
监控警戒区基于掩码算法的简单实现(附代码)
效果视频讲解见连接:https://www.bilibili.com/video/BV1By4y1y7Vw/
这是利用图片掩码实现的一个视频监控区域警戒功能代码,当人进出警戒区域时,自动记录一张图片到本地。
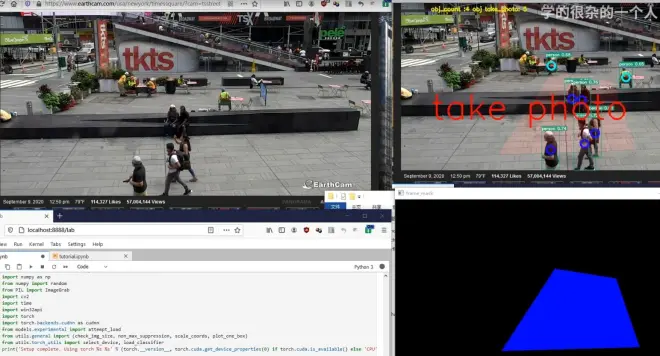
按代码功能主要分为三个部分:
1、动态截屏
2、yolov5目标检测
3、掩码生成及检测目标是否进出该区域
完整代码:
#动态截图,识别目标,设置并记录警戒区域的目标
import numpy as np
from numpy import random
from PIL import ImageGrab
import CV2
import time
import win32api
import torch
import torch.backends.cudnn as cudnn
from models.experimental import attempt_load
from utils.general import (check_img_size, non_max_suppression, scale_coords, plot_one_box)
from utils.torch_utils import select_device, load_classifier
print('Setup complete. Using torch %s %s' % (torch.__version__, torch.cuda.get_device_properties(0) if torch.cuda.is_available() else 'CPU'))
# Initialize
device = select_device()
frame_h = 480
frame_w = 800
obj_count = 0 #警戒区目标
obj_count_old = 0 #警戒区旧目标
take_photo_num = 0;#拍照次数
#每个监测不一定都检测得到,所以做个缓冲区用于取平均值,因为要避免某帧的目标丢失,会造成目标数量的跳变,引发拍照记录
obj_count_buf = np.array([0,0,0,0,0,0,0,0,0,0])#10个值
# Load model
model = attempt_load('weights/yolov5s.pt', map_location=device) # load FP32 model cuda
# Get names and colors
names = model.module.names if hasattr(model, 'module') else model.names
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(names))]
#imgsz = check_img_size(486, s=model.stride.max()) # check img_size
frame_mask = np.zeros((frame_h,frame_w, 3),dtype = np.uint8)#做一个相同尺寸格式的图片mask
postion = [(413,179),(275,391),(632,381),(571,204)]#警戒区位置点
CV2.fillPoly(frame_mask, [np.array(postion)], (0,0,255))#警戒区内数字填充255,0,0成为mask
def process_img(original_image):#原图处理函数
processed_img = CV2.cvtColor(original_image,CV2.COLOR_BGR2RGB)#BGR格式转换RGB
processed_img = CV2.resize(processed_img,(frame_w,frame_h))#改变输入尺寸
return processed_img
def MouseEvent(a,b,c,d,e):#鼠标处理事件响应函数
if(a==1): #获取左键点击坐标点
print(b,c)
CV2.namedWindow('frame')
CV2.setMouseCallback('frame', MouseEvent) # 窗口与回调函数绑定
while(1):
# get a frame
frame = np.array(ImageGrab.grab(bbox=(0, 100, 800,600)))
if np.shape(frame): #frame有数据才能往下执行
#processing
frame = process_img(frame)
img = frame.copy() #img为gpu格式,常规方法不能读取,im0为img的copy版可直接读取
#print("img:",np.shape(img))
img = np.transpose(img,(2,0,1))#torch.Size([480, 800, 3])转torch.Size([3, 480, 800])
#print("img:",np.shape(img))
img = torch.from_numpy(img).to(device)
img = img.float() # uint8 to fp32
img /= 255.0 # 0 - 255 to 0.0 - 1.0
#print(np.shape(img))#>>>torch.Size([3, 416, 352])
if img.ndimension() == 3:
img = img.unsqueeze(0)#这个函数主要是对数据维度进行扩充,在0的位置加了一维
#print(np.shape(img))#>>>torch.Size([1, 3, 416, 352])
pred = model(img)[0]
# Apply NMS 非极大值抑制
pred = non_max_suppression(pred, 0.5, 0.5)#大于0.4阈值的输出,只显示classes:>= 1,不能显示0?
#绘图
if pred != [None]:
for i,det in enumerate(pred):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round()
# Write results
for *xyxy, conf, cls in reversed(det):
if cls == 0:#只显示0(person)的标签,因为non_max_suppression(只显示classes:>= 1)的标签
label = '%s %.2f' % (names[int(cls)], conf)
plot_one_box(xyxy, frame, label=label, color=colors[int(cls)], line_thickness=1)#utils.general专用画框标注函数
xy = torch.tensor(xyxy).tolist()#张量转换成列表形式
x,y,x1,y1 = int(xy[0]),int(xy[1]),int(xy[2]),int(xy[3])#获取左顶右底坐标
center_xy = (int(np.average([x,x1])),int(np.average([y,y1])))#计算中心点
if (frame_mask[(center_xy[1],center_xy[0])] == [0,0,255]).all():#中心点在警戒区
obj_color = (255, 0, 0)#改变中心点颜色
obj_count += 1
else:
obj_color = (255, 255, 0)#改变中心点颜色
CV2.circle(frame, center_xy, 10, obj_color, 4)#开始画点
obj_count_buf = np.append(obj_count_buf[1:],obj_count)#保持更新10个缓冲区
cbr = int(np.around(np.average(obj_count_buf)))
CV2.putText(frame, 'obj_count :%s obj take_photo: %s'%(cbr,take_photo_num), (100, 20), CV2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 255), 2)#文字信息显示
frame = CV2.addWeighted(frame,1.0,frame_mask,0.1,0.0)#叠加掩码图片进实时图
if (obj_count_old != cbr) :
take_photo_num += 1
CV2.imwrite("./photo/%s.jpg"%take_photo_num, frame, [int(CV2.IMWRITE_JPEG_QUALITY),50])#保存图片
print('take photo number :%s'%take_photo_num)#显示记录的照片张数
CV2.putText(frame, 'take photo', (100, 300), CV2.FONT_HERSHEY_SIMPLEX, 3, (0, 0, 255), 3)#文字信息显示
obj_count_old = cbr #保存上个数据
obj_count = 0#目标显示清零,等待下次探测
# show a frame
#CV2.imshow("capture", frame[:,:,::-1])
CV2.imshow("frame", frame)
CV2.imshow("frame_mask", frame_mask[:,:,::-1])
if CV2.waitKey(1) & 0xFF == ord('q'):
break
CV2.destroyAllWindows()
