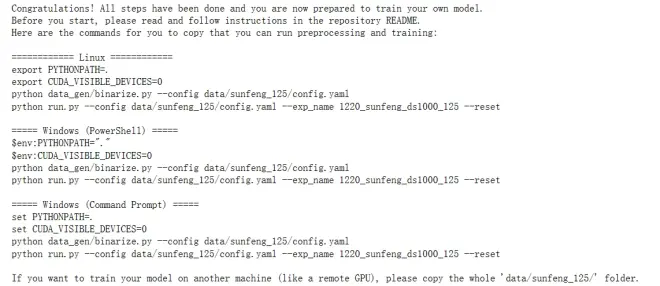
DiffSinger(三)
声库制作
这一部分主要为从训练到推理的全部流程,不打算自己训练的同学无须此部分
最新的语雀更新:https://www.yuque.com/sunsa-i3ayc/sivu7h

硬件需求
1.推理目前分为命令行推理和onnx推理,对速度要求不高的话CPU和GPU均可使用
2.如果想要训练Demo视频级别的模型至少需要20G以上显存的NVIDIA显卡(如RTX3090)
3.云端一般常见的为V100(16G)、V100(32G)、A100(40G)、A100(80G)等显卡,部分云端提供RTX3090等显卡,请确保你使用的显卡为20G以上显存的NVIDIA显卡
4.云端训练请首选Linux系统镜像,不推荐云端使用Windows系统进行训练
模型分为数据集处理、模型训练、模型推理三部分
*实时速度指电脑每秒可以使用模型处理n秒的音频,如4分钟音频耗时1分钟处理完毕,实时速度为4x
*加速推理为模型自带功能,同硬件下牺牲音质,提高推理速度
以i5-8300H为例,CPU的实时速度约0.1-0.5x,3分钟歌曲转换耗时5-30min不等
以1060-6G为例,GPU的实时速度约1-10x(取决于不同模型和加速设置),3分钟歌曲耗时30s-5min
*onnx模型搭配openutau可以使用AMD显卡加速推理
准备工作
为了训练模型你需要提前准备好以下数据
一、对应训练类型的分支代码
目前常用的分支为
https://github.com/openvpi/DiffSinger/tree/refactor
二、对应训练类型的声码器
最新声码器的下载地址:https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
如果加载过慢可以使用https://d.serctl.com/搭配idm等多线程下载程序进行加速下载
或者下载群内【实验权重】下的文件

