
【脑机接口论文分享】基于大脑信号重建图像-2

接下来讨论实验结果。对解码器部分实验,右图展示了同一名受试视觉重建的效果,结果表明,仅使用z的重建图像在视觉上(如材质和轮廓)与原始图像一致,仅使用c的重建图像生成语义一致但视觉不一致的图像,而使用zc重建的图像在语义和视觉上均一致。

对于不同受试者的重建图像而言,其质量在不同受试间存在明显差异,这与受试本身的数据质量有关。对生成图像质量的评估表示,使用z生成的图像在模型前几层效果更好,使用c生成的图像在模型后几层效果更好,而使用混合了视觉信息和语义信息的zc生成的图像对不同的评价指标其值都普遍较高。

对于编码器部分实验。实验一潜在表示之间的比较结果显示,Z在视觉皮层后部分,即早期的视觉皮层产生了较高预测性能。而c在大范围皮层中显示了很高的预测性能。Zc和z有非常相似的表示。此图使用的评估指标为皮尔森相关系数。实验二不同噪声级别之间的比较结果表明,当添加少量噪声是,z比zc更好的预测整个皮层的体素活动,而增加噪声水平后,zc比z能更好的预测较高视觉皮层内的体素活动。
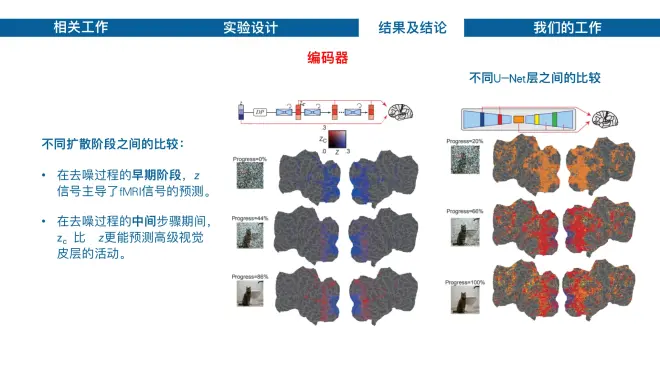
实验三不同扩散阶段之间的比较结果表明,在去噪过程的早期阶段,z信号主导了fMRI信号的预测,而在去噪过程的后期zc比z更能预测高级视觉皮层的活动。

实验四不同U-Net层之间的比较结果表明,在去噪的早期阶段,U-Net的瓶颈层在整个皮层中产生最高的预测性能;随着去噪的进展,U-Net的早期层对早期视觉皮层内活动的预测起到了主导作用。

接下来是本文的研究结论。
本文提出了一种新的基于LDM的视觉重现方法,该方法不需要训练或微调复杂的深度学习模型,只需要从fMRI到LDM中的潜在表示的简单线性映射。
通过解码器部分实验,对LDM如何结合文本语义信息生成图像提出解释。
在编码器部分实验,作者构建了编码模型对LDM的内部组件进行了定量解释,从神经科学角度,解释了LDM组件相对应的大脑区域。

接下来是我对本实验的一些后续思考:如何基于上述实验框架,训练能有感情的作画的机器。
该想法的理论基础来自于通用人工智能研究院院长朱松纯所提出的迈向通用人工智能的计算范式——人机价值对齐。
举一个生活中的例子,说明价值对齐的意义:
如果人与人之间能够长时间相处并保持情绪稳定,说明他们有相同的价值体系。但是如果两个人相处过程中无法保持情绪稳定,就说明他们的价值体系出现了差异。人机协作也是这样,如果协作过程中人类出现了较大的情绪波动,说明人类和机器的情绪价值没有对齐。在这种情况下如果还想继续合作的话,有一方必须做出让步。在这里,我们选在对AI进行调整。
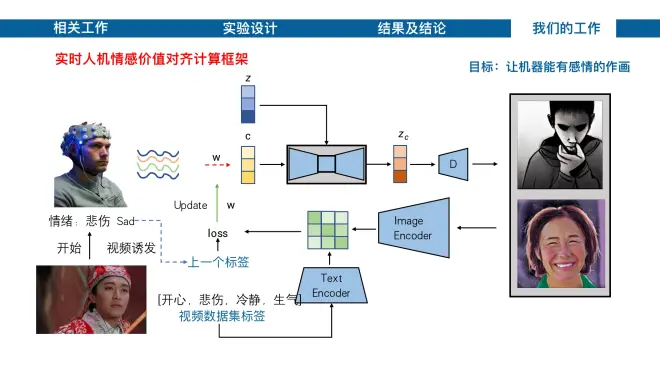

在这样的理论指导下,设计了如下的用于人机情感价值对齐的计算框架:最开始通过有情绪标签的视频诱发受试情绪,采集其脑电信号向 LDM 模型的文本特征 c 做映射。将其生成的图像通过CLIP图像编码器,与视频标签经过的文本编码器做相似度比对,判断出的结果与上一时刻的情感标签计算随损失,如果与上一时刻标签不同,则说明机器的绘画结果导致了人类的情绪波动。这样的话就需要对AI进行调整,即通过损失对模型权重W进行更新,从而实现实时人机情感价值对齐。
对应平台的演示视频请见本账号【脑机接口实验】基于 Stable Diffusion 的情绪绘图
