
VQ-VAE——离散化特征学习模型

本文首发于网站 机器翻译学堂
转载事宜请后台询问哦
译者|黄鹏程
单位|东北大学自然语言处理实验室

前言
VQ-VAE是一个强大的无监督表征学习模型,它学习的离散编码具有很强的表征能力,最近比较火的文本转图像模型DALL-E也是基于VQ-VAE的。
在具体介绍VQ-VAE模型前,需要先介绍一下该模型的前身工作AutoEncoder模型以及VAE模型。
1.1 AutoEncoder
自编码器Auto-Encoder是无监督学习的一种方式,可以用来做降维、特征提取等。其模型结构如图1.1.1所示:

从模型图中可以很明显的看出,对于AutoEncoder模型,采取的是无监督训练的方式,对于输入的经过一个Encoder层后得到一个特征向量
,再将该向量
通过一个Decoder层得到最终输出
,通过最小化重构模型的输入
和模型的输出
的误差作为损失函数训练模型得到一个较好的关于输入
的特征向量
,模型设计的初衷的获得一个对应于源数据
的一个低维特征向量
,在获得此向量的基础上可以应用在很多分类任务上,但是AE模型并不适用于生成任务。
尽管AE已经可以获得较好的向量表示,在还原任务上可以做出较好的效果,但其并不是一个生成式模型,这是因为对于一个生成模型而言,他一般需要满足两个条件限制:
1.生成模型的编码器和解码器是可以分离开的;
2.对于固定维度下任意采样出的编码,解码器都能产生一张真实且清晰的图片。
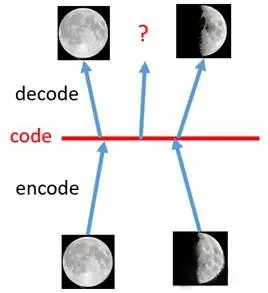
AE模型并不满足第二点的条件,举个例子来说[2],对于输入的全月图和半月图,通过对AE模型的训练可以很好的完成还原任务,但是我们对于二者特征向量中取一个点,对于一个正常的生成模型而言,应该生成一个介于全月和半月之间的图片。然而,对于真实的AE而言,它生成的结果要么是乱码要么就是异常模糊的图片。为什么会发生这种情况呢?因为模型在训练的时候并没有显性对中间变量的分布
进行建模,在模型训练时所采用的
是有限的,而对于
所处的空间存在大量
外的点而言模型是并不理解的,如果像该例子随机在全月和半月中采样一个点,大概率得到不能够生成有效图片的点。
1.2 VAE:Auto-Encoding Variational Bayes
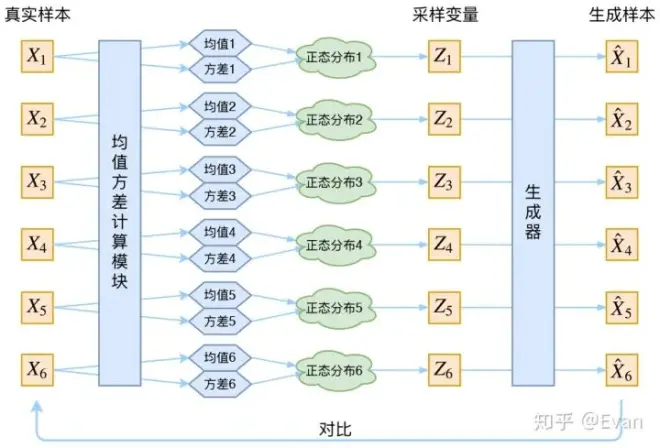
既然介绍过了AE模型存在的一些问题,我们为什么不给定一个简单的分布呢?这样我们就可以通过神经网络的方法去学习一个模拟分布的映射,再通过这个学习到分布就可以完成生成任务了,这就是VAE所用到的思想了。我们假设
~
,其中
代表一个单位矩阵。也就是说,我们将
看作是一个服从标准多元高斯分布的多维随机变量,对于训练样本中的每一个
,通过Encoder模块获得对于该样本的均值和方差,即对于每一个
而言,获取其对应的分布
,如图1.2.1所示,将得到的每一个
混合起来,即可得到数据的大致分布,如图1.2.2所展示的一样,那么之前存在的问题就解决了,既然获得了
的分布
,那么想实现生成任务就可以从样本空间中随机采样再送给Decoder进行生成任务,本文的重点并不在于VAE,因此对于其细节、公式就不一一推导了,感兴趣的可以自己看看论文。

