
零基础炼丹秘籍 - 为自己喜爱的角色训练TTS(文字转语音)模型
注:本文仅用于技术爱好交流,非商用,不对读者的行为负责,请自觉遵守有关法律法规,保护版权,尊重他人劳动成果。
前言
tacotron2是Google在2017年发布的基于PyTorch的TTS神经网络模型[1]。
Google官方为个人用户免费提供colab线上深度学习服务[2],有中文界面。
免费版colab一次只能开启一个会话,单次最长训练时间12个小时,而且需要一直保持界面打开,仅适合入门[3]。单次超时断开后,大概经过一天就会重新可用,但是能用的小时数会少,而且用的越频繁就会越少。你可以用训练出来的模型接着上次的地方训练。
基于该平台,以日语语音为例,参考视频"Updated and Works as of 2022/4/29: Speech Synthesis with Tacotron 2 in Maya-K'iche"[4]和“基于tacotron2合成宁宁语音(day1-2)”[5],我们开始零基础训练模型之旅。


本文介绍的方法主要是通过colab省去配置环境的麻烦实现零基础训练。如果对Python环境配置有一定基础,而且手上有满足炼丹需求的机器资源,可以在自己的机器操作。
需要准备的
一台能访问Google深度学习平台的电脑
用于数据收集和配置线上环境(会比线下简单很多)的时间
提取出的角色语音和台词
路线图
提取角色语音
获取台词文本(这两步最耗精力)
复制一份“笔记”副本并上传前面的文件
修改几个参数(很简单!)
一键开始训练
合成语音
第一步 提取角色语音
首先需要一些材料,比如角色语音和角色文本,我们挑简单的来。
Galgame中的人物语音大都一句句分好了,非常适合使用。提取的过程可以使用GARbro软件提取游戏中的各类资源,比如voice.xp3。用GARbro提取不出来可以用krkrextract[7]。推荐教程:

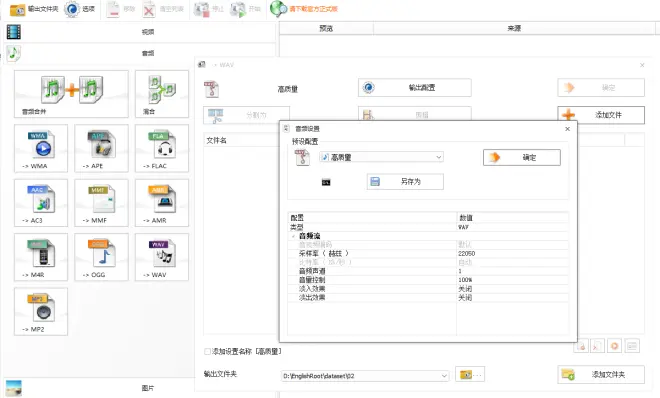
注意:提取出的语音需转换成wav格式,单声道,采样率必须为22050Hz,PCM 16bit。仅仅是wav格式不一定符合要求。关于转换音频格式,opus格式文件可以直接用GARbro转换,ogg格式文件可以用ffmpeg转换[7]。不懂这些参数也没关系,我也不懂,甚至用格式工厂转换一下也能行,可以参考下面的配置:
第二步 获取台词文本
获取到台词文本即可。建议如果游戏文件中有scn.xp3文件,可以解包得到ks.scn文件,用FreeMoteToolkit转成json提取文件。如果实在没有办法获取原台词,可以尝试使用whisper听写台词。
用notepad新建一个文件,文件名取什么都行,比如list.txt。文件内容大致如下:
左侧是语音文件的名称,后侧是对应的文本,用英文标点'|'分隔。文本文件中不能有空行,需要保存为UTF-8编码。文件名前面需要带"wavs/"前缀,或者也可以放其他目录。建议用默认的wavs目录,会省去一些不必要的配置麻烦。
第三步 复制notebook并上传资源
根据原作者提供的notebook和up主CjangCjengh的cleaner[6]改了一份写好的中文深度学习notebook[8],只需要一步一步配置就可以了。
链接: https://colab.research.google.com/drive/18fbCupSaQde-FtF2Z2Na-LP5BrukjNMs?usp=sharing
打开后,先复制一份副本,在弹出的副本页面中进行接下来的操作:
一路点播放键,等待显示对号后,点击下一个播放键,执行下一段代码。
然后把准备好的语音文件放到wavs目录下,带有语音文件列表和对应台词的文件list.txt放到filelists目录下。选中这两个文件夹,右键菜单中打包成压缩包上传到云端硬盘。你也选择上传数据方式1,但是会需要每次上传数据,比较繁琐。

上传完后按顺序点击代码块的播放键即可。
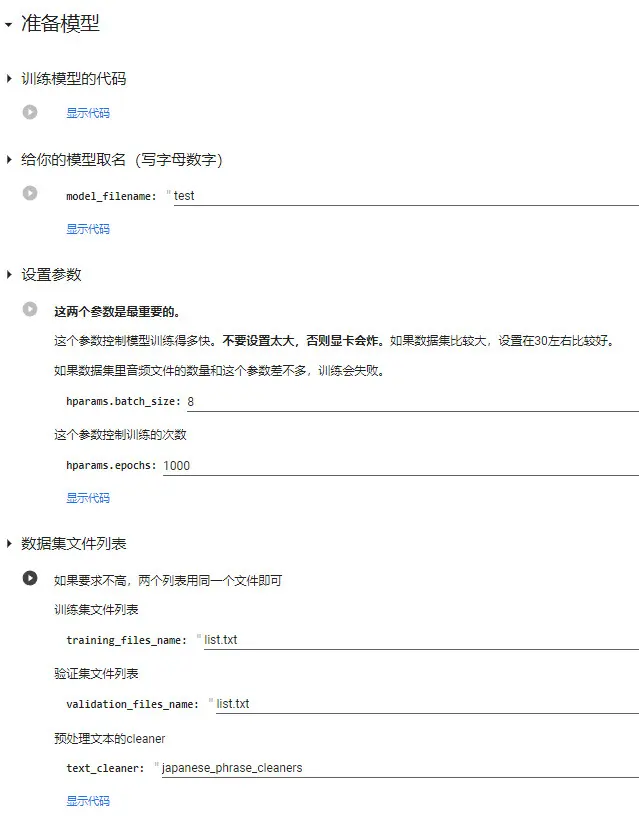
后面很简单,只需要填写几个参数。
第一个,model_filename,模型的文件名。
第二个,batch_size,和语音文件的数量有关,建议设置的比语音文件的数量稍小一些,不要设置太大,否则显卡会炸掉。这里我的样本用于演示,比较少,可以设置的更多,比如有30个语音文件就设置为20。免费版Colab(16G显存)建议设置不要超过40。
第三个,epochs,训练的次数,次数越多可能越精准,花的时间可能越长,可以设置成300或更多。
第四个,training_files和validation_files,训练文件和验证文件的列表,填我们刚才编写好的list.txt即可。
第五个,text_cleaner,选择预处理文本的cleaner,即把日语台词自动转换为罗马音的处理方式,笔记下面有几种cleaner的比较。
其他超参数一般不用额外配置。设置完后点击播放键运行。
继续点击播放键运行代码,生成mel谱,检查数据集。
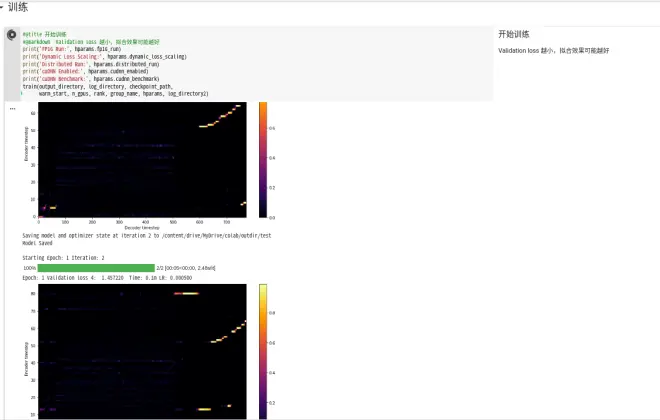
第五步 一键开始训练!
点击播放键开始训练。如果没有问题,你会看到如下所示内容。
如果不手动停止,一共会迭代epochs参数里设置的次数。
训练时间越长,效果可能越好,俗称“炼丹”。
训练到Validation loss在0.15以下即可收获一定效果。
如果Validation loss居高不下,可能是音频文件比较多,也可能是音频文件对应的台词有错误。其他问题可参考笔记本内的Q&A。
第六步 合成语音
生成的模型会保存在你的云端硬盘上。有了模型,就可以导入到HifiGan和WaveGlow等合成语音了。
可以在colab上合成,也可以下载模型在本地合成语音。目前至少有三款合成语音的软件,在本地导入模型即可合成语音,推荐在下面:



参考资料
[1] Tacotron 2: Generating Human-like Speech from Text, Google AI Blog, https://ai.googleblog.com/2017/12/tacotron-2-generating-human-like-speech.html
[2] Google Colab, Google, https://colab.research.google.com
[3] 在 Colab 中,笔记本可以运行多长时间?, Google, https://research.google.com/colaboratory/faq.html#idle-timeouts
[4] Updated and Works as of 2022/4/29: Speech Synthesis with Tacotron 2 in Maya-K'iche, Oxlajuj No'j Thirteen Wisdom, https://www.youtube.com/watch?v=e6EhXUdjppo
[5] 基于tacotron2合成宁宁语音(day1-2), CjangCjengh, https://www.bilibili.com/video/BV1rV4y177Z7
[6] tacotron2-japanese, CjangCjengh, https://github.com/CjangCjengh/tacotron2-japanese
[7] "纸片人技术交流群(702724269)"群内Q&A, CjangCjengh
[8] Tacotron2SpeechSynthesisDemoV3.ipynb, Google Colab, https://colab.research.google.com/drive/1VAuIqEAnrmCig3Edt5zFgQdckY9TDi3N?usp=sharing
