
R语言自然语言处理NLP:情感分析上市公司文本信息知识发现可视化
全文链接:http://tecdat.cn/?p=31702
原文出处:拓端数据部落公众号
情感分析,就是根据一段文本,分析其表达情感的技术。比较简单的情感分析,能够辨别文本内容是积极的还是消极的(褒义/贬义);比较复杂的情感分析,能够知道这些文字是否流露出恐惧、生气、狂喜等细致入微的情感。此外,情感的二元特性还可以表达为是否含有较大的感情波动。也就是说,狂喜和暴怒都属于感情波动,而宠辱不惊则属于稳定的情感状态。
研究目的
本文基于R语言的自然语言处理技术,针对企业的财务信息、产品质量等文本信息,帮助客户对企业和产品进行情感分析和情感分类,并将这些数据可视化呈现。本文选择了A股上市公司相关数据,通过构建R语言的文本情感分析模型对文本情感进行分析,并以此为基础对企业进行情感分类。 附件说明:其中基础词典是要通过文本挖掘的结果扩展的词典了,也是研究的主要目的(分词的时候可以用到);







语料库资源是要进行文本挖掘的数据源。



研究的目的就是在文本分析结果的基础上扩展用户词典,这些需要在文本挖掘的基础上进行扩展。其中语料库一共是10个文件,需要的是一个文件出一个结果。最后是要对比这10个文件的。还有就是语料库是pdf格式。
出现的结果应该是类似这种的:
中文财务关键词05年06年07年08年负面词184107 正面词4866 不确定词2219 诉权词5731
读取词库数据
Litigious=read.table("Litigious Words.txt") Strong=read.table("Modal Words Strong.txt") Weak=read.table("Modal Words Weak .txt") Positive=read.table("Positive Words.txt") Uncertainty=read.table("Uncertainty Words.txt") Negative=read.table("Negative Words .txt")
文本清理和分词
qrxdata=gsub("\n","",qrxdata) words= lapply(X=qrxdata, FUN=segmentCN) ;
初始化统计结果
x=words pwords=positive nwords=negative Litigious=Litigious Strong=Strong Weak=Weak Uncertainty=Uncertainty
npwords=0 nnwords=0 nLitigious=0 nStrong=0 nWeak=0 nUncertainty=0emotionType <-numeric(0)
xLen <-length(x)
emotionType[1:xLen]<- 0
index <- 1
词法分析
词法分析。它的原理非常简单,事前需要定义一个情感词典。比如“喜欢”这个词我们定义为1分。那么“我喜欢你”这句话,“我”和“你”都是中性词,均为0分,“喜欢”为1分,这句话的总分就是1分。“我喜欢你,但讨厌他”,这样一句话中有“讨厌”这个词,在情感词典中分数为“-1”,那么整句话的得分就是0。这样,我们就可以对每一个文本进行分词,然后使用内连接(inner join)来提取其中的情感词语,并根据情感词语的得分,来评估这段文本的情感得分。
for(index in 1: xLen){
x[[index]]=unique(x[[index]])
yLen <-length(x[[index]])
index2 <- 1 for(index2 in 1 :yLen){
if(length(pwords[pwords==x[[index]][index2]]) >= 1){
i=pwords[pwords==x[[index]][index2]]
npwords=npwords+length(pwords[pwords==x[[index]][index2]])
if(length(i)==0)next;
duanluo=substr(qrxdata[index],regexpr(i,qrxdata[index])[1]-20,regexpr(i,qrxdata[index])[1]+20)
if(regexpr(i,duanluo)[1]<0 )next;
cat(studentID,"\t",i," \t","DOC",index,"\t ","pos"," \t",duanluo," \t",length(pwords[pwords==x[[index]][index2]])/length(x[[index]])," \
按年份和词性分类汇总成表格
1=data.frame("正面词"=npwords,"负面词"=nnwords,"不确定词"=nUncertainty,"诉权词"=nLitigious,
"强语气词"=nStrong,"弱语气词"=nWeak)
=rbind(,1)
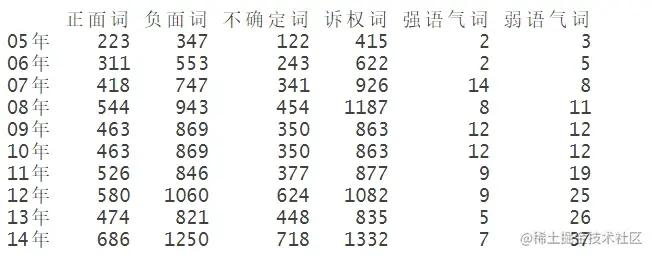
ggplot可视化
将每个文档的词性输出,并按照词性和年份绘制变化趋势:


最受欢迎的见解
1.Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组
2.R语言文本挖掘、情感分析和可视化哈利波特小说文本数据
3.r语言文本挖掘tf-idf主题建模,情感分析n-gram建模研究
4.游记数据感知旅游目的地形象
5.疫情下的新闻数据观察
6.python主题lda建模和t-sne可视化
7.r语言中对文本数据进行主题模型topic-modeling分析
8.主题模型:数据聆听人民网留言板的那些“网事”
9.python爬虫进行web抓取lda主题语义数据分析
