
从纳秒级优化谈CPU眼里的好代码
编者按:本文摘录自「全球C++及系统软件技术大会」张银奎老师的专题演讲。
1.现代CPU的偏好
今天,CPU眼里的好代码和我们平常理解的好代码是有区别的。可以思考一下,以下两条语句CPU的执行速度是一样的吗?
A=B*0.01 和 A=B/100.0
答案是不一样的。那我们来看看究竟有多大差别。

再来看看输出结果。

现在CPU内部的结构涉及到乱序执行、多流水线、多端口等逻辑。那如果拿Intel的Ice Lake客户端的微架构来看,可以分为前端和后端。前端可以看作高速的解码指令设施,把宏指令—英特尔X86指令解成V指令,放在V指令的队列里,下面是可以乱序执行的后端。下方显示的后端是多端口,每个端口都可以发射指令。前端可以理解为酒店前台,但是有没有空房,能否安排入住还是得看后端。

现如今,内存的压力是很关键的约束,计算机计算的数据需要从内存取得,导致内存供应不上。苹果推出的M1最大的革新就是增大了CPU和内存之间的带宽,释放了Memory Bound,因此取得很好的效果。
除法是现在CPU很难执行的操作,大家学过复制电路的话应该可以理解,除法操作需要很复杂的计算,因此它的流水线特别长,导致执行流水线压力特别大。
如果有十个端口,将它比喻成跑道,跑道的能力是不同的,当遇到加法指令,很多个端口都可以执行,但是对于除法指令,只有一个端口可以执行。普通的加减乘数学运算或是位运算,可以在多个端口执行,但是对于除法和个别的复杂指令,只有一个端口可以执行,并且开销很大,不同的CPU也会有细微的差别。
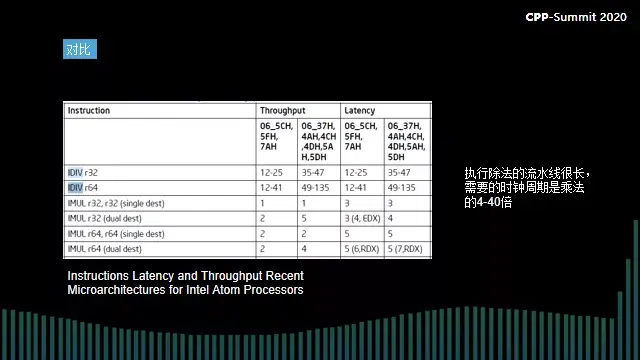
上图中我们可以看到latency是49-135个ticks,即跑一条除法指令需要49-135个时钟,然而普通的加法指令只需要一个时钟,并且理论上最多可以跑四条跑道,因此除法指令和加法指令需要的时钟周期差距悬殊。
我们可以通过以上的例子发现,CPU执行不同的指令所花的时间是十分悬殊的。如果把这个代码稍微改一改,将乘除累加到不同的变量上,它的性能会稍微好一点,但是仍然除法会比较慢。
2.数据结构定义
再来看看下面这个问题:写右侧school_s结构体的i和n成员的速度一样么?

上图中写了编译器不要自动做对齐,即按字节确定边界。比如,double是八个字节,int是四个字节,char是一个字节,int n如果没有pack(1)的话,编译器会给它至少分四个字节,int n在四字节的边界。总的来说,编译器的默认思想是,字段是多长,偏移地址就一定是可以整除的。比如是四个直接的整数,那这段的偏移一定是4、8、16、24这样的偏移值。但是如果加了pack(1),它会给它做紧缩,只分一个字节,int n就不对齐了。
给大家看一下内储类的布局,如果上这个调制器,观察一下n的位置。起始位置是对齐的,都是0,一行是16个字节,n就不对齐了,n的起始位置大概是13、14、15、16,有一个字节被移到下面了。这就叫不对齐的整数,对不对齐的整数要慎重。

访问对齐的和访问不对齐的速度一样吗?答案是不一样的,并且访问不对齐的要慎重。那访问不对齐的影响有多大呢?接下来还是用数据来看。这个问题对现代CPU来说变得更加“诡异”,对于读写还不一样,那到底是写不对齐的还是读不对齐的?这个影响还不同。
下面用一段代码来测一测。

现在的CPU,如X86,0、1、2这三条地址线是没有的,一写就是64位的数据总线,以八个字节为边界来写,因此不对齐的可能要写两次,因为写的时候都是以地址总线对齐的边界来写。如果你不对齐写两次,那多余的这部分要用屏蔽机制把它掩盖掉,所以硬件处理起来很费劲,开销大。

当我们用VTune观察这样内存赋值,这时候Core Bound和Memory Bound都很大,即执行引擎和内存都很有压力。因为执行引擎执行这样的不对齐指令需要做特殊处理—不对齐的位操作。在CPU层面,在写这样的内存的时候也是需要多花精力。在我们用VTune优化时,红色代表某个环节发生拥堵,绿色代表畅通。
因此,读写没有按边界对齐的整数会让我做很多无用功,写比读更悬殊。当我们做循环的读时,CPU内部会用所谓的向量化指令把把损失做一些弥补。
3.大数组的定义
接下来我们来看第三个案例,这是一个全局的、静态的大数组。

