
CNN识别手写吉尔吉斯语字母以及相关

0. 前言
本专栏主要介绍了一下我做的一个小的深度学习项目,并分享一下我的感受。主要面向有一定深度学习经验的人,如果有任何不懂的或者我有什么错误的地方欢迎评论区留言。
这里分成两部分来介绍,首先是项目具体内容,然后是我对这个项目的一些相关讨论。
1. 项目内容
1.1 项目介绍
使用CNN(卷积神经网络)实现识别手写吉尔吉斯字母的分类器,即输入一个手写的吉尔吉斯字母的PNG图片,输出对应的字母。
数据集:https://www.kaggle.com/datasets/ilgizzhumaev/database-of-36-handwritten-kyrgyz-letters
具体大概是这个样子(共36种吉尔吉斯字母):


1.2 注意事项
数据集文件夹直接使用了吉尔吉斯字母作为文件夹名称,在中文的windows系统下,这些名称会被识别为中文字符,程序中需要注意进行转换。
数据集为134x134的PNG图片,直接全部读取会占用大量内存,直接作为神经网络的输入也过大,这里需要对其作预处理。
数据集内部有做训练集(train)和测试集(test)的划分,严格来说测试集用作超参数的确定,会部分参与训练,因此严格来说应该要保留一个验证集(validation),其没有参与任何训练。这里直接将数据集中的测试集作为验证集,而不再去专门划分测试集,但是后续描述依旧称其为测试集(test)。
神经网络的实现这里使用tensorflow的keras包(https://keras.io/getting_started),因此程序使用python实现(即便我很讨厌python)。
1.3 数据预处理
这里统一将输入的数据转换成32x32的灰度图像作为输入,具体操作为(借助opencv包实现):
使用opencv读取图片
如果图像有透明度通道,首先将其置于纯白的背景下得到没有透明度的BGR图像
使用opencv的内置函数将BGR图像转为单通道的灰度图像
将整个灰度图像做仿射变化,使得最亮颜色为255,而最暗颜色为0(最大化对比度)
裁剪周围多余的白色背景(容差为32)
将裁剪后的图像使用白色向周围延申成正方形图像
缩放图像到28x28
将周围填充2宽度的白色像素,得到32x32的灰度图像
预处理前后对比:

在这里最后再将得到的图像数组除以255归一化并使用浮点数存储,并且使用1减去结果(反色),使得重要的字符部分接近1而不重要的背景接近0。
1.4 CNN的结构
最后确认下来的结构如下图:

对应代码(model.py):
其实模型本身没什么特别的,这里提几个比较重要的点:
所有卷积核采用3x3的大小。
其中DepthwiseConv2D的使用主要是控制整个模型的参数数量。
除了最后分类使用softmax,其余部分统一使用relu作为激活函数。
图片展示的为默认最简单的结构,实际可以通过dropout和BN参数来增加这两个层,以及append_layers来增加额外的中间层。
参数数量:

1.5 CNN的训练
使用交叉熵作为损失函数,使用keras默认自带的SGD优化器,设置batch_size=32,epoch=32(or 24),初始学习率设置为0.1,策略为前4个epoch固定为0.1,后续按照0.4/epoch递减,如下图:

关于这些选取的解释为:
损失函数:由于是分类问题,选用交叉熵(回归问题则选择均方差,这是极大似然估计的结论)。
优化器,batch_size,epoch:认为这只是一个最优化问题,因此只需要保证在可以接受的时间内达到(或基本接近)最小值即可,因此(不去考虑早停的情况下)如何选择没有本质区别。
学习率:同样认为只是一个最优化问题,因此学习率只要保证迭代收敛即可。
1.6 训练结果
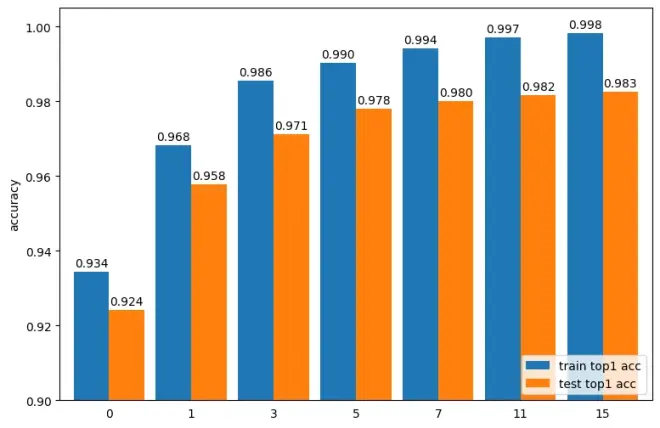
对于上述最简单的模型(不增加dropout或BN),有结果:



