
SDVO:LDSO+语义,直接法语义SLAM(RAL 2022)
论文阅读:Semantic-Direct Visual Odometry
Motivation
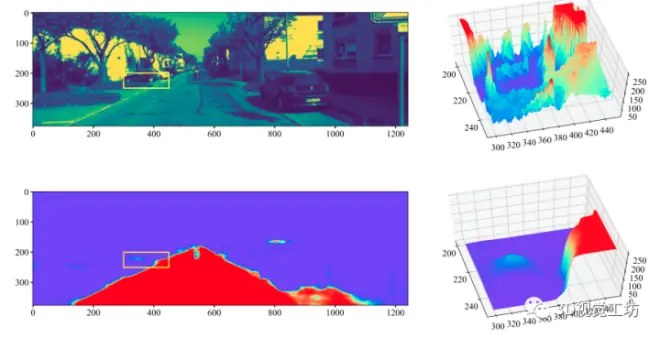
虽然直接法SLAM在无纹理环境更加鲁棒,但是由于灰度图像的凸性特征导致光度误差的凸性仅在一个小区域内保持的问题,所以传统的直接法视觉SLAM在当跟踪点有较大位移时,可能陷入次优局部极小解,具体问题描述如下图,左边分别是对应区域的灰度图和语义概率图,右图相应的三维可视化,灰度图像保留了对象的细节,而道路的概率主要在道路边界上进行生成,对于语义对象边界上的点,语义概率的凸性在比灰度图像更大的区域中成立。另外,目前虽然也有可以跟踪动态物体的SLAM,但是他们绝大部分都是使用重投影误差之类的优化项,这些都是6个自由度。这其实与现实世界并不符合,比如说,大部分汽车只有3个自由度,2个自由度在平移(道路平面),1个自由度在旋转(汽车自身法向量)。所以消除与物理意义不对应的自由度也是有必要的。对应这个问题的解决办法,作者是选择将约束表示为机械关节,因为机械关节的运动是有限制的,从而减少了自由度。
作者:晃晃悠悠的虚无周 | 来源:微信公众号「3D视觉工坊」
Contribution
所提出的SDVO是第一个利用语义概率直接匹配的视觉单目SLAM系统。
通过将语义概率的直接对齐集成到LDSO中,提高了定位性能,优于ORB-SLAM2。在KITTI里程数据集上的实验结果证明了该方法的有效性。
Content
语义概率与点选择策略
对于每个输入图像I,通过HRNet生成密集的像素级语义分割,每个像素标记为集合C中的一个语义类。对于点p,p属于语义类C的概率可以计算为:
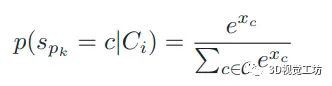
其中,是点p所对应的语义通道c中logits层的值。所有语义类的概率之和初始正则化为1。HRNet的logits层有19个通道,对应19个语义类。然而,并非所有的语义通道在KITTI里程计数据集中都有丰富的信息和跟踪提示。所以只采用KITTI里程数据集中经常出现的9个语义通道,包括道路、人行道、建筑物、栅栏、杆子、植被、地形、天空和汽车。下图显示了KITTI语义分割基准中4个代表性场景的9个选定通道的可视化。如下图所示,语义对象的边界被很好地捕捉,尤其是道路、植被、天空和汽车的边界。
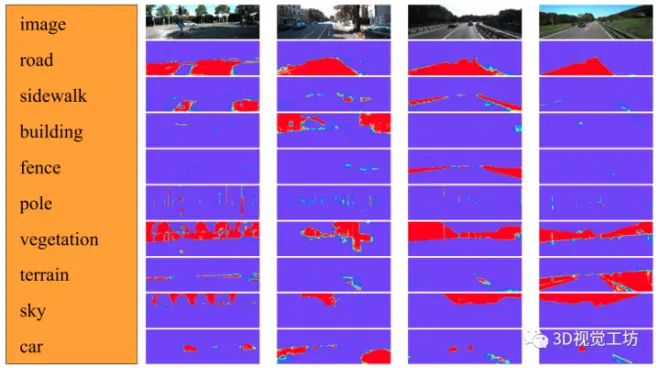
点选择策略的主要目标是选择具有高语义梯度的点从而最大化语义概率直接匹配的强度,通常,语义对象边界上的点在语义通道和灰度图像中都具有高梯度,LDSO使用Shi-Tomasi得分来检测灰度图像中的角点,本文所提出的方法基于这个思路,计算9个选定通道的Shi-Tomasi得分之和来检测语义角点,如下图所示,所提出的SDVO主要选择语义对象边界附近的点,而LDSO同时选择对象内部和边界附近的点。

2.优化残差构建优化中主要用到两个匹配误差,一个是光度误差:
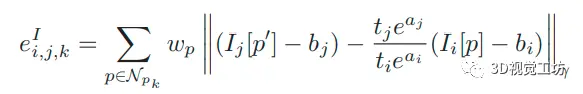
类似的,在参考帧中监测到的语义通道c中的点p的语义匹配误差可以定义为::
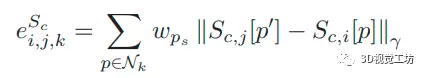
其中,是帧i的语义通道c的语义概率,是语义通道c的启发式权重因子。光度误差和语义对齐误差之间的主要区别是输入。光度误差测量灰度图像的直接匹配,而语义匹配误差测量选定语义通道的语义概率的直接匹配误差。最终的联合优化公式可以定义为这个形式:
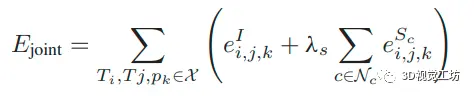
Nc是所选语义通道的集合;λs是所有选定语义通道的语义对齐错误的权重。3.滑窗优化
采用LM算法进行优化,定义待优化变量有:
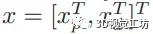
xp包括摄影机内部参数、仿射亮度参数和摄影机姿势,xd包括点的逆深度。通常来说,滑窗优化定义如下:
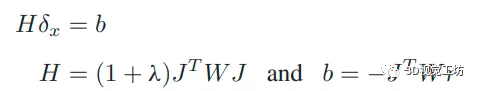
J是残差r的雅可比矩阵,W是加权矩阵,r包含了光度误差和语义概率误差,所以相应的滑窗优化公式可以改写为:
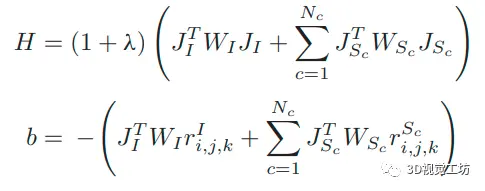
(注:论文作者并没有提到相关的滑窗策略变动,这点还是挺重要的)
4.实验
评测数据集是KITTI。虽然KITTI是唯一一个为里程计和像素级语义分割提供数据的真实数据集,但是KITTI语义分割基准只有200幅语义标注的图像,这不足以训练像HRNet这样的复杂模型。为了获得准确的语义概率,首先基于Cityscapes数据集预训练模型,在KITTI语义分割基准上对HRNet进行微调。
A.超参分析
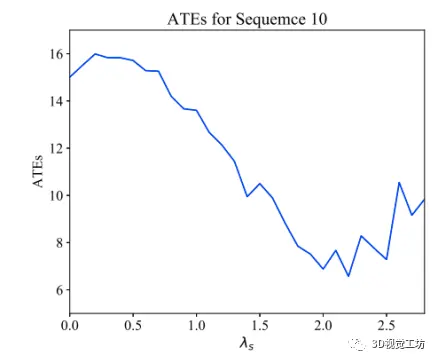
关于超参λs的调整,基于的数据集是KITTI序列10,然后关于不同指标的ATE对比图如下,可以认为,最佳的λs取值为2.2。对于这个2.2取值的理由,作者认为,因为语义概率的直接匹配会带来更好的凸性,所以在2.2之前,ATE是呈现一个下降的趋势,但是当值大于2.2之后,然而,灰度图像的直接匹配可能会逐渐陷入语义概率的直接匹配的局部最小解中,因此ATE就会增大。
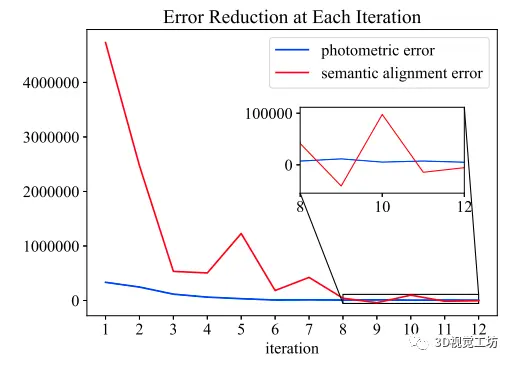
除此以外,关于光度误差和语义误差的作用,作者认为语义误差有助于在大范围场景提供一个相对精确的初值,但是很难进一步优化,但是光度误差可以在语义误差的基础上提供一个精优化的功能,对于这个猜想,作者通过如下的实验进行证明,语义误差可以在相对少的迭代次数里降低最多的误差,光度误差可以在此基础上进一步优化。
B.不带回环的对比
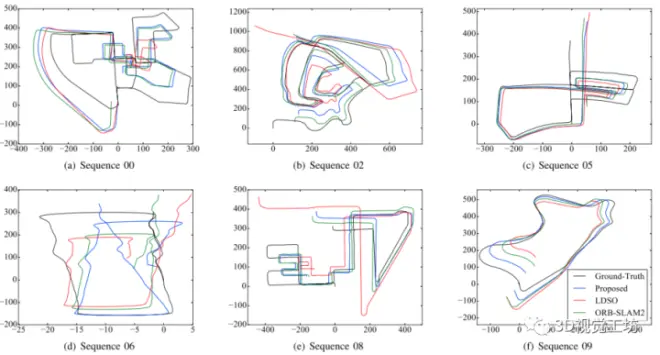
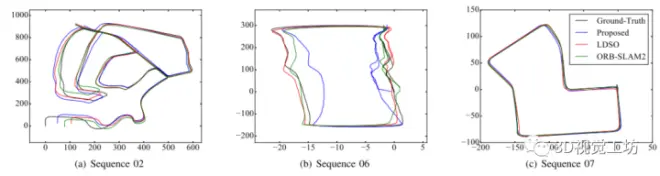