VQ-AVE:Neural Discrete Representation Learning
2.1 Introduction
终于来到了本文的重点了,VQ在这里的含义为vector quantised,即将VAE做量化,也可以称为离散化,那为什么要使用离散化的VAE呢,根据论文所言(which are potentially a more natural fit for many of the modalities),根据我个人理解,虽然自然界的各种信号不论是图像还是语言,他都是连续的,大部分任务都是一个回归任务,但当我们处理这些问题时,往往是将问题离散化后再进行处理,如图像划分成像素、语音也是经过抽样,回归任务也变成了分类任务。
在这里也一样,如果使用VAE的方式,样本的分布并不是很好学,VQ-VAE就使用了一个codebook去替代了VAE中学习样本分布的过程,我们假设codebook是
维的,其中
是指codebook的长度,一般设定为8192维,而
则是每一位向量的长度,一般设为512,如图2.1所示,codebook的长度
可以简单的理解为codebook对于
个聚类中心。
模型经过Encoder后,得到一个的特征图,然后我们就将特征图的向量去与codebook中的
个向量作比较,将最相似的
的
存入特征矩阵
中,再通过
和codebook得到一个新的特征图
(即量化后的特征),之后的流程又和AE相似了将这个新拿到的特征图通过Decoder获取新的生成图片
,尽量让
和
相似,这样就完成了VQ-VAE模型Encoder和Decoder部分的训练,其流程可以简单的划分为如下的几个步骤:
1.将一张图片送到Encoder后,会得到一个的feature map,即图2.1所示
;
2.将Encoder得到的中的
个
维的向量分别与codebook中的
个向量分别计算相似度,找到最近的
,用index表示,得到
的特征矩阵
。
3.对于特征图中的每个index用codebook对应的隐变量
表示,得到新的feature map,即图2.1中的
,该特征图作为Decoder的输入,最终通过Decoder得到重构后的图片。

2.2 Training
接下来来到了模型的训练环节,模型的整体损失函数如下所示:
它由三部分组成:
1.第一部分为重构损失(reconstruction loss),与Autoencoder的训练loss一致,都是通过最小化重构模型输入
以及Decoder部分。
正常来说,Encoder输出的每一个词向量需要从codebook中找到最相似的词向量来代替他送入Decoder完成计算。这个“选择”的过程自然是不可导的,也就是说,目前的计算方式会导致Encoder无法计算自己的梯度,自然无法训练。对于这个问题,作者采用了Straight-Through思想,直接将原本能够正常计算出来的codebook身上的梯度直接作为Encoder的梯度,即
。(Straight-Through最早出自Benjio的论文《Estimating or Propagating Gradients Through Stochastic Neurous for Conditional Computation》它想说的就是前向传播的时候可以用不可导的变量参与计算,而反向传播的时候,用为它特别设计的梯度来更新它的参数。)如果有朋友对于这个操作还不太理解的话可以看看下面这段代码(此代码取自vq-wav 2vec)。
这段代码中的ze代表Encoder的输出,zq代表codebook的输出,detach的作用为将该变量从计算图中剥离出来,这会导致它只会参与前向计算,而在反向计算的过程中,它没有任何梯度,因此它的参数不会被更新。
这段代码的作者没有直接把zq送给vq vae的Decoder,而是先通过一个_pass_grad函数。我们再来看_pass_grad函数,这个函数的作用就是将原本能够正常计算出来的codebook身上的梯度直接作为Encoder的梯度,即
。它的具体做法是计算了一个zq.detach()
+(ze-ze.detach()),这种方式就会使得函数返回的结果是,而
的值因为自己减自己就没了。同时,其中一个ze通过detach消除了他身上的梯度,因此梯度可以被传递到另一个ze身上。相反,如果我们直接计算ze - ze的话,那么ze身上就不会产生任何梯度。代码的作者通过这种方式实现Straight-Through使得Encoder能够被正常训练到。
注:有朋友可能会想x - x.detach()是合理的,那么为什么_pass_grad是y.detach() + (x - x.detach())而不是y + (x - x.detach())?这其实是vq-wav 2vec的代码作者复现vq vae原作者所说“Due to the straight-through gradient estimation of mapping from to
,the embeddings
receive no gradients from the reconstruction loss
."而设计的。但实际上,我也尝试了y+(x-x.detach()),发现这时候模型也是正常训练的,并且
与
完全相同,符合之前的所有设计,因此仅用这个reconstruction loss就实现了Encoder、codebook、Decoder三者一起进行训练。但是为了更好地介vq vae,我们接下俩还是按照y.detach()+(x-x.detach()),也就是Straight-Through导致的
为零来讲解。
2.第二部分为codebook loss。我们前边说了,由于straight-through gradient estimation of mapping from ze(x)to zq(x),因此codebook并不能通过
获得任何梯度。对于这个问题,作者使用了vector quantisation(VQ)算法,即增加一个新的loss,来最小化
和embedding
之间的
距离,这会使得
即codebook接近encoder的输出,以此来训练codebook。公式中
表示stopgradient operator,即在前向计算的时候保持相应的量不变,但在后向计算的时候使得梯度为0(也即pytorch中的detach方法)。这么说的有点抽象,让我们直接看看代码是如何实现的:
代码的作者通过mseloss来计算zq和ze之间的距离,同时按照公式中的将ze使用detach从计算图中剥离,因此这个loss产生的梯度只会被传导到zq身上。这段代码的含义就是只更新codebook的参数使得其与
接近。
3.第三部分称为commitment loss,即原文中的(To make sure the encoder commits to an embedding and its output does not grow,we add a commitment loss,the third term in equation 3)它只训练模型的Encoder部分,个人理解其目的是为了让Encoder的输出稳定在一个codebook聚类,不在codebook里面乱跳,作者通过实验发现最后的结果对于
并不敏感,故设置了一个0.25的值。对于这个loss的计算代码如下:
在训练好VQ-VAE后,我们并不能直接使用VQ-VAE模型的Decoder用作生成式任务,还需要训练一个先验模型来实现数据生成,拿图像来举例子,论文中采用的就是PixelCNN模型,与以往不同的是,PixelCNN模型的输入并不是图像所对应的pixels,而是VQ-VAE模型学到的那个离散编码。首先,我们需要使用已经训练好的VQ-VAE对训练图像进行推理,得到其相对应的特征矩阵这个特征矩阵在一定程度上保留了输入图片的位置信息,所以我们在这里可以用自回归模型如PixelCNN,来对特征矩阵
,再通过codebook得到相应的特征图
,最后经过Decoder就可以生成图片了。[4]
2.3 Experiments
2.3.1 lmage
作者首先展示了重构的效果,如图2.4.1所示:

从图像上可以看出重构出来的图基本和原图一致,印证了使用离散隐变量的方式重构图片还是效果不错的。
随后再使用的latent space去训练PixeICNN,从PixeICNN提取的样本被VQ-VAE的Decoder映射到像素空间,可以在图2.4.2中看到。

2.3.2 Audios
作者在VCTK上进行实验,decoder使用了类WaveNet的架构。
由于是multi-speaker dataset,decoder中还输入了spekaer-id。
Reconstruction的结果如图2.4.3所示:

原论文中给出了sample page,感兴趣的同学可以去听一下。
听了之后可以发现虽然reconstruct audio的style会和原audio有不同,但是内容是相同的。这说明VQ-VAE在没有text信息进行监督的情况下也能学习到语音中的关键信息,且忽略了一些low-level的信息。
之后作者使用WaveNet重新学习了prior,然后进行了sample,作者发现模型可以生成比较清晰且流畅的语音,这说明VQ-VAE实际上只使用语音数据就学习到了一个phoneme-level language model。
作者也进行了speaker conversion的实验,即使用不同的speaker-id进行decoding,作者发现模型可以生成内容相同但speaker不同的语音,这说明encoder排除了speaker相关的信息。
最后作者也尝试将每个embedding映射到最有可能的phoneme上,这里有128个latent variable,41个phoneme,最终得到的映射的accuracy为49.3%,这比起random的情况(7.2%)要好很多,这说明VQ-VAE学习到的latent variable中包含的信息和phoneme很类似。[5]
2.3.3 Videos
从图2.4.4可以看出,该模型已经学会了在不降低视觉质量的情况下成功生成以给定动作为条件的帧序列,同时保持局部几何形状的正确性。

2.4 Conclusion
讲完了VQ-AVE的大致思路,我们会发现,现在学习到的又是一个固定的codebook,这也意味着它又没办法像VAE一样,通过随机采样生成图片,准确的说VQ-VAE并不像一个VAE,而更像一个AE,它学习到的codebook适用于类似分类的任务而不是生成任务,如果想要VQ-VAE做生成任务,就需要像论文里提到的一样,再训练一个prior网络,利用codebook实现图像的生成任务。
引用
[1]知乎:https://zhuanlan.zhihu.com/p/58111908
[2]知乎:https://zhuanlan.zhihu.com/p/112513743
[3]知乎:https://zhuanlan.zhihu.com/p/249296925
[4]苏剑林. (Jun. 24, 2019). 《VQ-VAE的简明介绍:量子化自编码器 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/6760
[5]知乎:https://zhuanlan.zhihu.com/p/382305612

hi,这里是小牛翻译~
想要看到更多我们的文章,可以关注下
机器翻译学堂(公号或网站)
笔芯~

往期精彩文章