解压后放到仓库目录下的checkpoints文件夹
三、数据准备
我们推荐各位对高质量音声授权素材进行训练,实际训练中请注意素材来源的版权问题。
*制作流程不涉及显卡且云端CPU性能一般较弱,建议本地制作
数据要求
一、单人模型
准备总长度约为2~5h(或以上)的获得授权的单人汉语普通话干声素材,尽量不要有混响和底噪,否则建议使用其他工具先进行预处理;干声保存为单声道wav格式,至少16bit位深,并需要保证16kHz以下频段完整。如想达到较好的效果,建议覆盖更广的音域、曲速和发音,但尽量保证所有素材的风格、声线相近。歌声最佳,语音亦可,但纯语音数据需要注意音域问题。(推荐进行响度匹配)
二、组合模型
如果多人训练组合模型,部分数据可以时长要求降低,但是需要进行响度匹配
数据处理
一、响度匹配教程
请确保你在本地安装好AU(需要自行获得),本教程使用AU2018演示
启动AU
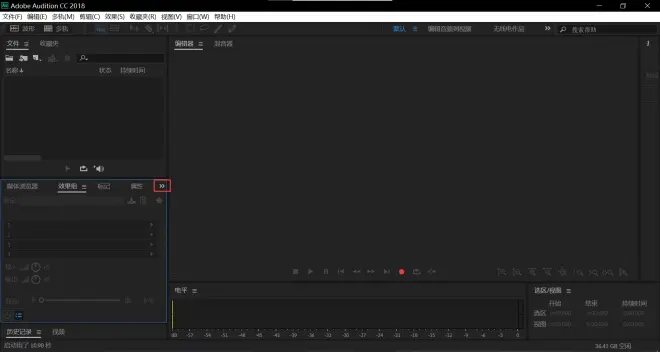
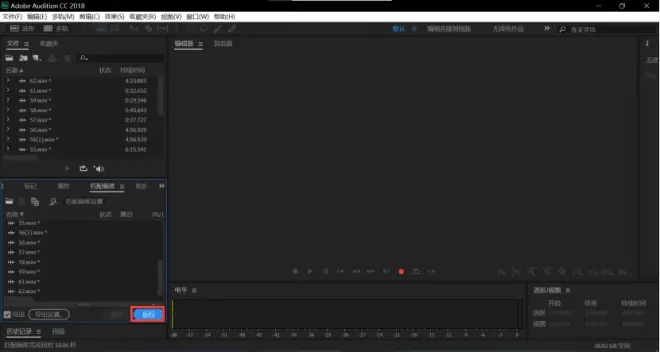
点击红框部分
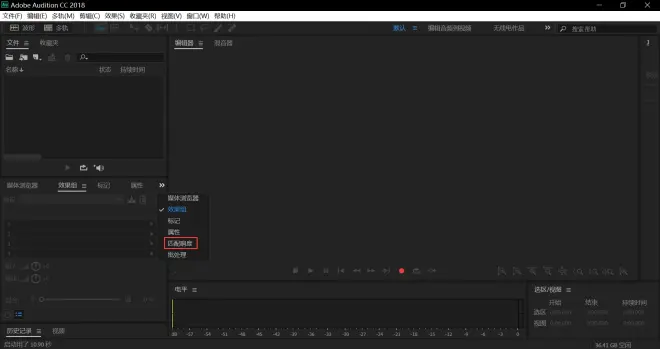
若你的版本在工具栏中没有响度匹配,请按照以下步骤来走
点击效果
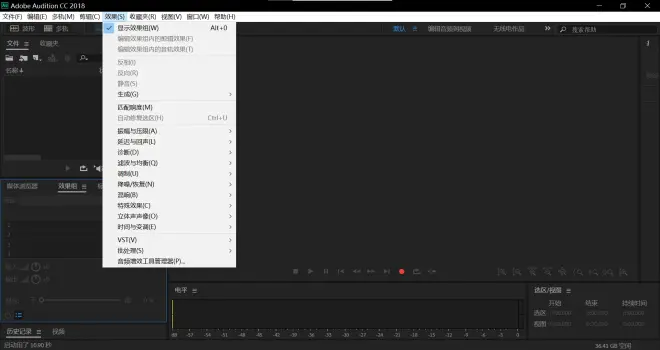
点击匹配响度
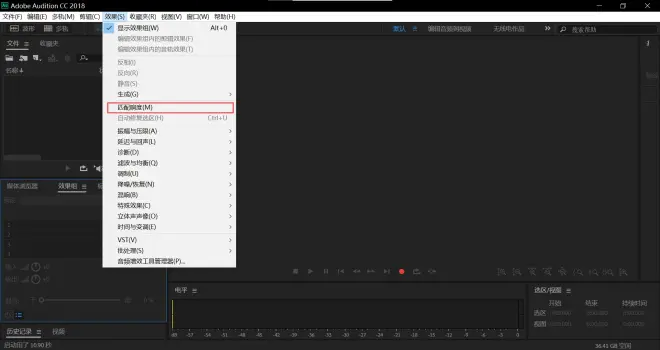
拖拽音频到如图所示处
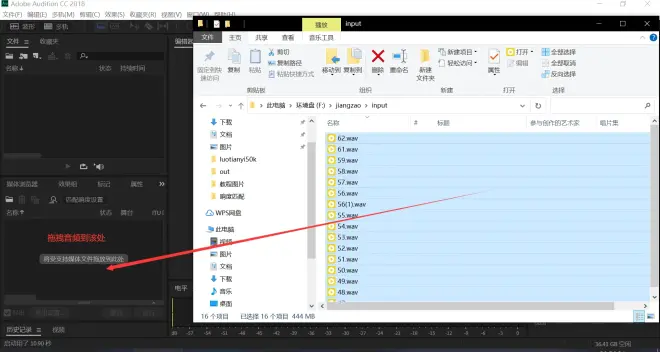
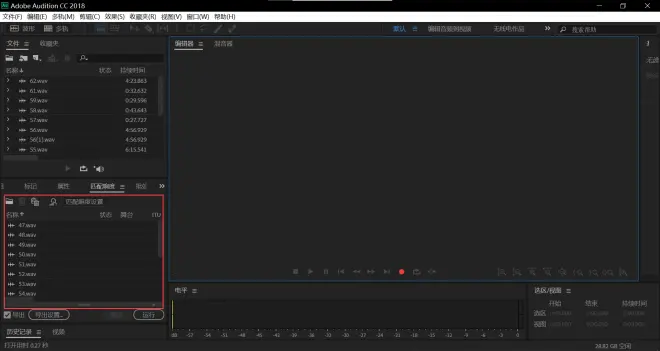
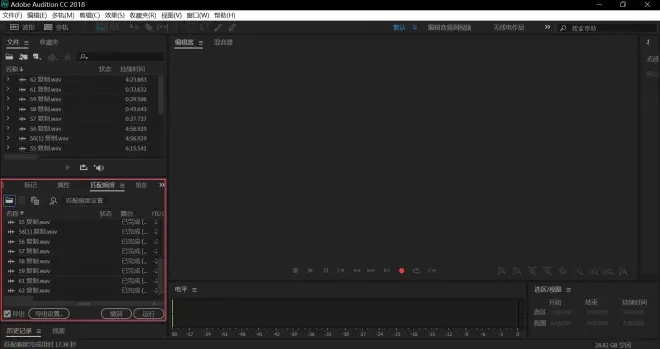
点击导出设置
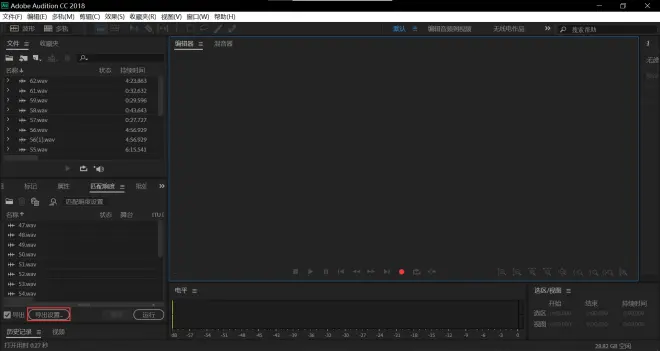
点击浏览
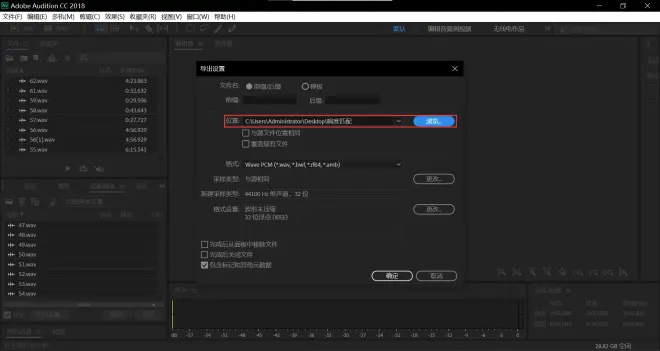
选定你存放音频的文件夹并点击选择文件夹
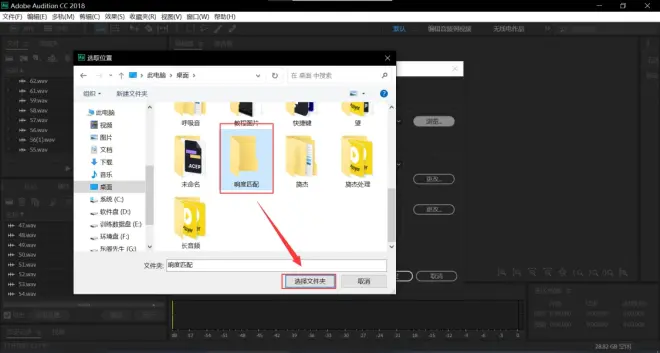
点击确定
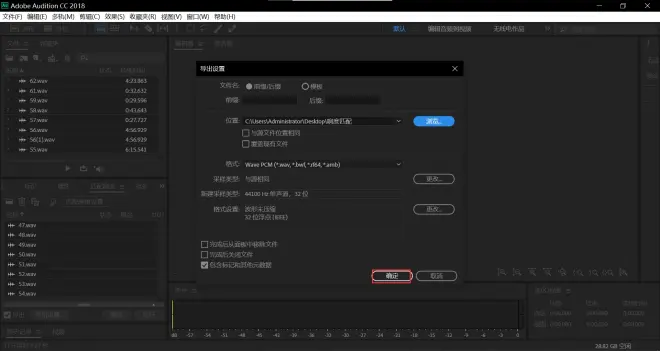
点击运行并耐心等待处理完成
二、数据切分
数据集制作流程中已包括切分,但为了效果,我们仍建议先行切分
使用自动音频切片机将干声素材切为每片5-15s的小片段
请注意:为了后续使用方便且避免后续报错,使用切片机前请将文件重命名为英文或英文数字组合形式
例如:song.wav song2023020001.wav等,请不要含有()外的字符
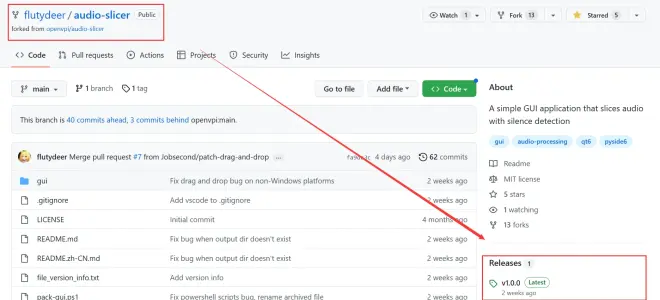
GitHub:https://github.com/flutydeer/audio-slicer
下载点击方框内链接下载GUI并等待下载完成
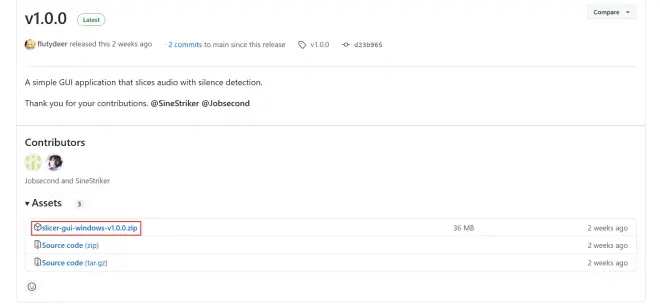
若下载过慢,可以使用https://d.serctl.com/搭配idm等多线程下载程序进行加速下载(群内同样可以获得)

