位置误差:选择IOU最大的候选框
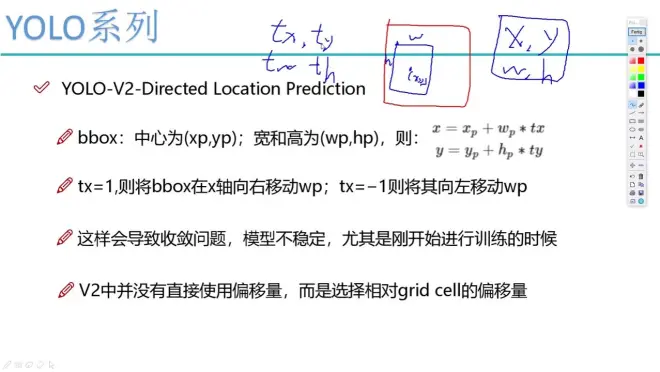
x,y,w,h参数的误差
5-置信度误差与优缺点分析 P11 - 00:10
置信度损失:分类考虑
5-置信度误差与优缺点分析 P11 - 04:45
背景部分加权重参数的含义
5-置信度误差与优缺点分析 P11 - 05:52
类别误差
5-置信度误差与优缺点分析 P11 - 07:55
NMS:解决候选框重叠,选置信度最大的
5-置信度误差与优缺点分析 P11 - 09:04
YOLOv1的问题
1、重叠检测不到
2、小目标检测效果差
YoLov2的BN
BN做了什么
但凡有了conv都要加BN
v1为什么不用448训练
网络结构
vs 1代
1x1 卷积的作用
4-基于聚类来选择先验框尺寸 P15 - 00:30
yolov2先验框设计
加不加先验框对结果的影响
虽然结果变化不大,但是查全率更高
坐标的改进
相对值
感受野是干嘛的
感受野对卷积核的要求
卷积核大点好还是小点好
小的好,参数少
特征融合的目的
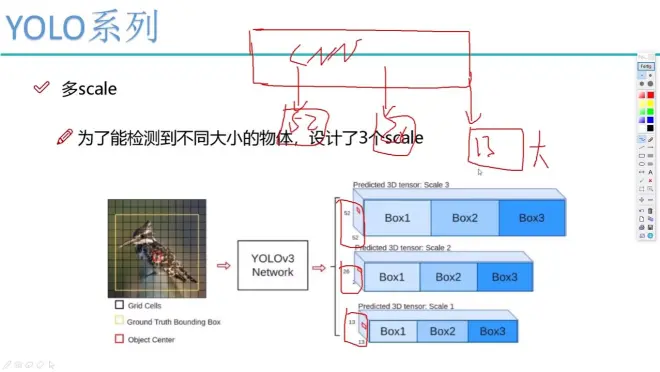
v2多尺度
v3的改进
2-多scale方法改进与特征融合 P21 - 00:27
v2是如何处理多尺度的:一股脑融合
好吗?
2-多scale方法改进与特征融合 P21 - 01:42
v3改进:术业有专攻
2-多scale方法改进与特征融合 P21 - 02:18
具体细节
每个特征图分别对不同大小的物体检测,各设置3个先验框
2-多scale方法改进与特征融合 P21 - 05:46
如何融合
3-经典变换方法对比分析 P22 - 00:07
尺度变换方法
1、图像金字塔:速度慢,不适用于yolo 2、单一的结果(适用于哟咯)
3、分别利用不同特征图信息(52*52的不一定能预测的好)
4、融合特征图
5-整体网络模型架构分析 P24 - 00:41
v3网络结构:没有FC和BN
卷积省时省力,效果好,别的东西能不用就不用
5-整体网络模型架构分析 P24 - 02:20
先验框的效果
7-sotfmax层改进 P26 - 00:07
softmax改进:一个物体可能属于多个标签
v4两个核心方法
网络设计:1、提特征 2、特征融合(注意力机制等小细节)3、头
BOF
数据增强
四个图像拼接的目的:batch不变(考虑显存),batch-size变为原来的4倍
4-DropBlock与标签平滑方法 P54 - 00:21
增加噪音干扰
4-DropBlock与标签平滑方法 P54 - 01:08
dropout是什么:随机杀掉一些点,难度太低
4-DropBlock与标签平滑方法 P54 - 03:09
dropblock
4-DropBlock与标签平滑方法 P54 - 04:24
标签平滑
4-DropBlock与标签平滑方法 P54 - 06:43
不做标签平滑vs做
5-损失函数遇到的问题 P55 - 00:12
IOU损失
问题:有时候相同的IOU反映不出情况好坏
IOU=0,1-Iou=1,梯度=0,无法训练
5-损失函数遇到的问题 P55 - 03:03
IOU升级GIOU
问题:重叠时检测不到
6-CIOU损失函数定义 P56 - 00:10
DIOU:没用
6-CIOU损失函数定义 P56 - 03:05
CIOU:比DIOU多考虑长宽比
8-SPP与CSP网络结构 P58 - 00:58
8-SPP与CSP网络结构 P58 - 02:06
SPPnet
8-SPP与CSP网络结构 P58 - 03:51
CSP(很重要)
9-SAM注意力机制模块 P59 - 00:18
CBAM
通道注意力:得到每一个类别对应的权重值
9-SAM注意力机制模块 P59 - 05:50
v4引入的是SAM
9-SAM注意力机制模块 P59 - 07:21
对SAM的修改
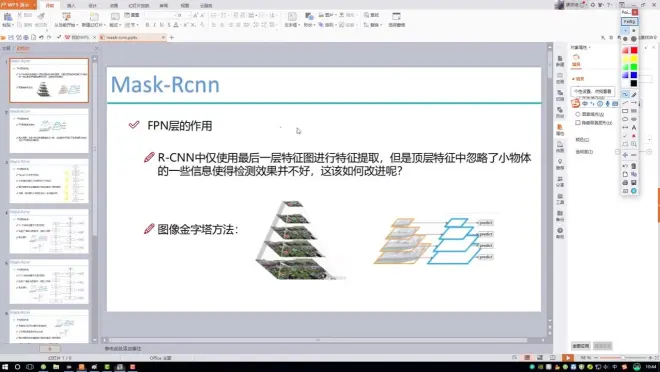
FPN的故事
1-FPN层特征提取原理解读 P81 - 00:10
FPN前言:图像金字塔
1-FPN层特征提取原理解读 P81 - 03:43
FPN的特征融合
1-FPN层特征提取原理解读 P81 - 06:20
1-FPN层特征提取原理解读 P81 - 07:48
1X1卷积:保证特征图个数相同
FPN的问题:缺了底层到高层的特征传递
双向?费时间 引入pan
11-激活函数与整体架构总结 P61 - 00:02
激活函数:改进relu
11-激活函数与整体架构总结 P61 - 02:38
后处理
11-激活函数与整体架构总结 P61 - 04:44
v4网络架构
11-激活函数与整体架构总结 P61 - 06:34
v4贡献回顾
标签: