
Stable Diffusion 汽车绘图初探一(基础创作)

一、概述
这两周迷上了AI绘图,出了千把张图,今天简单总结下两周来的经验。
首先,对Stable Diffusion(以下简称SD)感兴趣的朋友可以在B站秋葉aaaki的空间里找到基础教程和整合包
感谢秋葉aaaki的整理和无私分享!
使用SD离线整合包需要至少4G显存,显存越大越好。我所使用的4090显卡拥有24G显存,为我的学习提供了强大的支持。另外运行SD除了显卡外,对硬盘空间也有较大的需求。
安装好SD整合包后,首先需要安装SD模型Checkpoint(ckpt),ckpt是AI深度学习过程中的保存状态,然后可以导出按照特定意向和风格训练的模型供AI绘图时进行参考。在C站(https://civitai.com/)上有许多别人已经训练得比较成熟的模型,可以看到页面上热度较高的模型大都是用于生成小姐姐的,有写实和卡通等各种风格的模型,帅到不行。ckpt文件通常较大,单个文件2G-5G不等。除了SD模型外,还有一种相对较小的模型LORA,LORA模型主要用于特定风格的训练,不像SD模型那样需要满足全局的需求,因此通常较小,需要搭配SD模型一起使用。
C站上大部分的模型都是面向生成人物而训练的,只有非常少数面向建筑和产品的模型。产品设计目前只有一个用户eddiemauro分享的模型,包括1个ckpt模型和若干个LORA模型。最初我只下载了他提供的eddiemauro V2.0版本的ckpt模型和LORA模型进行创作。
二、Stable Diffusion 汽车设计基础创作
安装好SD整合包和模型后,接下来我们开始创作!
如图1所示,在左上角的“Stable Diffusion模型(ckpt)”中选择eddiemauro分享的SD模型“productDesign_eddiemauro20.safetensors”,同时在边上的“模型的VAE”中选择“vaeFtMse840000Ema_v100.pt”。VAE具体介绍和下载可参考该视频, 再往右是“Clip跳过层”,具体可见该视频。
接着选择“文生图”,下方第一栏是正向提示词(prompt),填入你想要生成图的意向风格关键词。开始时不懂怎么填可以用C站作者提供的一些样例图的模板,上面都用提供一些参考图。这里大家可以先使用样例(https://civitai.com/images/973642?modelVersionId=85831&prioritizedUserIds=719134&period=AllTime&sort=Most+Reactions&limit=20)的提示词:
3D product render, futuristic vehicle, finely detailed, purism, ue 5, a computer rendering, minimalism, octane render, 4k
第二栏的反向提示词(Negative prompt),就是你希望避开哪些不想生成的要素,比如:
EasyNegative, (worst quality:2), (low quality:2), (normal quality:2), low-res, ((monochrome)), ((grayscale)), cropped, text, jpeg artifacts, signature, watermark, username, sketch, cartoon, drawing, anime, duplicate, blurry, semi-realistic, out of frame, ugly, deformed,
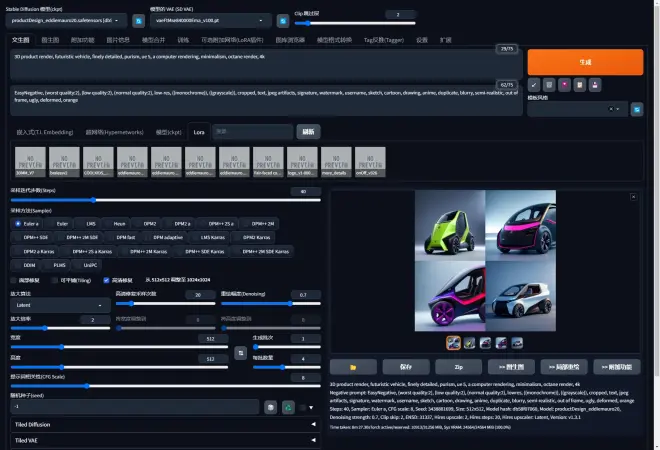
可以看出提示词中有不少是用于约束生成图的品质的,关于产品风格的词其实并不多,这也为AI创作提供了较大的空间。
接着往下是“采样迭代步数(Steps)”,就是你希望通过特定的“采样方法(Sampler)”计算多少步来生成图,步数越多,图也会更精细,但精细到一定程度通常就不会有太大变化了,因此步数太高也没有太大意义。因此通常步数设置在20-40左右即可。采样方法有比较多的方式,具体可以参考样例选择特定的采样方法,也可以自己测试比较,这里我们选择跟样例一样的"Euler a"。
接下来选择图的宽度和高度为“512”,AI绘图时对图的大小非常敏感,长宽1024看似只是512的2倍,但计算时间会有几何倍数的增长,同时也非常考研显存容量。因此出Draft图时512是一个比较合适的选择,太小则细节会太模糊。
“生成批次1”,“每批数量4”是一个相对来说比较合适的选择,每次能够自动生成一张4方图可以对结果做横向比较。
“提示词相关性(CFG Scale)”比较好理解,就是希望生成的结果与提示词的相关度。这个参数比较关键,如同中国古老的哲学“过犹不及”,并不是一味高就是好的,过高的数值会让AI难以权衡,最后生成的结果往往比较生硬,通常在6-8左右就可以取得比较理想的结果。
所有数值就绪后,按下右上橙色的”生成“按钮,静静等待结果,可以看到第一次生成的图品质还是非常不错的。选择其中一张比较满意的,可以继续往下进行”图生图“
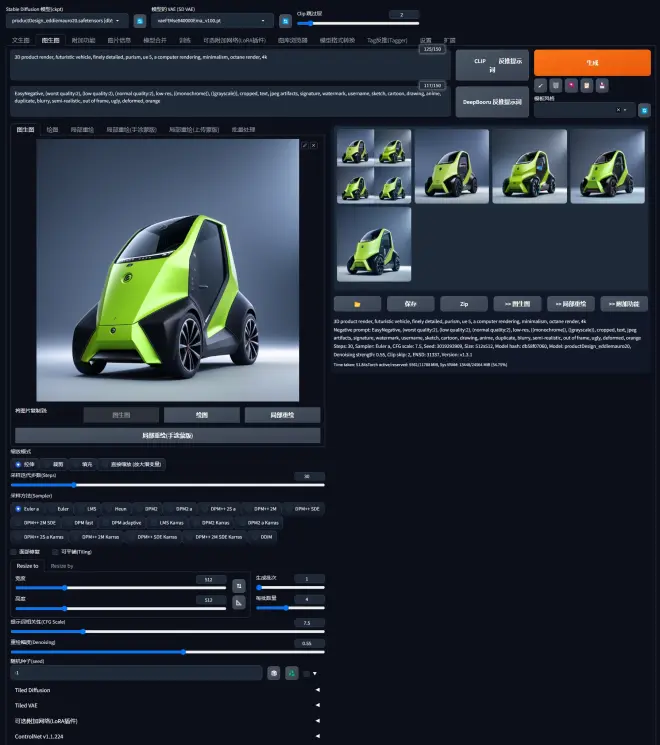
在图生图页面中,会有一个增加的参数“重绘幅度(Denoising)”,这个参数决定了重新生成的图与原图的差异度,数值越高,结果变化越大,反之亦然。如图2所示,选择0.55出现的结果其实已经变化很大了。
如果结果不满意,可以进行多次重绘。如果找到一张满意的结果,可以点击结果图片右下方的“附加功能”,对其进行放大。如图3所示,选择放大的比例,还有两次放大的模型“Upscaler1“和”Upscaler2”,以及可见度等参数。具体可以见该视频。
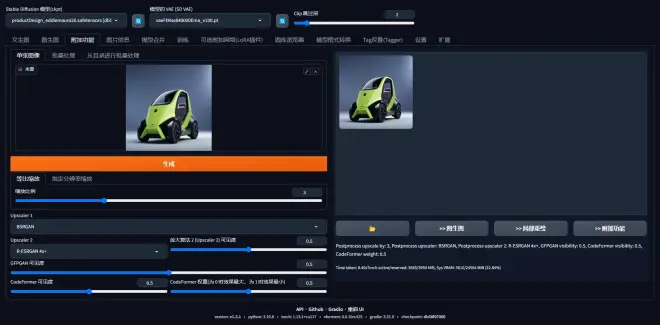
点击生成结果图片下方的打开文件夹图案的按钮,可以找到这张放大后的图(图4),第一次生成的效果如何?

其实这张图本身还是有不少问题,主体摆放位置太靠下,细节还有很多不够精致的地方。如果多生成几次,结合一起其他方法,是可以获得更高质量的图的。
三、根据已有的风格进行创作
接着我又想,文生图毕竟是随机生成的,灵活度很高,但是我想试试按照自己的想法来生成特定方向的造型风格。于是我找了一个我在很多年前创作的童车效果图,如图5。

这次我想试试看不用的SD模型结合LORA模型会有怎样的结果,于是我选择了一个新的SD模型“deliberate_v2”,添加了一个能够体现技术美的LORA“(Tech minimalism-eddiemauro) ”(https://civitai.com/models/59816/product-design-tech-minimalism-eddiemauro-lora),LORA模型添加可见视频。
在上一次的提示词基础上添加了“city commuting, concept, crab, huge wheels, K-car, show something special”。其中的“Crab”主要是用于风格导向,希望生成的车身能够带有一些甲壳类动物的特征。提示词尾添加LORA模型<lora:eddiemauroLora2(Tech):0.3>,这里的“0.3”指LORA模型占的权重,具体可参考模型制作者介绍来自行调整。
采样迭代步数(Steps)改为20,提示词相关性(CFG Scale)7.5,重绘幅度(Denoising)0.45,结果如图6。

整体风格很酷,不过主体变得比较的激进和夸张,不是我想要的那种比较温和的变化,继续修改下参数。将采样迭代步数(Steps)改为30,重绘幅度(Denoising)改为0.35,试着换一个简洁风格的LORA模型minimalism-eddiemauro(https://civitai.com/models/58902/product-design-minimalism-eddiemauro-lora),LORA权重仍为0.3,得出如图7的结果,感觉好像比较符合预期了。

四、总结
由此可以得出结论,所有基础的SD模型其实都可以用于生成产品效果图,因为本身SD模型训练都是出于全局的考虑,在合适的提示词的帮助下,都能够生成比较理想的结果。适当的LORA对风格影响能够起到很好的辅助作用。
下一期里我将谈谈结合Controlnet进行主体控制,背景和细节的生成方法,喜欢的朋友请持续关注。
PS:Stable Diffusion 虽然非常好用,但是其原理相当复杂,背后的支撑知识相当深厚,对于非计算机和人工智能背景的用户来说有不少知识都是很难的,因此本文主要还是探讨作者个人在使用过程中的一些经验,描述中有错误也是难免,请大家不吝指正。