打开文件夹并双击启动slicer-gui.exe
点击 Add Adudio Files 或者将音频文件拖入窗口
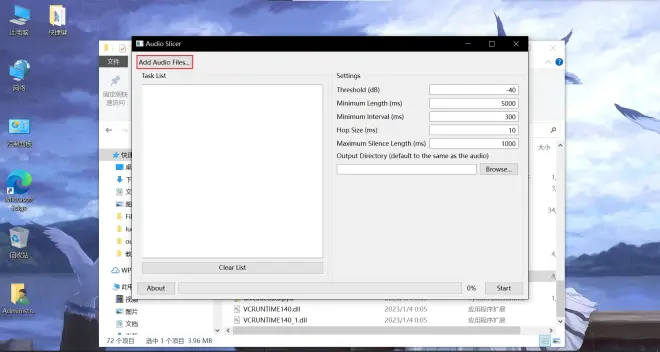
Ctrl+A全选你的音频并点击打开或者拖入窗口
接下来是一些参数介绍
请根据自己的需求调整,若完全不懂这些参数是做什么的,请不要随意修改,以免造成切片效果不佳
该数值表示:以 dB 表示的 RMS 阈值。所有 RMS 值都低于此阈值的区域将被视为静音。如果音频有噪音,请增加此值。默认值为 -40。
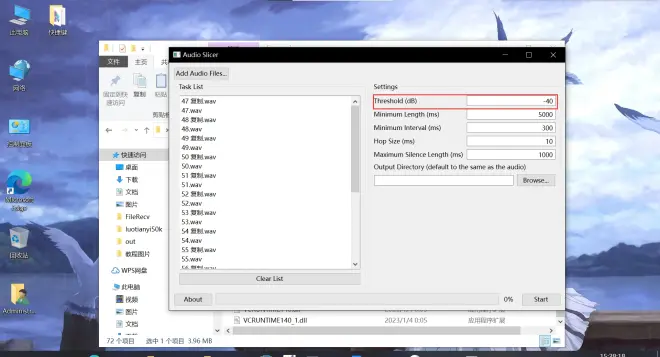
该数值表示:每个切片的最小长度,以毫秒为单位。默认值为 5000。
该数值表示:要切片的静音部分的最小长度,以毫秒为单位。如果音频仅包含短暂的中断,请将此值设置得更小。此值越小,应用生成的切片音频剪辑可能就越多。请注意,此值必须小于 min_length 且大于 hop_size。默认值为 300。
该数值表示:每个 RMS 帧的长度,以毫秒为单位。增加此值将提高切片的精度,但会减慢该过程。默认值为 10。
该数值表示:在切片音频周围保持的最大静音长度,以毫秒为单位显示。根据需要调整此值。请注意,设置此值并不意味着切片音频中的静音部分具有完全给定的长度。如上所述,该算法将搜索要切片的最佳位置。默认值为 1000。
该选项为选定音频输出文件夹,请点击Browse点击并选择你的导出文件夹。留空则输出到源文件的位置。
强烈建议导出到其他文件夹以防止数据混淆
点击start并耐心等待切片完成
接下来请将你的数据按照大小排序,使用AU手动切片15s以上的长音频分别导出
对应教程链接:
https://blog.csdn.net/topia_csdn/article/details/115405605
请注意,导出音频格式应当统一为WAV,采样率默认为原音频采样率!
请确保你的数据无混响,听感清晰并无噪音,这些都将影响你的最终模型成果!
三、数据标注
现在,你需要按照上面的示例进行标注,并且满足以下条件:
在标注文件中,你需要写下对应音频中演唱或说出的所有音节
音节需要用空格分开,并且只允许出现在字典中的音节
特别说明:请不要标注AP(呼吸) 和 SP (停顿)在标注文件中
注意事项:请不要标注汉语拼音以外的拼音序列
Tips.略要标注为lve
下载群文件里的MinLabel
Windows下解压即用
它可以读取音频和同名【.lab】,如果同目录没有【.lab】会自动在同目录创建同名文件
使用时需要选择你使用的默认播放
输入中文歌词,粘贴,点击Replace(快捷键是回车)自动生成对应拼音(需要自行检查)
点击Append会在已有拼音后面新增歌词栏的拼音
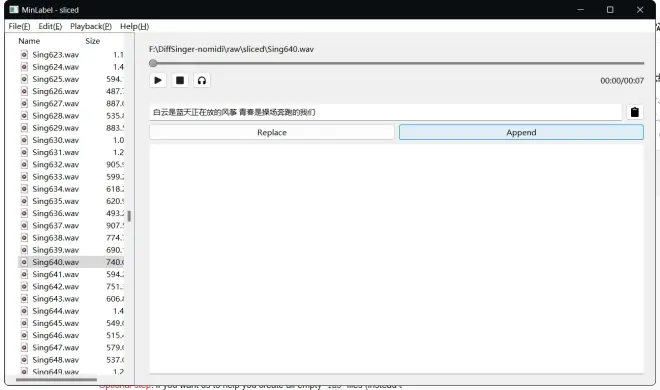
按PgUp和PgDn可以切换上下音频,切换后会自动保存
数据集制作
1.下载并安装Anaconda
如果你擅长于此也可以选择MiniConda
*MFA在Windows下必须使用Conda虚拟环境
点击链接,下载windows64版anaconda:
https://mirrors.bfsu.edu.cn/anaconda/archive/Anaconda3-2022.10-Windows-x86_64.exe
双击启动
点击next
点击 I agree
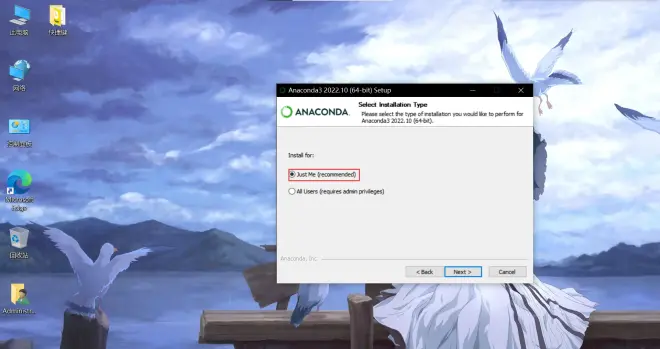
点击just me
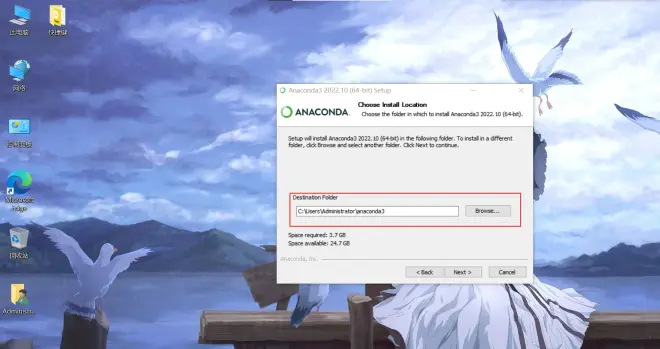
默认安装在C盘(如果空间紧张也可使用其他路径,避免中文路径)
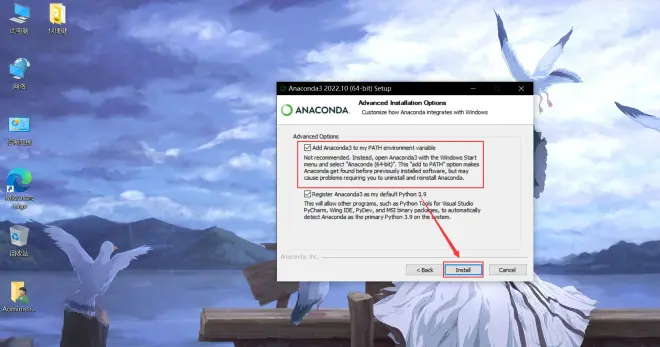
请务必选择add path!
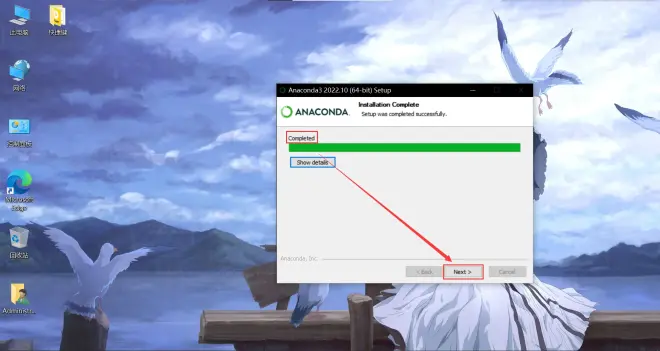
点击install并耐心等待下载完成
下载完成,点击next退出
2.Anconda换源
如果官方源过慢,可以自行搜索anconda换源进行操作,本教程不对此部分进行答疑
3.打开终端
后续Windows下所有打开终端均是指此操作
1.点击桌面【Win】徽标或按下键盘上【Win】徽标键
2.找到Anaconda3
3.找到Anaconda Prompt(Anaconda3)
4.打开