最后一列是与LDSO相比所提出方法的改进。第二列和第四列显示,ORB-SLAM2比LDSO更精确,而LDSO更稳健(ORB-SLAM2在序列01上失败,因为高速公路场景的纹理较少),所提出的方法的精度在所有场景中表现都比baseline LDSO好,并且序列00、02、04、06、08、09和10的改进都在42%以上。该方法在序列01、04、06、09和10上的性能最好;VSO在序列00、02、05、07和08上的性能最好;ORB-SLAM2在序列03上实现了最佳性能,这主要是由于超参设置是根据序列10选择的,所以可能并不适用于全部的场景。相应的具体轨迹如下图, 在序列00、06和09中,用该方法估计的轨迹比ORB-SLAM2更接近地面真值,而在序列02中,用ORB-SLAM2估计的轨迹更接近地面真值。在序列05和08中,所提出的方法与ORB-SLAM2之间的估计轨迹差异不明确。
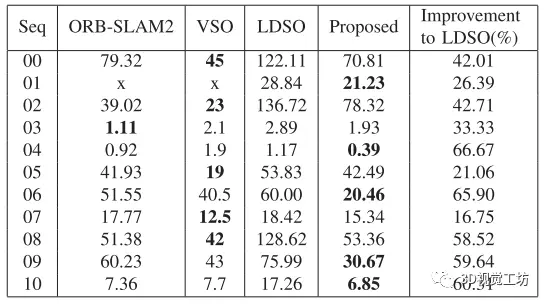
在这个实验环节,主要是证明了语义概率直接对齐的集成可以提高LDSO的跟踪精度。与ORB-SLAM2相比,在取消闭环的情况下,与ORB-SLAM2相比,该方法在KITTI里程计数据集的大多数序列(序列02除外)中实现了更好或可比的性能,同时在无纹理环境中保持了鲁棒性。
C.不带回环的对比
对于序列09,LDSO的闭环根本不起作用,而ORB-SLAM2的闭环偶尔起作用。因此,表II中LDSO的跟踪结果和序列09的拟定方法与表I相似。总的来说,与有回环位置的LDSO等序列相比,该方法的改进程度小于没有回环的序列。该方法在序列04、05、06、09和10上的性能最好。同时,该方法在序列00、02、07和08上的性能接近最佳。下图显示了ORB-SLAM2、LDSO以及所提出的方法在具有回环位置的轨迹,因为闭环与语义概率直接匹配之间的互补特性,语义概率直接匹配的改进减少了误差(比较表1和表2)。与ORB-SLAM2相比,在激活闭环的情况下,所提出的方法在KITTI里程计数据集的所有序列中实现了更好或可比的性能,同时在无纹理环境中保持了鲁棒性。
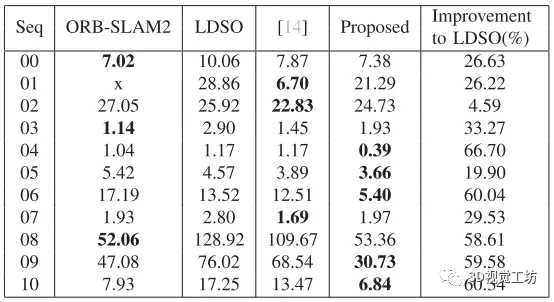
Conclusion
这篇文章的贡献在于将语义概率和光度误差结合形成一个直接法语义slam,总的框架是基于LDSO的,融合后的效果的确是显著提升了性能,达到了接近于orb2的效果。本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊精品课程官网:https://www.3dcver.com
更多干货
欢迎加入【3D视觉工坊】交流群,方向涉及3D视觉、计算机视觉、深度学习、vSLAM、激光SLAM、立体视觉、自动驾驶、点云处理、三维重建、多视图几何、结构光、多传感器融合、VR/AR、学术交流、求职交流等。工坊致力于干货输出,为3D领域贡献自己的力量!欢迎大家一起交流成长~
添加小助手微信:dddvision,备注学校/公司+姓名+研究方向即可加入工坊一起学习进步。
