
【高级篇】RSS的世界:Huginn篇(中)

差点就放弃写Huginn篇了,一是我平时折腾的那些网站全是静态网页,feed43就可以搞定了,Huginn简直宰牛刀。二是Huginn使用起来需要一定门槛,比如要有服务器,没服务器那就用云开发平台吧,还得备着“梯”*zi,部署的时候得需要一些计算机知识吧,我就看个老头官网消息,感觉更没必要折腾Huginn了😂
先更新中篇的内容,就是关于Huginn如何使用。前篇关于Huginn的部署,我打算讲在Heroku里部署以及获取Huginn管理员权限。后篇是针对用Heroku部署Huginn产生的休眠问题如何解决,用服务器部署Huginn完全不用看后篇哈~
先说明一下哈,以下内容是针对静态网页的抓取步骤指南,如果需要抓取动态网页(大型网站有一些用的是动态,普通网站还是静态为主),其实就在以下步骤之前多一步,用Phantom Js Cloud Agent渲染动态网页成静态页面后接下文的步骤。

第一步,先抓取概要信息。

先看一下用来做例子的网站,Chage的官网(我咋这么喜欢用C来开刀呢~😂~)
先登录Huginn,然后在左上角处点击创建新代理(New Agent)


然后选择代理类型(type),输入web就能出现Website Agent,选择它。
这时出现具体设置的页面,大概分成三个区域,左上为填写代理基本信息与各个代理之间承接关系等等,左下为具体的代码,右边一大块都是帮助说明。(帮助说明十分重要!一定要多看)

下面先看基本信息区。
代理类型(Type)不用动
名称(Name)自己随便起一个就行,比如“第一步”,或者网站名,或者“摘要”,自己能看明白的名字就好。
日程(Schedule)根据实际需要设置,比如你抓取的内容更新比较频繁,就把时间间隔设置的小一些,Every 5m、Every 10m之类的。
控制(Controllers)不用填写
事件保留时间(Keep events),实际使用要设置成forever,要不工作几天就不工作了。
来源端(Sources),就是说你需要不需要其他代理的数据,一般创建第一个代理这项不用填。立即执行(Propagate immediately) 打勾。
接收端(Receivers),就是说你这里抓取的信息要传递给下一步的代理,一般创建第一个代理这项不用填。
场景分类(Scenarios),就是把这一系列的代理打个组这个分类,比较方便查看,可填可不填。


代码区主要用到的有最右上角的切换视图(Toggle View),试运行(Dry Run),这里提供两种视图,一种是下面的这种带绿条的(图一),一种是纯代码的那种(图二)。


关于切换视图(Toggle View)有个小技巧,就是用图二的视图写好代码,然后点击Toggle View,如果能正常切换回带绿条的视图,说明代码写的没问题,如果切换失败,提示出错什么的,就说明代码写的有问题,需要再检查一遍代码,尤其是符号。
这个切换视图小技巧特别适合像我这种没写过代码的人,因为我对符号没意识,不是丢个,就是丢个;“”,代码总是报错……😂
下面开始写代码。

第一行expected_update_period_in_days,我理解的应该是给代理设置一个更新周期,在这个周期里网页没有新消息更新,Huginn会认定为网站没有工作(work),这项很鸡肋,不用管。
先填写url,就是你要抓取的网页网址。
类型(type),基本都是html
模式(mode),这里有三种,all、on_change、merge。(具体见下图)

一般来说第一步抓取用的是on_change模式,到中间这一层需要上一步的数据传递过来所以要用混合模式(merge)。
下面该填写具体的抓取代码了,先看一下老头的网站,按F12调出查看器。

