
算法浅谈之随机森林算法

一 起因
起因嘛,非常简单,就是最近设计的算法有使用到随机森林这一块,但是呢,目前对于随机森林的算法不是完全的知根知底。因此,正好趁着写推文的时候,把这个算法吃透,也方便自己后续工作的展开
二 正文
既然谈到随机森林,那么不可避免就得先介绍一下决策树决
策树:一种常见的机器学习算法,它通过将数据集分成一系列不同的子集,来构建一个决策规则的树形结构,从而对新数据进行分类或预测。在生成决策树时,算法通过对数据进行递归分割,不断选择最佳的分裂点和特征,将数据划分成更小的子集,直到达到停止条件(例如达到最大深度或叶子节点数量达到预定阈值)。
先科普一个名词,基尼系数为0:每个子节点达到最高的纯度,即落在子节点中的所有观察都属于同一个分类,此时基尼系数最小,纯度最高,不确定度最小。
简单来说就是计算不同特征值的信息熵,之后根据选择信息熵最大的一个特征进行二分裂,直到最终的结果无法进行再一次的分裂(分裂的结果仅为单个分类结果),即基尼系数为0。当然,如果深度不够,最终的基尼系数也并不一定是0。
基尼系数为0:每个子节点达到最高的纯度,即落在子节点中的所有观察都属于同一个分类,此时基尼系数最小,纯度最高,不确定度最小。
接着,我们通过python代码,对决策树的生成进行可视化,从而了解这个树是怎么构建的(内容有限,代码部分可以后台联系索取)。
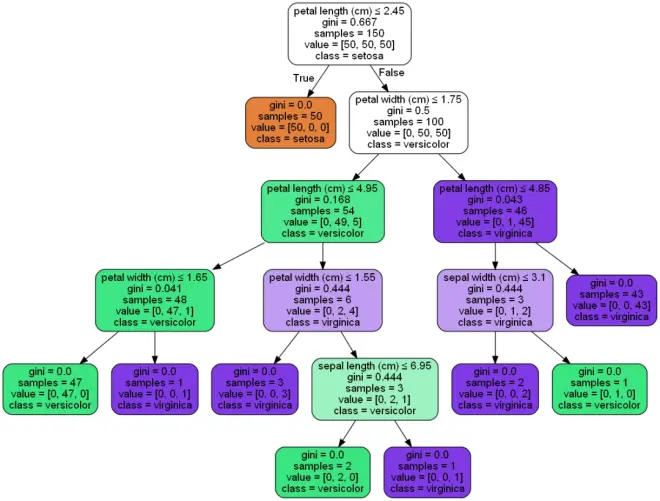
随机森林:随机森林是一种机器学习算法,它是由多个决策树组成的集成学习模型。每个决策树都是通过对随机选择的子集数据进行训练而生成的。
随机森林中的每个决策树都是相互独立的,并且可以并行生成和预测。在生成每个决策树时,随机森林还会对每个决策树中使用的特征进行随机采样,以确保每个决策树都能够学习到数据的不同方面。
在进行预测时,随机森林会将所有决策树的预测结果进行汇总,并根据汇总结果来进行最终的预测。
由于随机森林使用了多个决策树的预测结果,因此它可以减少单个决策树的过拟合现象,提高模型的泛化能力和鲁棒性。随机森林适用于许多机器学习问题,如分类、回归和异常检测。由于它的性能和稳定性在许多应用中都得到了证明,随机森林已成为许多机器学习问题中的流行算法之一。
如下图,我们随机选择从四个特征中选择三个特征,对模型进行拟合
选择特征:X1-X2-X3-X0

选择特征:X3-X0-X2

选择特征:X3-X1-X2

三 惯例小结
随机森林应该是一个非常非常经典的算法了。对于复杂特征而言,该算法也算是非常优雅的二分类算法了。但是呢,这一算法其实还是有很多可以提升的空间,比如读者通过调整最大深度和最大特征数的参数,通过对特征的进一步挑选等等。不过这一算法的理解却是很直观,可以让我们从模型上解释数据。
PS:最近,随着AIGC的进一步优化,留给普通生信分析人员的空间已经越来越少了,或许,对于生信从业者而言,可能真正无法被取代的部分应该就是算法设计和生物问题的提出了吧(如果AI也会算法设计并运行,那么,这个世界应该真的就没有人类的什么事情了,至少在理论这一块)。所以,后续,本公众号会更多在算法介绍方面进行分享,希望能够与大家一起进步。
四 公众号其他资源(方便读者使用)
本公众号开发的相关软件,Multi-omics Hammer软件和Multi-omics Visual软件欢迎大家使用。
Multi-omics Hammer软件下载地址:
https://github.com/wangjun258/Multi-omics-Hammer
Multi-omics Visual软件下载地址:https://github.com/wangjun258/Multi_omics_Visual/releases/tag/Multi_omics_Visual_v1.03
PS:因为本软件是用python脚本撰写,调用了部分依赖包,用户首次使用需要安装python以及对应的包,安装之后便可永久使用。
下面是本号在其他平台的账户,也欢迎大家关注并多提意见。
简书:WJ的生信小院
公众号:生信小院
博客园:生信小院
最后,也欢迎各位大佬能够在本平台上:1传播和讲解自己发表的论文;2:发表对某一科研领域的看法;3:想要达成的合作或者相应的招聘信息;4:展示自己以寻找博后工作或者博士就读的机会;5:博导提供博后工作或者博士攻读机会,都可以后台给笔者留言。希望本平台在进行生信知识分享的同时,能够成为生信分析者的交流平台,能够实现相应的利益互补和双赢(不一定能实现,但是梦想总得是有的吧)。