为了避免和其他项目产生依赖冲突,我们需要为数据集制作创建一个虚拟环境,该虚拟环境通用于接下来所有制作相关教程。
如果你已经创建了适用于DiffSinger的虚拟环境,你通常无须再次创建
一、创建个Python 3.8的虚拟环境
如果你已经创建了适用于DiffSinger的虚拟环境,你通常无须再次创建
请直接下滑到【二、安装jupyter】
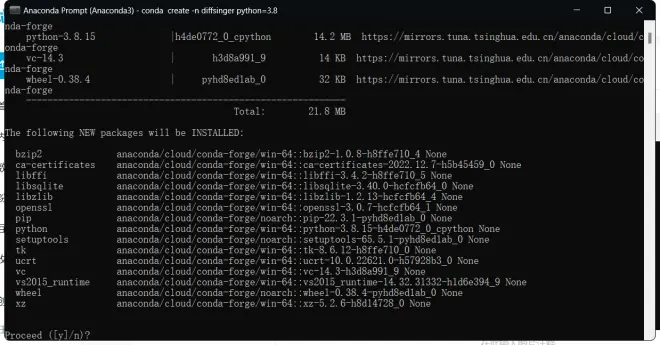
1.输入:
conda create -n diff python=3.8
按下回车键 ,diff是虚拟环境的名字可以换成任何英文和拼音名,只要你记得住就行。
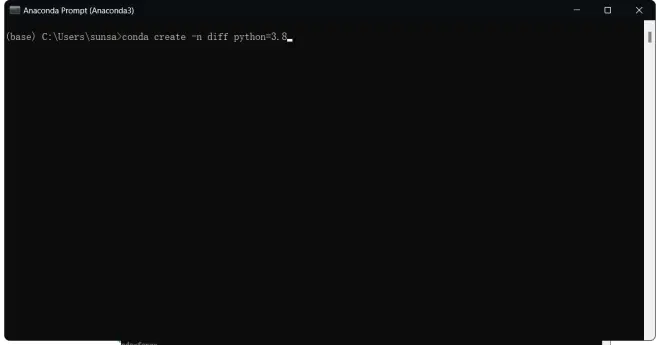
等待conda查找所需组件,完毕后会显示下图内容
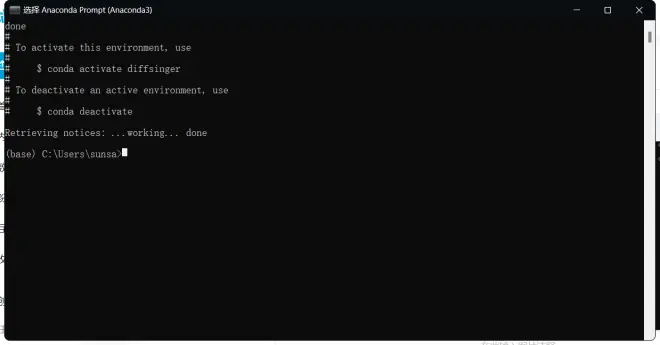
输入:
y
按回车键开始安装,等待下载和安装完成
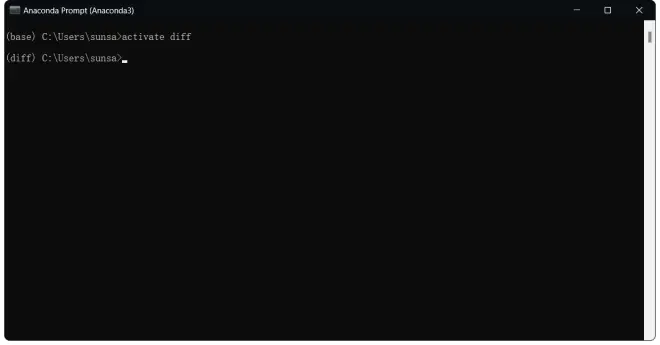
输入:
activate diff
回车,切换到刚刚创建的虚拟环境
每次重新打开conda终端都要切换到项目对应的虚拟环境,看到开头由base变为diff就说明切换到虚拟环境了
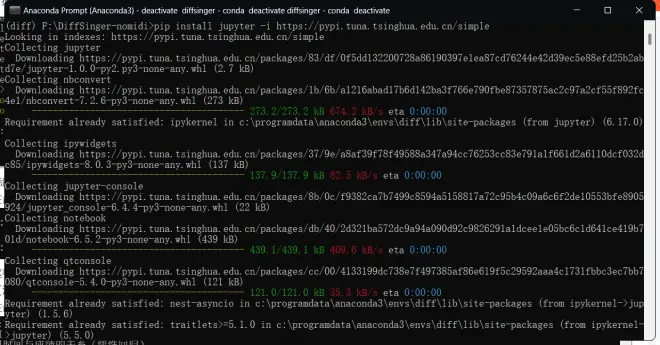
二、安装jupyter
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple
回车,安装jupyter(这里你也可以选择下载VSCode等支持jupyter的项目)
三、创建kernel
为了让我们部署过的环境在ipynb中也能使用
输入
conda install ipykernel
回车(如果刚刚运行了jupyter使用快键键Ctrl+C即可终止运行)
conda查找完成后输入
y
回车
等待安装完成后输入
ipython kernel install --user --name diff
回车(这里的diff也是选择你自己喜欢的名字)
五、获取制作数据集的notebook
OpenVPI团队维护的DiffSinger-refactor仓库地址
https://github.com/openvpi/DiffSinger/tree/refactor
推荐使用git指令以获取最新更新
git clone https://github.com/openvpi/DiffSinger/tree/refactor
如果点击code下载zip
如果你无法流畅访问GitHub导致下载过慢,你可以右键【Download ZIP】复制链接到
https://d.serctl.com
下载
把下载完成的压缩包解压到任意目录(路径不能有中文)
Conda输入:
cd 你解压的DiffSinger-refactor仓库的地址
切换到DiffSinger-refactor仓库
这里如果你解压在非C盘路径,可能会出现cd后无变化的情况
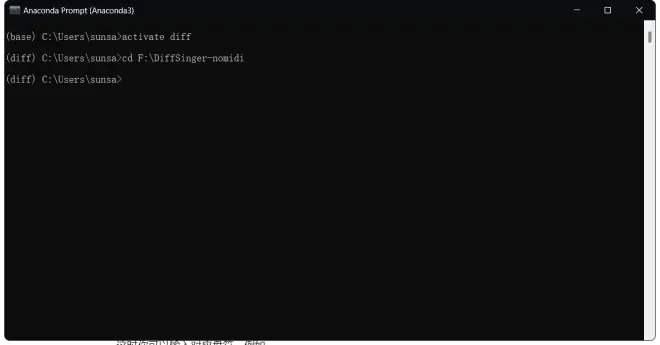
这时你可以输入对应盘符,例如
f:
回车
*请根据自己情况操作
前言
已更新多歌手/声线,更新最新代码后参阅第五条进行设置即可
注:若声线变化丰富,推荐区分声线;若多个人需要制作,推荐使用多人组合
(若未制作过单人数据集,请按照流程继续)
如果您完成数据集制作和声库训练后认为此教程对您有帮助或者DiffSinger的合成效果令您满意,欢迎您在发布相关声库作品时在简介中附带本教程链接和DiffSinger(OpenVPI维护版)的GitHub仓库链接。
同时,我们也欢迎您在简介中简要说明声库的大致情况,例如:
训练数据总时长
数据类型(歌声还是语音、数据来源、数据质量等)
训练使用的设备
训练总步数
更改过的超参配置
这将有助于我们考察模型在更多样化的数据集上的表现。
以上内容仅仅是建议性的,没有强制要求。欢迎与我们分享您在制作数据集与训练声库过程中的任何感受。
一、打开notebook
*执行下列操作前请确保你已经按照前面教程cd到代码目录