这里可以看出要抓取的内容都在inf_box这一层里面,里面包括网址信息,标题内容,时间信息等等。(如何用F12找到具体位置,我是凭感觉来的,反正是在中间位置,火狐浏览器右击有个检查,可以直接定位到大概位置。)
下面先写提取(extract)里的url信息,从上图可以看到,网址在class="inf_box"的下面。
<div class="inf_box">
<a href="/information/media/detail-462.php">
根据huginn的帮助指南里面的举例:"url": { "xpath": "//*[@class="blog-item"]/a/@href", "value": "."(我习惯用xpath来写,用css来写也是一样的),稍稍改一下就是下面这段代码:
"url": {
"xpath": "//*[@class=\"inf_box\"]/a/@href",
"value": "."
}
这里面的//*[@class=\"inf_box\"]/a/@href,咋解释呢……,//* 就是网页前面的代码全部省略,只找class是inf_box的那部分,然后 /a/@href 对应的 <a href="/information/media/detail-462.php">这一行,value用的 . 就是 <a href=的所有值。
注:代码是灵活的,不唯一!
"url": {
"xpath": "//*[@class=\"inf_box\"]/a",
"value": "@href"
}
这样写也一样可以抓出来网址,解释出来就是找class是inf_box的那部分,对应到后面的<a,value的值取得是href的值。


点击右上角的Toggle View来回切换几遍,先保证代码没问题,然后点击Dry Run试运行。

点击Dry Run。

能看到正确的输出结果,url那一行写的没问题,再添加标题(title)

从上图可以看到,标题信息(title)在class="inf_txt"的旁边。
<p class="inf_txt">12月度、ラジオコメント出演情報!</p>
根据上面所讲的步骤,写出title的代码:
"title": {
"xpath": "//*[@class=\"inf_txt\"]",
"value": "string(.)"
}
代码写法不唯一,也可以写成下面这种:
"title": {
"xpath": "//*[@class=\"inf_txt\"]",
"value": "./node()"
}
解释一下这两种value,一个是string(.),应该是指class是inf_txt里包含的所有字符串,再具体我也不能说清楚啦,我也没学过计算机…… 字符串是啥我也不懂……反正就大概这个意思啦。另一种是./node(),就是取括号外的值,<p class="inf_txt">12月度、ラジオコメント出演情報!</p> 这里面的“12月度、ラジオコメント出演情報!”正好在两个<>的外面,“./node()”正好可以用。
还可以用normalize-space(.),这个是去除文本中的空格和回车的值。

先点击右上角的Toggle View切换几遍视图看看代码有没有问题,再点击Dry Run试运行。
下面贴出四种不同value的输出结果。




嘛,value就那么几种写法,大不了挨个试一下看看哪个效果好 😂
再根据上面的步骤把日期信息也抓出来。

实际使用中,没必要把value值折腾这么多,我做例子才弄这么多value值,千万别被我带跑偏。😂
Dry Run一下。

这时候还有一个问题,url抓出来是没有域名的,这在RSS阅读器里不认的,接下来需要给一个模板(template)。模版和提取(extract)是同级,写在提取(extract)的下方。
"template": {
"url1": "{{ url | to_uri: _response_.url }}"
}
指定一个新的url1,url1是刚刚抓取的url的“延伸”,我感觉我解释不清了,可以理解为给刚刚抓的url一个“前缀”把网址补全。这里一定要注意别丢了符号 ,我总是忘记大括号还有逗号。