每个常量都在常量的字符串区,直接一个指针把常量指向它的字符串就好了,没有必要去数组里定义再拷贝过来,除非需要经常修改名字。如果名字是不变的,是恒定的一个常量,那就可以直接用第二种写法,第一种写法明显是浪费内存,还有一个副作用是从性能角度来说,如果定义成一组大数组,第一种写法会导致内存里的数据特别松散,访问不紧凑的数据会浪费缓存。
现在我们用工具来测一测,用这两种写法来测量一下性能差别。FOO代表不好的写法,循环遍历,根据id来搜索其中的一个元素;GOO代表好的写法。

测量有几种模式,一种是用batch成批测量。我们做调优的时候先循环跑几次,根据开始和结束的时间取平均值会比较准。最后我们得到紧凑结构体的速度要比松散结构体快36%。

另一种是用Interlace模式测量,分批测量再分别统计数据。最后也可以看到34%左右的性能差距。但Interlace模式测量的开销相对来说比较大。

从内存角度来说,如果用VTune专业工具来观察,可以看到每一行语句的开销,也可以从中得出相同的结论,访问紧凑结构的效果更好。而访问松散结构则容易产生很多TLB miss。


什么是TLB miss?现代CPU的复杂机制,其一就是复杂内存。访问内存都是为了查页表,由于软件里用的是虚拟内存,真正做后端访问的时候都要转成物理内存,转的过程中要查页表。页表很复杂,为了提高页表速度,CPU内部都有专门开页表的TLB,有代码的TLB,也有数据的TLB。访问松散的大数组产生很多TLB miss,因为它分散在很多个页上,在访问这些陌生页的时候它就不在TLB里。

从另一个指标来看,访问松散结构时L1 cache miss会比较多。CPU内部有很多级缓存,如L1/L2/L3......总的来说,今天CPU与内存之间的矛盾非常突出。当我们在做高频交易的时候,CPU调频速度非常快,但内存速度上不去,而且每次访问内存时采样要十几个tick的latency,内存的压力很大。所以松散结构体不仅浪费内存,而且访问的效率很低。

4.访问内存
再来看一个例子,访问内存的时候,比如这样一个二维矩阵,到底应该按行做循环,还是可以跳着来访问?

总结来说,隔行访问会导致比较多的cache miss,也会降低效率,让CPU来不及做cache,有很大的Memory Bound miss。可能是L1不行,可能是L2不行,也可能是最末一级LLC不行。最末一级不行就要访问物理内存,访问物理内存可能达到微秒级别,由于内存之间是有排队的,一访问内存,时间就不可控了。

如今我们进入多核时代,而多核化加剧了CPU核心与内存之间的压力,让CPU和内存之间的这条公路变得非常拥堵。而苹果M1核心技术最大的创新就在于释放了内存与CPU核之间的约束。

而我们要解决这个约束就是用cache,中间加缓存,一级一级加。冯·诺依曼架构的精髓是把内存提高到空前的地位,把内存重要化。内存重要化之后,无论是代码和数据都要寄存内存,CPU才能访问。有了这个机制后,CPU和内存之间就有了非常紧密的约束。这就是今天冯·诺依曼架构的最大矛盾。

对于优化cache,要做循环交换来做编译执行,记录时间,提升数量级,合并循环减少cache miss,让CPU有更高的cache命中率。用不好cache就是白白浪费了CPU的宝贵资源。


要想写开启友好的代码,第一原则就是遵守局部性原则。局部性原则就是让结构体紧凑,让访问时间性和空间性都离得很近。第二是温度原则,我们经常访问,它的温度就高。
纳秒级调优的第一大挑战就是常常看不出效果,或者看到相反的效果。那我们如何自己做调优实验呢?

纳秒级调优三大守则
第一守则:防止编译器好心帮倒忙
去除干扰,防止编器误解,增加输出,防止编译器好心做坏事。

第二守则:禁止CPU调频
把CPU的Speed Step选项禁掉,锁定频率,因为CPU的调频幅度非常大,不锁定频率测出来的都是干扰,数据跳动幅度特别大。

使用Vtune这样的专业工具可以直接打开CPU层面的计数器,可以测出更准确的数据。

关于我们
2022年3月11-12日,「全球C++及系统软件技术大会」将于上海隆重召开,“C++之父”Bjarne Stroustrup将发布主题演讲。来自海内外近40位专家将围绕包括:现代C++、系统级软件、架构与设计演化、高性能与低时延、质量与效能、工程与工具链、嵌入式开发、分布式与网络应用 共8大主题,深度探讨最佳工程实践和前沿方法。大会官网:www.cpp-summit.org