(图片仅供参考,具体为你的路径)
在命令行输入
jupyter notebook
回车
点击pipelines
点击no_midi_preparation.ipynb
点击Kernel

点击Change Kernel,选择diff(之前环境准备中你创建的)
二、运行notebook
0.使用说明
点击“代码所在格子”,被选中的“格子”会改变颜色,点击上方的【run】即可运行相应代码
1.前期准备
1.2安装依赖
*仅在初次运行时需要使用
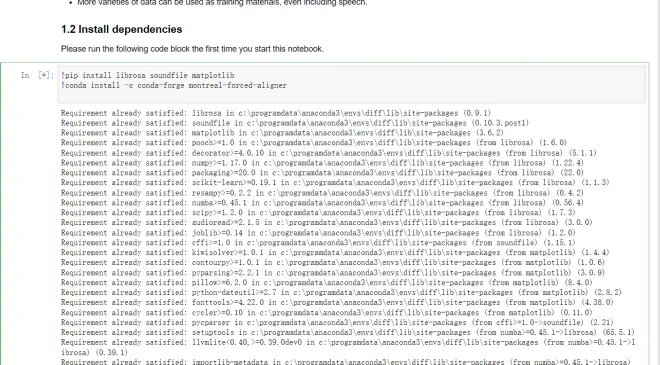
MFA安装较慢,需要耐心等待,你也可以分别复制!后内容在conda命令行中手动安装
安装完成后
这里会有显示
*手动安装前记得点击【run】旁边的停止来停止运行
*手动安装需要重新打开一个命令行
1.3初始化环境
每次使用时都需要运行
运行成功后会输出

2.数据处理和切片
请保证你的数据满足以下条件
位于同一个文件夹中,暂不支持多层结构。
格式为【. wav】。
采样率高于 32000Hz。
只包含来自人类的声音,并且只包含一个人的声音,暂不支持多说话人训练
没有明显的噪音或混响
*可选步骤提示
原始数据必须切成单个文件大约 5-15 秒,如果前面你已经完成此操作,从第 2.3 开始
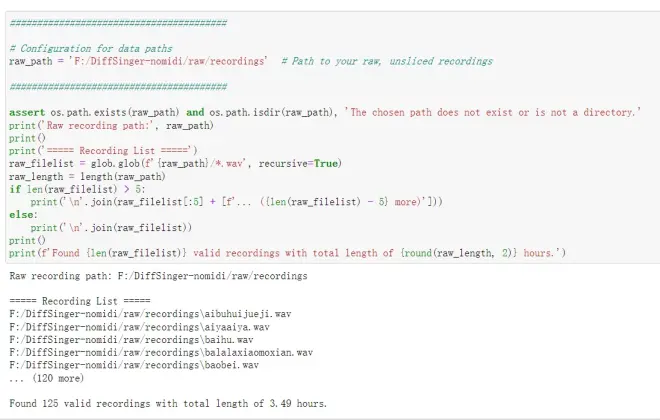
2.1配置数据路径
你需要将''中的内容修改为你的原始数据路径

这边的做法是在项目根目录创建raw文件夹,在里面创建recordings文件夹并将音频复制进去

*需要注意的是直接在windows文件管理器中复制的话,路径中是【\】需要手动修改成【/】
2.2切分数据
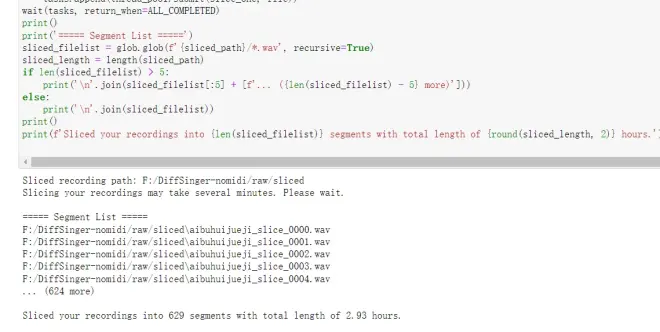
你需要将''中的内容修改为你想要的切分后的数据保存路径
*请不要和上面一致

