
2023.03.20, 03.21, 03.22 ArXiv精选
关注领域:
AIGC
3D computer vision learning
Fine-grained learning
GNN
其他
声明
论文较多,时间有限,本专栏无法做文章的讲解,只挑选出符合PaperABC研究兴趣和当前热点问题相关的论文,如果你的research topic和上述内容有关,那本专栏可作为你的论文更新源或Paper reading list.

Paper list:
今日ArXiv共更新142篇
03.21 ArXiv共更新221篇
03.20 ArXiv共更新99篇
AIGC
Diffusion-based Document Layout Generation
https://arxiv.org/pdf/2303.10787.pdf

利用扩散模型做文档布局生成.
LayoutDiffusion: Improving Graphic Layout Generation by Discrete Diffusion Probabilistic Models
https://arxiv.org/pdf/2303.11589.pdf

Text2Tex: Text-driven Texture Synthesis via Diffusion Models
https://arxiv.org/pdf/2303.11396.pdf

使用Diffusion model 完成文本引导的3D物体的纹理合成.真的是什么样的科研角度都有啊.
SKED: Sketch-guided Text-based 3D Editing
https://arxiv.org/pdf/2303.10735.pdf

西蒙弗雷泽大学和英伟达的工作.
将草图和扩散模型与NeRF相结合,实现基于草图和文本的3D shape的可控区域编辑.
这个方向太卷了实在是!
3DQD: Generalized Deep 3D Shape Prior via Part-Discretized Diffusion Process
https://arxiv.org/pdf/2303.10406.pdf
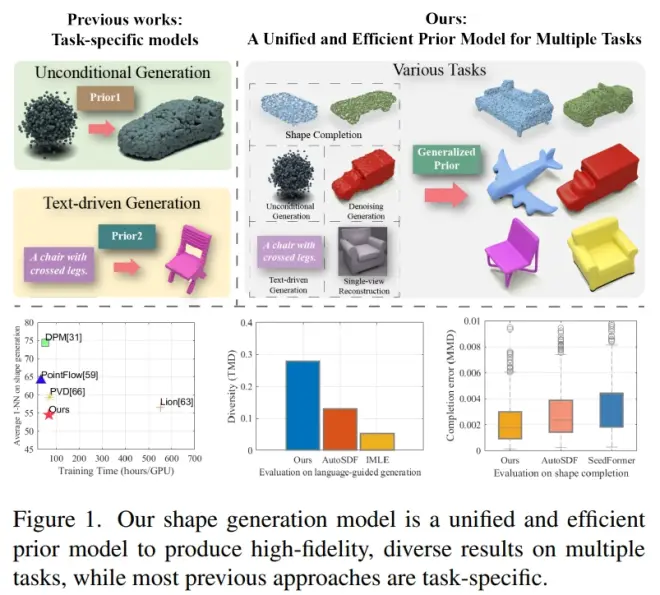
本文提出了一个统一的3D先验生成模型,主要利用了VQ-VAE和diffusion model.且能够支持很多任务,比如点云补全,无条件的shape生成以及跨模态的shape生成.
Vox-E: Text-guided Voxel Editing of 3D Objects
https://arxiv.org/pdf/2303.12048.pdf

真的好卷,谷歌的一篇工作.利用LDM实现文本到3D物体的编辑,面向体素.
Zero-1-to-3: Zero-shot One Image to 3D Object
https://arxiv.org/pdf/2303.11328.pdf

Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
https://arxiv.org/pdf/2303.11989.pdf
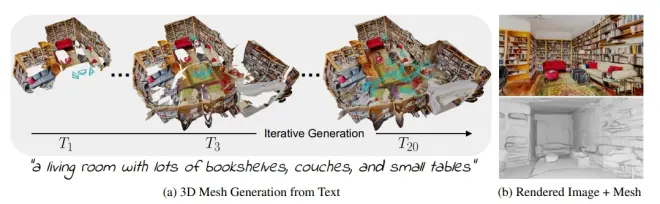
扩散模型相关
Object-Centric Slot Diffusion
https://arxiv.org/pdf/2303.10834.pdf

本文探讨了如何使用扩散模型来促进object-centric的复杂场景理解,提出了基于扩散模型的object-centric slot attention.
VLP
EVA-02: A Visual Representation for Neon Genesis
https://arxiv.org/pdf/2303.11331.pdf

曹越大神的EVA系列.只能说太强了.
VLP for 3D
Grounding 3D Object Affordance from 2D Interactions in Images
https://arxiv.org/pdf/2303.10437.pdf

这是一篇从2D图像中的学习交互信息,进而来促进3D object affordance grounding的学习.
3D Concept Learning and Reasoning from Multi-View Images
https://arxiv.org/pdf/2303.11327.pdf

3D multi-view visual question answering新的benchmark. 是个新坑.
CLIP goes 3D: Leveraging Prompt Tuning for Language Grounded 3D Recognition
https://arxiv.org/pdf/2303.11313.pdf

CLIP拓展到3D领域.
医学图像
HybridMIM: A Hybrid Masked Image Modeling Framework for 3D Medical Image Segmentation
https://arxiv.org/pdf/2303.10333.pdf

MIM的思想,应用到了3D医学图像上.
