
深入研究k折交叉验证(K fold Cross Validation)
机器学习方法常常不能直接对数据进行建模,因为它们学习的是训练集的特定特征,而这些特征在测试集中是不存在的。所以这些特征并不具有代表性,我们处于Overfitting的情况。(有不同意见后台来和学姐讨论,别直接取关,嘤嘤嘤~)
当模型拟合过多的训练数据时,就会出现这种情况,而且它不能在新的样本中泛化。不过有很多方法可以解决这个问题,比如:正则化、选择最佳超参数和K折交叉验证。
上周学姐介绍了K折交叉验证基本知识点的讲解,今天我们来深入研究一下。
因为模型的公正表现与它具有相关作用,简单地将数据分成训练集和测试集并不能真正了解模型的性能。比如,当看到训练集的准确率是90%觉得很准确,但在看到60%的测试准确率之后,会觉得肯定是出了什么问题。
所以一般的想法是将数据集分成k个部分,k-1个用于训练,一个用于验证/测试。这样的话,我们可以将数据集分成5折,因此4折将用于训练模型,而剩余的折用于评估模型的性能。如果这样进行分区,需要每次更改用于评估模型的折叠位置并重复5次。
为了更好地了解所有要使用的工具,我将使用来自Kaggle的Titanic数据集展示最常用的交叉验证技术。
Kaggle数据集:
https://www.kaggle.com/c/titanic/data
代码:
https://github.com/eugeniaring/sklearn-tutorial/blob/main/titanic-kcv.ipynb
由于测试集不包含目标标签,本教程中仅使用训练集。这是避免过度拟合的一种方法,过程中会使用较少的训练数据来训练模型,并在验证集中进行评估。
本教程大纲:
交叉验证
留一法交叉验证
K折交叉验证
分层K折交叉验证
时间序列交叉验证
01 交叉验证

经典和老式的方法是将数据集分解为3个固定子集:
常见的选择是使用 60% 进行训练,20% 用于验证,20% 用于测试。我们可以根据数据集的大小决定这些比例。对于一个小数据集,这个比例是可以的;当有更多数据时,可以考虑较大的训练集百分比和较小的验证集和测试集百分比。
接下来我们使用具有已处理特征的Titanic数据集的方法。在训练模型之前,我们将训练数据分为训练集和验证集。

一旦数据被拆分,我们训练决策树分类器并在验证集中对其进行评估。

02 留一法交叉验证
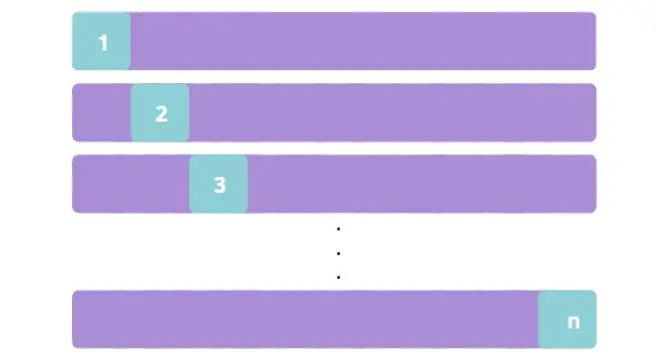
第二种方法将观察结果分为两部分:
n-1个观测值来拟合模型,剩余的观测值用于评估它。此操作将重复n次。接下来按照相同的推理说明函数LeaveOneOut是如何工作的:

现在使用cross_val_score函数来应用留一法。cv是决定用不同方法分割数据集的策略的参数。在下面的例子中,使用了Leave One Out对象。

得到每次分裂的预测和准确度,然后计算所有获得值的平均值。结果表明,该方法的准确度低于交叉验证方法,这可能是因为每次拆分数据集并使用不同的验证折叠不会高估验证准确性。但通常它不是首选方法,因为分割中没有随机性,而且计算成本很高。我们可以尝试用其他方法。
03 K折交叉验证

如前所述,在K折交叉验证中,我们将数据集分成k个折叠,k-1用于训练模型,剩余的一个用于评估模型,不断重复这个操作k次。
用下面这个例子来了解这种方法如何拆分数据集,为简单起见,我们仅使用5折,并指定shuffle等于True以进行随机拆分:

以上我们观察到,每个折叠中具有正类和负类(幸存/未幸存)的样本数量不同,这是因为Titanic数据集具有不平衡的类。
接下来看模型的性能如何,此次在函数cross_val_score中应用了KFold对象:

性能比使用前一种方法要好得多。但是还有一个问题,就是正类和负类的观察数量是不同的:

结果:幸存的人数少于死亡人数。
还有一种更好的方法来管理不平衡的类,称为分层K折交叉验证。
04 分层K折交叉验证

分层K折交叉验证的工作方式与K折交叉验证相同,唯一的区别是它确保每个分类值的观察百分比相同。本案例中有两个类,Survived 和 Not Survived。
下面的示例中,分层K交叉验证根据变量Survival划分数据集。

现在,可以看到从一层到另一层的不同类的样本数量没有变化或略有变化,是因为我们正在根据目标变量对数据集进行分层。

所有折叠的平均准确率为79.79%。它比用前一种方法获得的略小,但我仍然认为这种方法对此类数据更有效(欢迎讨论)。
05 Time Series Cross Validation

最后一种方法是时间序列交叉验证。当存在与时间相关的数据时,它很有用,因此我们需要保留数据的顺序。通过随机化,我们将失去观察之间的依赖关系。
在第一步中,我们不像其他方法那样取所有样本来训练和评估模型,而只是取一个子集。在第一步之后,每个训练集都是来自之前的训练和验证集的组合,我们每次都添加一个较小的数据来评估模型。只有在最后一次拆分中,我们才能使用所有数据。
在示例中,我们使用了5折,未指定,因为它是TimeSeriesSplit中的默认参数。

现在按照之前完成的相同程序进行操作:

end 总结
本文说明了将数据拆分为子集的最广为人知的方法,但是还是需要使用相同的数据集尝试更多方法,看看哪种方法更好。从本文实验来看最好的方法通常是K折交叉验证和分层K折交叉验证。希望学姐的这篇教程对大家有所帮助!

每天18:30分更新
关注+星标+在看
不迷路看好文

