出一些样本。然后我们对k的其余部分进行拟合,并试图预测我们选出的样本。我们使用像均方误差这样的指标来估计我们的预测有多好。重复这个过程,然后我们查看多个交叉验证数据集的预测平均值。
我们挑出一个样本的特殊情况称为“留一交叉验证(LOOCV)”。然而,LOOCV的方差较高。
有关交叉验证的更多信息,请查看这篇博客:https://machinelearningmastery.com/k-fold-cross-validation/
广义线性模型(GLMs)
i.Link函数
广义线性模型(GLMs)中使用了一个Link函数来对给定的连续和/或分类预测器的连续响应变量应用线性模型。经常使用的Link函数称为逆logit或logistic sigmoid函数。
Link函数提供了线性预测器和分布均值之间的关系。

ii.逻辑回归
在逻辑回归中,我们使用类似于上面提到的逆logit函数的链接函数来建模一个二元因变量。线性回归模型直接预测给定x的y的期望值,而GLM使用链接函数。
我们可以很容易地实现逻辑回归与sklearn的逻辑回归函数。

概率论vs贝叶斯
概率论:
a. 固定参数(过程是固定的)
b. 重复采样 概率
贝叶斯:
a. 作为“先验程度”的概率
b. P(parameter) 参数的所有合理值
c. 在先前的信念基础上更新先验概率
概率论者和贝叶斯论者一致认为贝叶斯定理是有效的。这个定理的解释见下图。

贝叶斯定理推广到分布和随机变量。
文献
转载:https://mp.weixin.qq.com/s/6o7EuwS9f21M7q8tlWFKjA
https://dataconomy.com/2015/02/introduction-to-bayes-theorem-with-python
https://www.statisticshowto.datasciencecentral.com/discrete-variable/
https://www.statisticshowto.datasciencecentral.com/probability-and-statistics/binomial-theorem/binomial-distribution-formula/
https://www.statisticshowto.datasciencecentral.com/probability-and-statistics/descriptive-statistics/sample-variance/
https://machinelearningmastery.com/a-gentle-introduction-to-the-bootstrap-method
https://machinelearningmastery.com/k-fold-cross-validation/
https://en.wikipedia.org/wiki/Poisson_distribution
https://www.tutorialspoint.com/python/python_p_value.htm
https://towardsdatascience.com/inferential-statistics-series-t-test-using-numpy-2718f8f9bf2f
https://www.slideshare.net/dessybudiyanti/simple-linier-regression
https://www.youtube.com/channel/UCgBncpylJ1kiVaPyP-PZauQ
https://en.wikipedia.org/wiki/Bias%E2%80%93variance_tradeoff
欢迎学习更多相关知识《呆瓜半小时入门python数据分析课程介绍》

