
2023.03.31 ArXiv精选
关注领域:
AIGC
3D computer vision learning
Fine-grained learning
GNN
其他
声明
论文较多,时间有限,本专栏无法做文章的讲解,只挑选出符合PaperABC研究兴趣和当前热点问题相关的论文,如果你的research topic和上述内容有关,那本专栏可作为你的论文更新源或Paper reading list.

Paper list:
今日ArXiv共更新136篇
NeRF
NeRF-Supervised Deep Stereo
https://arxiv.org/pdf/2303.17603.pdf

AIGC
AvatarCraft: Transforming Text into Neural Human Avatars with Parameterized Shape and Pose Control
https://arxiv.org/pdf/2303.17606.pdf
基于文本的human avatar生成,引入了扩散模型.
Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
https://arxiv.org/pdf/2303.17591.pdf

LayoutDiffusion: Controllable Diffusion Model for Layout-to-image Generation
https://arxiv.org/pdf/2303.17189.pdf

基于layut的图像生成.
VLP
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
https://arxiv.org/pdf/2303.17602.pdf
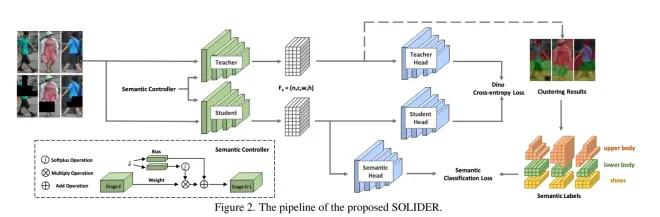
阿里巴巴的工作,CVPR2023已接收.利用无标注的human image数据,进行自监督预训练.
Going Beyond Nouns With Vision & Language Models Using Synthetic Data
https://arxiv.org/pdf/2303.17590.pdf

使用合成数据来训练视觉语言模型,使得其具有更加open的能力.
SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger
https://arxiv.org/pdf/2303.17561.pdf

引入软对比学习至CLIP.
MAE
Masked Autoencoders as Image Processors
https://arxiv.org/pdf/2303.17316.pdf