这边的做法是在raw文件夹中新建sliced文件夹

可能需要一段时间,具体时间取决于你原始音频的数量和时长

完成后
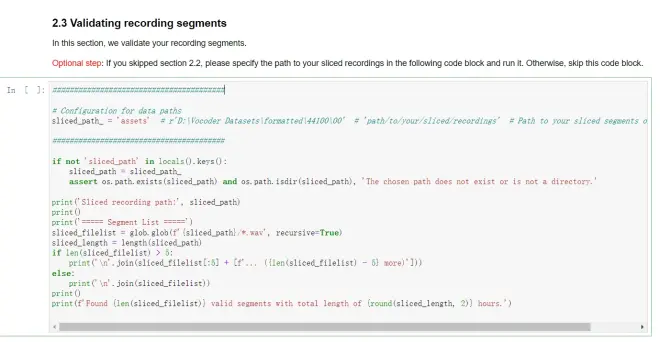
2.3验证数据
这一部分将检查你的数据是否可用
*可选步骤提示
如果你前面跳过了2.1和2.2,请先在这里设定你存放数据的路径
路径示例为:F:/Diffsinger-no-midi/raw/sliced
运行后
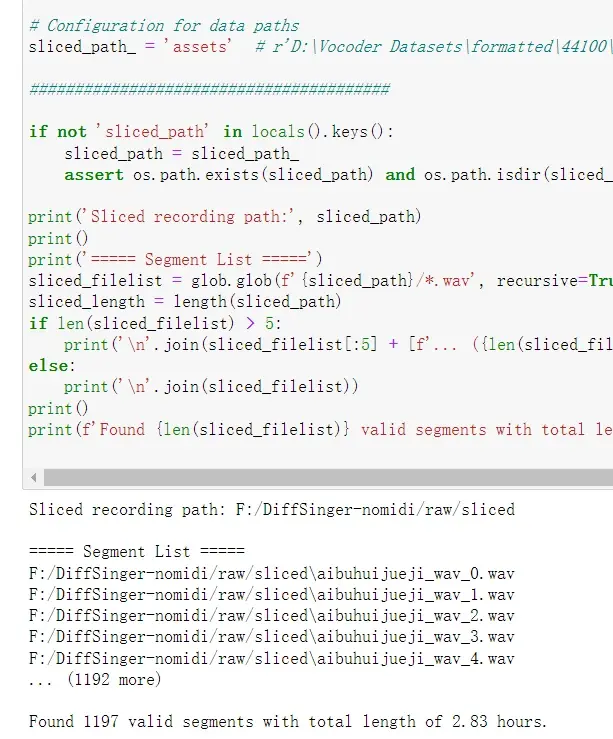
该格的作用为检测是否有2s以下或者20s以上的音频
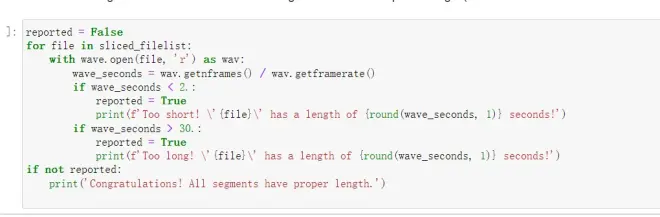
*手动步骤提示
这里你需要手动去除过短语音或者将其拼凑成长语音,过长语音需要手动裁短,直到运行后显示下面内容
3.标记数据
3.1标注拼音序列
运行此格查看示例
*手动步骤提示
如果你已完成请直接运行3.1.1
现在,你需要按照上面的示例进行标注,并且满足以下条件:
每个音频都有一个与其文件名相同的 【.lab】标注文件,并放置在相同的目录中
在标注文件中,你需要写下对应音频中演唱或说出的所有音节
音节需要用空格分开,并且只允许出现在字典中的音节
同时,标注中需要包含字典中的所有音素
特别说明:请不要标注AP 和 SP 在标注文件中
注意事项:请不要标注汉语拼音以外的拼音序列
P.S.运行以下代码块会自动生成所有音频对应的空白【.lab】文件
P.P.S.这里由【zjzj】和【YQ之神】为大家提供了一个小工具
Windows下解压即用
,它可以读取音频和同名【.lab】,如果没有【.lab】会自动创建同名文件
初次使用如果没有声音,需要选择你使用的默认播放
输入中文歌词,粘贴,点击Replace(快捷键是回车)自动生成对应拼音(需要自行检查)
点击Append会在已有拼音后面新增歌词栏的拼音
按方向键可以切换上下音频
3.1.1标注检测
运行以下代码块检查是否所有语音都已标注以及所有标注是否有效
如果检查失败,请修改并重新运行检查
同时会生成音素覆盖范围的摘要
如果某些音素的出现次数极少(例如,少于 20 次),强烈建议添加更多录音以涵盖这些音素
3.2强制对齐
通过给定每个片段的标注,能够将音素序列与其相应的音频对齐,从而获得每个音素的位置和持续时间的信息
这里使用MFA进行强制音素对齐
运行以下代码块,将会把重新采样的录音将和音素标签保存于你pipelines/segments路径下,同时会创建临时用于存储的pipelines/textgrids/文件夹
*请勿修改路径
*此操作将会覆盖这两个文件夹的全部内容,请提前备份
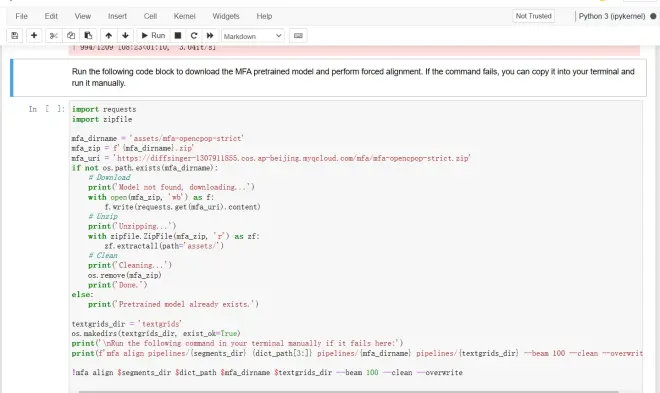
运行以下代码块,将会下载并解压缩预训练的 MFA 声学模型并进行强制对齐,如果运行失败可将命令复制到终端继续运行
*可能会有错误,报错一般意味着你的数据集切片过长、部分切片字数过多或者存在很离谱的标注错误,请先检查你的数据和标注;
*加大beam前可以尝试先重新运行一下,有概率解决
如果确定标注无误,可以调大--beam后面的数字再次尝试(会导致精度下降)
*下一步如果报错某个(些)TextGrid文件not found的话,缺少的文件对应的音频和拼音标注也可能存在很严重的标注错误,同样请检查数据后回到这一步重新处理
*如果你检查后修改了个别标注和音频,你需要重新从2.3节开始运行程序

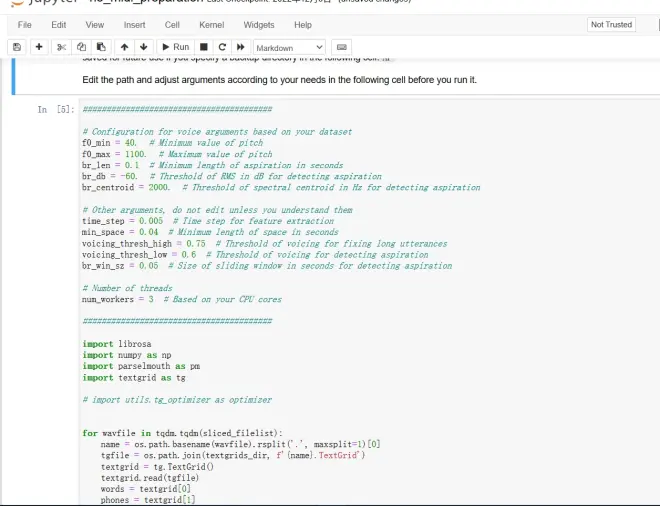
3.3优化对齐结果
运行前根据实际情况修改参数
*如果你的数据集是男声,你可以调小f0_min和f0_max这两个值(Hz),女声反之,这样音高分析会更加准确
*br_db可以根据实际情况来修改,如果你的数据集录音有底噪(尤其是中高频的底噪)实在没有去除,你可以把这个值适当调大
*其他的参数除非你看懂了是干什么用的,否则不要乱动,保持默认即可
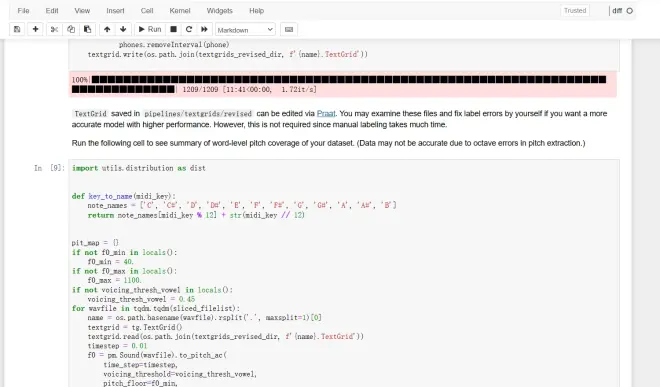
*保存在pipelines/textgrids/的TextGrid可以通过Praat进行编辑。如果您想要更准确的模型和更高的性能,可以检查这些文件并自行修复标签错误。(非必须,仍需耗费大量时间)
*但仍然建议有条件的话随机打开几个TextGrid大致看一下音素时长有没有标准了,尤其是呼吸AP有没有识别准确,SP空白的位置有没有出现特别离谱的错误。如果你觉得标得不准,请调整一下参数再重新运行
运行下面单元格可以获得大致音域分布
P.S.如果你的音域过窄
在按照【4.1】制作完单人数据集后
1.申请OpenCPoP数据集(https://wenet.org.cn/opencpop/download/)
2.按照之前流程进行响度匹配
3.下载群里标注文件

