
一些记录
个人理解:
深度学习的本质就是拟合,只不过参数量足够多。
先构建模型,也就是拟合的曲线或方式。再配置数据集和输出,数据集就是输入的数据,经过模型,定义的拟合方式,变成输出。可以看作是一个预测的过程。最后定义训练,输入进入到模型,并没有变成理想的输出,肯定是模型的参数不合适。那就定义一个损失,要让实际输出和理想输出的损失最小,采用梯度下降算法,一步步调整模型的参数,就是一个训练的过程了。
尺度不变性:目标检测对于大物体和小物体都要能检测,coco数据集小物体多,imagenet数据集大物体,这样使得预训练参数要适应两个数据集。下采样小物体特征消失,上采样大物体检测下降。需要兼顾大小物体,并且具有泛化性。
方法:
图像/特征金字塔:通过输入多尺度的图像获得不同尺度的特征图。-----------------有效但是耗时长
卷积核金字塔:对特征图用不同尺度的卷积核滑窗卷积,得到不同尺度的输出。------通常会与图像/特征金字塔联合使用
anchor金字塔:比如Faster RCNN中用多尺度的anchor来回归目标的位置。-----更经济。Faster RCNN的anchor点是在特征图上取的。
图像金字塔:图像金字塔是一个图像集合,集合中所有的图像都源于同一个原始图像,通过对原始图像连续降采样,直到达到某个终止条件才停止降采样。
高斯金字塔:进行下采样。进行卷积,然后去掉偶数行,偶数列,变成原来四分之一,从而得到一系列像金字塔的图片,图片信息有损失。进行上采样的话,填充为0的偶数行,偶数列,再卷积,生成的图片比原始图片模糊。
拉普拉斯金字塔:可以理解为一个残差。把原始图片减去 原始图片->下采样->上采样,得到一个残差图,然后在一系列高斯金字塔中进行计算,得到一系列的残差图,构成拉普拉斯金字塔。这些残差图也就保存了原始图片下采样损失的信息。
但是都有原始图片了,还要拉普拉斯金字塔干嘛?拉普拉斯金字塔有何应用?图像融合,分割?
特征金字塔:
参考链接:视频 FPN特征金字塔网络解读 - 简书 (jianshu.com)
1.图像金字塔有效果,但计算量大

2.卷积池化得到最后的特征图,可以得到高层语义信息,但是会丢掉小物体的检测

3.金字塔特征分层 Pyramidal feature hierarchy 底层大scale的feature map语义信息少,虽然框出了小物体,但小物体容易被错分:利用了多尺度的特征信息,如ssd

4FPN 特征金字塔 左边和2一样得到多尺度的特征图,右边进行了融合,小尺度的图上采样加上左边的特征图,这么做的目的是因为高层的特征语义多,低层的特征语义少但位置信息多。特征图进行融合。
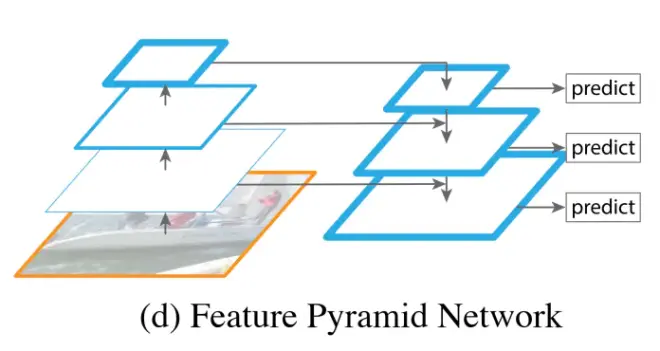