大功告成!url1已经显示出正确的网址!
如果仔细看的话,会发现这样抓出来的和 feed43 抓出来的东西是一样的。😂
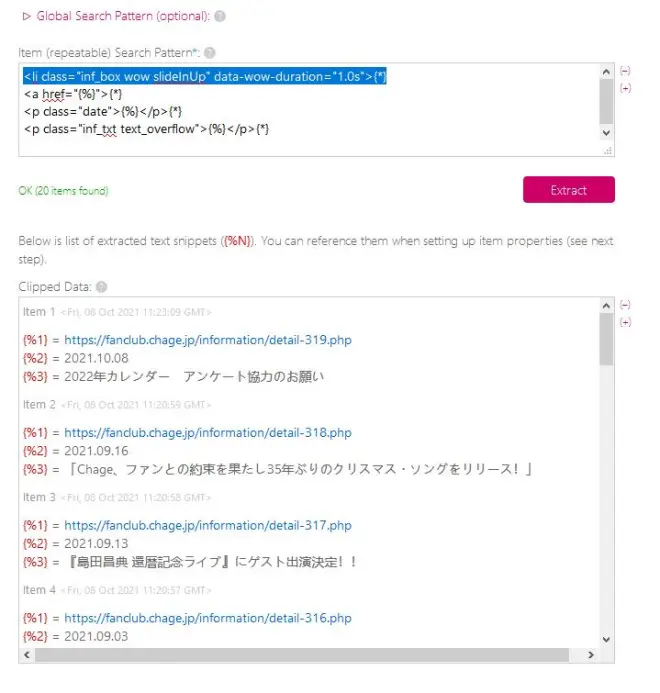
到了这里,可以进行第三步直接输出XML订阅地址,因为RSS阅读器都有获取全文功能,我们把url1这个网址告诉RSS阅读器,阅读器会自动加载出全文,如果阅读器获取的全文排版很乱,我们才会做第二步,就是用Huginn获取全文,再输出XML订阅添加到阅读器里。
第二步,根据刚刚获取到的url1网址,获取文章全文。
创建新的代理。

这里要填写来源(Sources)了,来源就是刚刚第一步创建的代理。其他的根据自身情况填写。
代码区要注意,url要写刚刚获得的url1地址 {{url1}},模式要选择merge。

先进入网站看一下F12,找到正文所对应的位置。

可以找到正文内容都在class="inf_detail_txt"的代码中。
<p class="inf_detail_txt">現在決まっているラジオコメント出演情報です。……</p>
所以在extract里添加article或者text,名称可以自己随便取,只要你能记住就行。
根据上面讲到的内容写好代码。

Dry Run一下。

这时出现这样的界面,随便点击一个上面的url。

这时再点击Dry Run。
下面列出四种不同value值的输出结果。




通过对比可以看出,"value": "./node()"是非常完美的。"value": "string(.)"不包括<br>的换行符,这样排版会乱。"value": "normalize-space(.)"只有文本信息,这样排版很密。"value": "."是最完整的信息。
用"value": "./node()"或者"value": "."都可以。
保存一下,这样第二步就完成了。
终于到第三步也就是最后一步,输出RSS订阅地址!码字码的我都累了……
再创建一个新的代理。选择Date Out Agent

可能有人要问了,下面不是有个RSS嘛,那个不是输出RSS订阅啊,是把别人的RSS作为来源输入进来……
基本信息和之前差不多,来源选择刚刚创建的代理。如果你跳过了第二步,那来源就是第一步的代理,如果你做了第二步用huginn来获取全文,此时的来源就是第二步的代理。

剩下的代码就简单多了。
secrets:是输出XML文件的文件名,可以改个自己好记的名称。
template部分见下图,都是自己自命名的。
item部分要仔细填写!
title是第一步代理里面的title。
description是第二步代理里的article,如果没做第二步,可以把这行删掉不写。
link是第二步代理里面的url。
pubDate是第一步代理里面的时间。
可能有人要问了,为啥这里又能指定第一步代理里的信息,又能指定第二步代理的信息,还记得第二步里模式mode选的是merge吗?选择了merge后,就把这两步代理的信息都合并了,所以这里可以各种指定。

保存
点击你刚刚创建的RSS输出代理,就看到输出的xml文件了。

把这个xml地址添加到你的RSS阅读器里就全部完成了!
再补充一点,如果把上面的都做完后发现events里是空的没抓到信息,不急,run一下第一步创建的代理。

Huginn就自动刷新了,然后就能看到新的events出现~
哎哟我的妈呀,可算是把huginn的RSS用法写完了,看不懂没关系,多动手写一写,试一试,报错就检查符号有没有忘记,好像没啥要再强调的东西了。
希望这篇小文能帮到有需要的人~😂~
【安利向】RSS的世界:cv13449742
【进阶篇】RSS的世界:RSSHub篇:cv13543035
【进阶篇】RSS的世界:Feed43篇:cv13544223