4.把数据按照
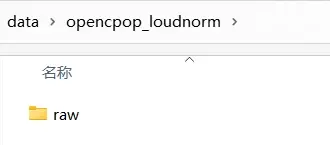
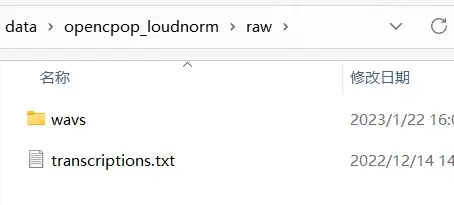
结构放置
*注意:其中【transcriptions.txt】要使用群里标注文件的内容(改成这个名字就行)
5.然后在下面按照【5】继续运行
4.数据集的最终构建
恭喜,只要再完成以下几个步骤就能完成数据集的最终构建
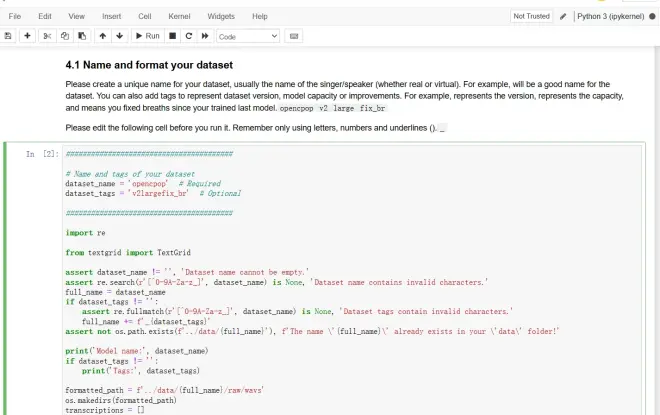
4.1数据集的名称和格式
请为您的数据集创建一个唯一的名称,通常是歌手/中之人的名称(无论是真名的还是圈名的)。例如,opencpop。您还可以添加标签来表示数据集版本、模型容量或改进。例如,v2表示版本、large表示模型规模,fix_br表示相比于上次训练的模型修复了呼吸声问题
*请在运行之前编辑以下单元格
*请记住只能使用字母、数字和下划线
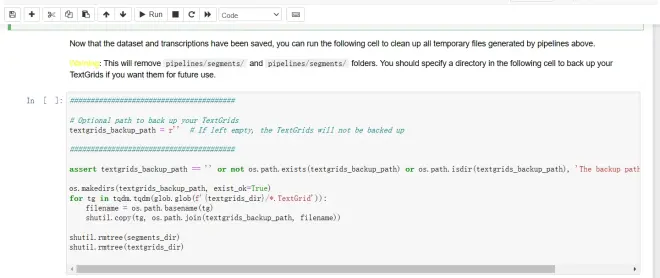
运行下方单元格进行清理
*该操作会清空pipelines/segments和pipelines/textgrids/文件夹,如果你想备份,请指定一个备份用的目录再运行
4.2超参文件配置
在这里,你可以配置一些用于预处理、训练时所需的神经网络的参数。
*如果提示CUDA out of memory,先检查是否有15s以上过长数据,如果没有优先修改max_tokens和max_sentens,请不要修改residual_channels和residual_layers,除非你确定有能力进行后续处理。
eg.最长数据20s,max_tokens52000,max_sentences48的情况下显存占用大概22G左右,使用3090即可训练
*如果需要制作多人数据集,请跳转到5
阅读下面的说明并运行以下单元格。
4.2.1 神经网络参数
1. residual_channels和residual_layers
这两个参数是指扩散解码器网络的宽度和深度。一般来说,表示模型容量。较大的模型在训练和推理时消耗更多的 GPU 内存并且运行速度较慢,但它们会产生更好的结果
基础的版本384x20
大网络版本512x20
训练所需的 GPU 内存:
基础的版本 - 至少 6 GB(建议 12 GB)
大网络版本 - 至少 12 GB(建议 24 GB)
2. f0_embed_type
f0有【离散】和【连续】两种嵌入方式。离散(discrete)嵌入采用从 50Hz 到 1100Hz 的 256 个bin,并使用 torch.nn.Embedding 嵌入,连续(continuous)嵌入将 f0 转换为连续 mel 频率,并使用 torch.nn.Linear嵌入。
离散嵌入已经过长时间的测试,并保证稳定。连续嵌入尚未经过广泛测试,但在音高范围的极端边缘观察到一些改进。
4.2.2 数据增强
数据增强可提高模型的性能或功能,但可能会增加训练数据的大小
1.random_pitch_shifting
启用后,对数据进行随机变调,而不是在预处理时保留共振峰。此外,每条数据被变调的key将被嵌入到网络中。这将扩大音高范围,并允许在推理时控制帧级键移动(如 VOCALOID 中的 GEN 参数)。
这种类型的扩充接受以下参数:
range控制将随机移动的音高键的范围。
scale控制将应用扩充的数据量。
𝐷𝑎𝑢𝑔𝑚𝑒𝑛𝑡𝑎𝑡𝑖𝑜𝑛=(1+𝑠𝑐𝑎𝑙𝑒)⋅𝐷𝑜𝑟𝑖𝑔𝑖𝑛𝑎𝑙
2.fixed_pitch_shifting
启用后,数据的音高将固定变调。这些带有变调的数据将被标记为与原始数据不同的说话人,从而使模型成为组合模型。这也将扩大音高的范围(可能比随机音高转换略好)。这种增强与随机变高不兼容。
这种类型的扩充接受以下参数:
targets控制变调的目标数量以及将向每个目标移动的键数。
scale控制每个增强目标将应用于的数据量。
𝐷𝑎𝑢𝑔𝑚𝑒𝑛𝑡𝑎𝑡𝑖𝑜𝑛=(1+𝑠𝑐𝑎𝑙𝑒⋅𝑐𝑜𝑢𝑛𝑡(𝑡𝑎𝑟𝑔𝑒𝑡𝑠))⋅𝐷𝑜𝑟𝑖𝑔𝑖𝑛𝑎𝑙
4.2.3 训练和验证
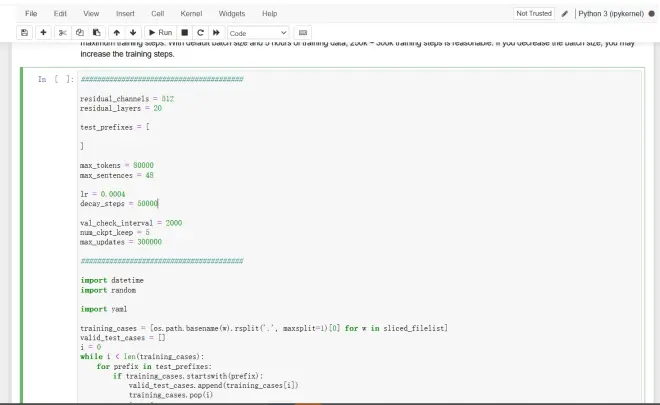
1. test_prefixes
此列表中指定的名称前缀的所有文件都将放入测试集中。每次保存检查点时,程序将首先在测试集上运行推理,并将结果放在 TensorBoard 上。因此,你可以收听这些演示并判断模型的质量。如果添加的测试用例少于 10 个,则会自动随机选择更多用例。
2. max_tokens和max_sentences
这两个参数共同确定训练时的batch size(bs),前者表示一个batch中的最大帧数,后者限制最大batch。较大的bs在训练时消耗更多的 GPU 内存。此值可以根据你的 GPU 内存进行调整。切记不要将此值设置得太低,因为小bs可能导致模型不收敛。
3. lr 和decay_steps
这两个值是指每次学习率衰减时的学习率和步数。如果你减小了bs大小,则可以考虑使用较小的学习率和更多的衰减步数。
4. val_check_interval, num_ckpt_keep和max_updates
这三个值是指验证和保存检查点之间的训练步骤、保留的最新检查点数以及最大训练步骤数。使用默认bs大小和 5 小时的训练数据,250k ~ 300k 的训练步长是合理的。如果减小bs大小,则可能会增加训练步骤。
5. permanent_ckpt_start和permanent_ckpt_interval
这两个值负责控制训练中永久检查点的保存。通常情况下,只有最新的 num_ckpt_keep 个模型会被保存,其他的模型会全部被清理。这是为了在程序报错、崩溃或进程被杀、设备故障、实例被收回等造成训练意外中止的情况下能够保存最新的训练结果。但这样的机制无法应对模型意外过拟合(训练过头)的情况,也不方便进行不同训练步数的对比。
设置这两个值后,程序将从第 permanent_ckpt_start 步开始(最开始的若干步通常没什么意义,全是噪声和缺陷),每隔 permanent_ckpt_interval 步保存一个永久的模型。这样的模型不会被当作旧模型删除,因此你无需时刻盯着炼丹炉,这些模型可以供你事后对比和选择。
要启用永久模型保存,请确保这两个值都是 val_check_interval 的正倍数。
保存永久模型会占用更多硬盘空间,所以你也可以把 permanent_ckpt_interval 设置成 -1 来关闭这个功能。
5.组合模型的配置
*如果你仅使用一份数据,无需执行此操作
如果你有多个数据集,则可以使用它们训练组合模型,以获得更好的性能和覆盖率。此外,你还可以通过一个模型在不同的演唱者/风格/音色等之间切换,甚至可以随着时间的推移以任何比例、静态或动态混合它们中的任何一个。
本节将指导你为此类模型创建配置文件,以便你可以从多个数据集运行联合预处理和训练。
注意:在训练组合模型之前,你必须获得每个数据集的版权所有者的许可,并确保所有这些提供者都完全了解你将从他们的数据中训练组合模型,你是否会分发合成的声音和模型权重,他们的声音是否会被用于混合, 以及其他的潜在风险。
5.1.选择数据集
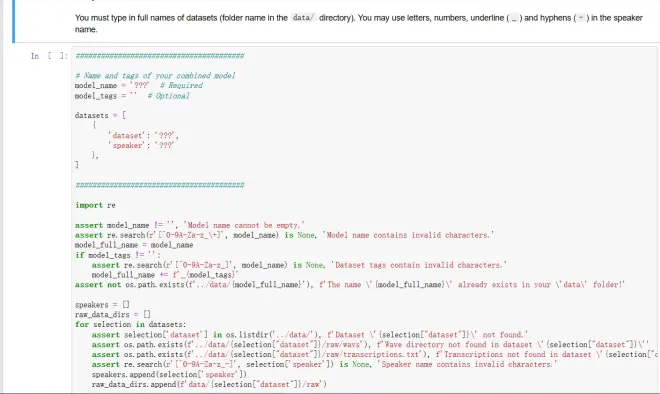
在以下单元格,你可以选择数据集并为你的组合模型命名
1.model_name和model_tags
类似于第 4.1 节中描述的dataset_name和dataset_tags,但在这里您可以在模型名称中使用 +。例如,female_triplet 和 alice+bob 。
2.datasets
你可以使用数据集的全名指定数据集,并为每个数据集设置说话人名称(speaker)。例:

注意:必须键入dataset的全名(data/ 目录中的文件夹名称)。你可以在speaker中使用字母、数字、下划线 (_) 和连字符 (-)。
5.2 配置参数
组合模型的大多数参数与第 4.2 节中所述相同,但存在以下差异。
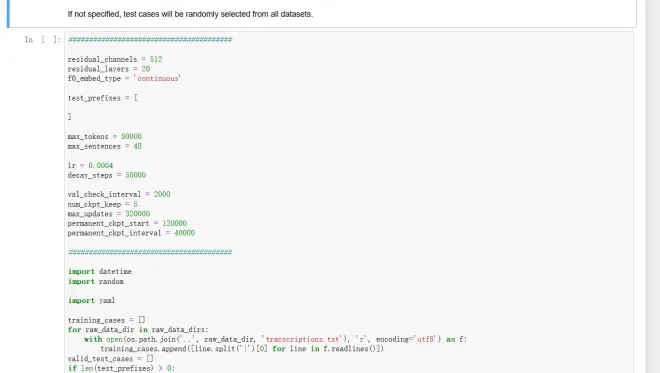
1.test_prefixes
您可以使用波形文件的前缀或全名,在此参数中带或不带说话人 ID。例如:
xxx 将完全匹配任何选定数据集中的一个文件名,如果没有,则匹配以 xxx开头的所有文件名。
0:xxx 将完全匹配第一个数据集中的一个文件名,如果没有,则匹配该数据集中以 xxx 开头的所有文件名。
如果未指定,将从所有数据集中随机选择测试用例。
6.完成
现在你可以参考输出结果进行训练步骤了
*请参考你自己的输出结果