看看fpn怎么使用的,特征图怎么用?ssd怎么预测的?
ssd: 参考链接:视频 特点:在多尺度的特征图上进行预测
在多尺度的特征图上进行预测,预测时,大的特征图用语义信息少,小目标位置信息多,用小号的先验框,预测小目标。小的特征图则用大的先验框,预测大目标。
预测时即特征图上每个像素点有很多通道,组成一个向量。里面包括有分类置信度,xywh相较先验框的位置偏移,用来回归预测的目标。
训练时要注意怎么平衡正负样本,正负样本怎么选择,平衡定位,分类,置信度。里面有很多细节的东西没琢磨。
损失函数看来一般都是分类损失加定位损失。
yolo:
V1:很简单,输入图片,运行模型,输出预测向量7*7*30,包括了每个像素周围的预测,(框+分类+置信度),损失包括定位,分类,置信度,平衡正负样本,大框小框。
V2:特点:通过数据集上聚类得到更合适的先验框。引入anchor box,限制预测框的位置,回归预测框xywh更合理。多尺度训练,同一张图片,以图像金字塔输入模型训练?主干网络先用imagenet训练了分类,调整了主干网络的参数,然后再主干网络下加几层,训练目标检测。分类检测联合训练,扩大到通过分类数据集,能检测9000中物体,如果是输入分类图片,只计算分类损失,如果是检测图片,计算全部损失,里面具体计算细节没琢磨!
V3:网络引入了残差结构。学习了FPN和SSD,多尺度预测,三种尺度特征图进行特征融合,并在三种尺度的特征图上预测,小特征图检测大物体,大特征图检测小物体。主要是对网络结构的改进。
目标检测中训练的问题,实际操作可能效果更好些。
样本不平衡,如果猫的图片比狗的图片多,那模型会倾向于预测猫。
如果预测的正样本过多,负样本太少,比如设置的背景图片少。那么模型可能会把一些只是背景的图片预测为目标。
faster-rcnn:
两阶段怎么训练的?
特征图是语义化的缩小的原图


先提取特征,得到特征图,一端到RPN得到Proposal框,另一端拿候选框进行预测。
mosaic图像增强:把四张图片拼接在一起输入网络进行训练

增加数据多样性,增加目标个数,BN能一次性统计多张图片的参数。
SPP模块:为啥效果好这么多?

IOU: loss为0的时候,就没法分辨预测框随便没重合,但是一个离得近,一个离得远,就无法分辨了

IOU GIOU DIOU CIOU:




focal loss:应对正负样本极不平衡的情况


可不可以正样本不用focal loss,简单易分的负样本计算focal loss?


retinanet:采用resnet+fpn+focal loss

不同尺度怎么权值共享?两个端怎么训练?
注意力机制:(李宏毅的课程)

a是输入的一组向量,Q矩阵乘a,得到query,理解为a的语义。K矩阵乘a,得到key,理解为关联的信息。V矩阵乘a,得到value,理解为传出的信息。然后Q和K求内积,在softmax归一化,得到注意力的分数,a之间彼此是否相关。最后到A的分数乘V,得到传出的B,输出的向量。




多头注意力:也许一组Q和K不足以表现输入之间的相关性,所以引入了多头。q乘以两个矩阵,生成qi1,qi2,k和v也是如此。然后第一组用注意力计算出bi1,第二组计算出bi2,两个bi拼接,矩阵乘,得到输出b。增加一些参数,融合了几组的相关性。
位置编码:注意力机制对于输入a1,a2,a3.。。等等而言,计算是平行平等的,不考虑位置信息,所以注意力能不能加入位置信息,现在还在研究中!





seq2seq: encoder-decoder模型




seq2seq模型可以加上attention,attention表现了对隐向量h的各个部位的注意程度,可以用2维图进行呈现。可以用于NLP,图像的看图说话,取代CNN等等。
有双向,偷窥(skip connection)等等骚操作。

Transformer:复杂版的seq2seq,self attention比lstm好是可以平行化运行,速度更快。transformer的encoder有很多block,每个block输入一排向量,先做self attention,再做FC,输出一排向量。中间可能引入残差结构,做layer normalization。还加上positional encoding,位置信息。把这样的block重复很多次。

autoregressive:出一个,进一个,速度慢,精度高

nonautoregressive:一次性产生,速度快,精度较低,这也是个待研究的大坑




transformer训练部分是大坑,copy mechanism,guided attention,beam search,损失函数不用cross entropy,训练的时候加噪音,很多技巧和大坑
Bert: 预训练模型,transformer的encoder部分,感觉和VGG啥的差不多,加上自己改的部分,然后fine tune

用预训练的模型加上各种定制的方式,来达成任务



一般fine tune下整个模型效果会更好

这个方法也许可以一试
Bert怎么训练的,self supervised training。因为资料库太大,不可能supervised training。

Bert很神奇,不仅可以学到上下文语义的信息,还可以学到各种想不到的信息。但Bert很吃训练集,需要训练集够大。



图像的自监督学习:


Gan:用于比较有创造性的任务。一组向量输入generator,generator输出一张图片。然后把这张图片输入discriminator,discriminator输出一个分数,真图或假图的概率。训练时先generator随机输出假图,然后可以和真图作为二分类任务给discriminator训练。固定住discriminator,把generator和discriminator连接成一个网络,梯度上升训练generator。然后反复迭代。
问题点:神经网络参数很多,相当于一个很高维的系统,而图像是一个低维的系统,所以discriminator高维对低维判断真图和假图很容易。所以需要数据集很多,而且假图的进步不容易量化,因为对discriminator而言都是假的,loss都是一样的。不好训练,难以量化divergence
为什么要有generator?为啥要用一组分布的向量?




内插能不能做图片融合?感觉挺好玩的





gan的训练坑很多啊,一般实操上discriminator训练几次,主要都是训练generator
gan训练比较难,特别是生成文本更难,为啥难?
gan容易出现的问题:


评估gan的性能好不好,1是看生成图质量好不好,把生成图扔到分类网络去,分类网络能给出一个分类很清晰的判断,某class分数很高,很明确知道是啥。2是看大量生成图的多样性,把大量生成图扔到分类网络去,分成的类别要足够多。还要看gan的生成图是不是复制真实图,所以评估Gan还真不好量化。



感觉坑很多,反向生成器网络咋做?人脸间相似度如何计算?等等

auto encoder:自监督学习的方法,训练的模型可以用于下游任务。和cycle gan有点像,图片输进encoder,变成低维的向量,然后通过decoder,返回图片,令原图和生成图距离越小越好。怎么计算两张图相似?





anomaly detection:异常检测的分类






决策树,随机森林?
深度学习的可解释性;




强化学习:相比于监督学习,相比标注资料困难,也不好评判标签好坏的情况,适合强化学习。和gan有点像,actor根据环境产生动作,然后critic根据环境和动作给出奖励,进行调整。















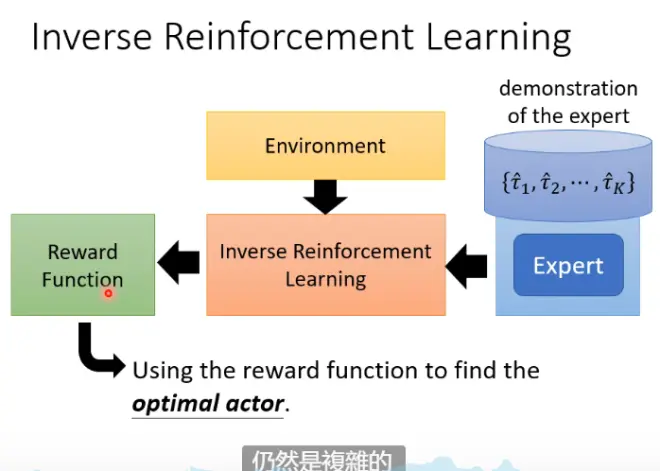



可以先用IRL让机器学出一个reward function。为了让机器做的比人更好,可以在这个reward function上加一些限制,比如速度更快,reward更多。从而让机器更强。