其中top-1准确率表示模型预测的概率最高的分类就是正确分类的比例,而top-5准确率表示模型预测的概率最高5个分类中包含正确分类的比例
很明显,训练过程出现了过拟合的现象,随着训练轮次增加,虽然训练集上loss持续减少,但是测试集上的loss先下降后上升。
许多地方会采用早停的技术来抑制这种过拟合现象,即对于上述情况,会在epoch=11处停止进一步训练,将其直接作为最终模型,此时测试集上的loss最小。
这里我并不推荐这种做法,首先这样我们的测试集就一定程度参与了训练过程,用来确定“训练轮次”这个超参数(上面说过,这里还是将测试集作为验证集来使用,不希望其参与训练过程)。
另一点则是,应该认为训练过程是一个最优化的过程,“早停”实际上并没有让这个模型中的参数达到最优,这样会有更多的东西影响训练结果:例如优化器的选择,batch_size,等等。
关于过拟合,不是只有这种测试集上的loss先下降后上升才可称为过拟合,其实只要测试集上的loss明显高于训练集就是过拟合,因此过拟合其实是一个相对概念。
1.7 抑制过拟合
这里通过向模型中增加dropout或BN层的方式来抑制过拟合,并且对比两者的效果:
关于dropout和BN具体内容请读者自行查阅相关资料



数据都叠在一起了,将纵坐标换成对数坐标可以看得更加清晰一些:


可以看到无论是使用dropout还是BN层,都可以很好的抑制过拟合,并且BN可以增加训练的速度,而dropout则有相对更好的效果。而同时使用两种则可以兼顾训练速度的提升和更好的效果(虽然一般认为只需要选择一种即可)。
可以看到虽然测试集下,dropout的loss比BN更小,但是top-1准确率是相反的,尽管如此这里还是以loss为准。
在使用dropout后,训练集的loss反而大于测试集的loss,并且错误率也有类似的结果,这是由于keras的dropout层只有在训练的时候会开启(只使用部分参数),而在测试的时候会关闭(使用了所有参数),因此一般测试时得到的结果会更好。
可以发现无论使用dropout还是BN层,最终测试集上的效果都要好于不添加的模型,即使使用上“早停”技术,因此我更加推荐使用dropout或者BN层来抑制过拟合而不是"早停"。
2. 相关讨论
2.1 参数对网络性能的影响
这里统一使用效果最好的同时添加dropout和BN层的模型,训练epoch=32保证基本收敛,并调整每一层的卷积核数目或者增加中间层的数目,以此来扩大网络的规模,看看能否进一步提高分类的性能。
首先调整每层的卷积核数目,得到top-1和top-5准确率的趋势:


最开始的网络选择的卷积核数目为32。
然后是设定卷积核数目为16,增加神经网络的层数,得到top-1和top-5准确率的趋势:

可以看到两种方式都可以增加网络性能,并且都存在边际效应。
这里统计每个的具体参数数目,得到性能随参数增加的变化趋势:


可以看到,增加网络的层数相比增加每层的宽度,可以使用更少的参数达到相同的性能,也就是增加网络的层数比增加每层的宽度“性价比”更高。
当然也不能无限的增加网络的参数,当层数过多时,会出现梯度消失或者梯度爆炸的问题,导致训练困难;而著名的ResNet就是克服了这个问题,从而可以将网络层数增加到非常高(152层)也可以保证训练能收敛,得到了非常好的效果。

由于这个项目问题比较简单,这里不考虑使用ResNet。
2.2 GUI交互实现
这时会想是否可以直接创建一个绘图区域,实时将绘制的图像使用上述训练的模型来进行分类,可以马上查看模型的效果。
比较可惜的是似乎没有比较好用的现成的库实现这个功能,这样我就只能从tkinter来做一个简单的gui程序(最讨厌写gui)。
实现过程这里略去,最后得到的界面如下:

选择的是每层32个卷积核,不添加额外层的模型,并只使用了BN层而没有使用dropout。
使用鼠标左键绘制,右键擦除,左上角按钮清空所有图像:


试了一下才知道,我也不知道手写吉尔吉斯字母到底是个什么写法,所以分类到底准不准我也不知道,也就图一乐
3. 源码提供和说明
源码已经上传到github,感兴趣的可以直接使用:https://github.com/CHanzyLazer/ML-CNN-Kyrgyz
里面包含模型构建,图片预处理,训练和绘图,以及gui的实现代码;并且保留了我运行的结果。
仓库中只包含源码不包含数据集,数据集需要另外下载:https://www.kaggle.com/datasets/ilgizzhumaev/database-of-36-handwritten-kyrgyz-letters
下载完成后数据集置于dataset目录下,文件结构为:
