
python机械学习






通过下棋,从棋谱中获取规律,对 对手的旗进行预测
通过历史购买信息预测将要购买物品



数据集构成:从历史数据中获得规律,
格式,文件:csv


目标值:预测房价
pandas 处理数据

pandas处理完类型

不需要去重(ppt错),反复学习同一组数据,也可以学到东西。(复习)




意义:直接影响预测结果
Scikit--learn





转化成数字的值




字典数据
from sklearn.feature_extraction import DicVectorizer

转化为数组
sparse=False

无数补0( ,)坐标 1.0值


类别换成特征,利用数据进行分析
排名不代表优先级,one-hot


流程
1.实例化类CountVectorizer
2.调用fit_transform方法输入数据并转换
(1.注意返回格式,利用toarray()进行sparse矩阵转化array数组)
例:['life is short,i like python','life is too long,i dislike python']

导入CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer



sparse矩阵转化成数组toarray()
CountVectorizer
1,统计所有文章当中所有的词,重复的只看做一次,
词的列表
2,对每篇文章,在词的列表里面进行统计每个词出现的次数(单个字母不统计,无情感趋向,无分类依据
文本特征抽取(count{1文本分类2情感分析
----隔开(分词),与合并结果不同
也不支持单个汉字





文本特征抽取最大用途为文本分类,
文本特征抽取方式tf idf


分类机械学习算法的重要依据
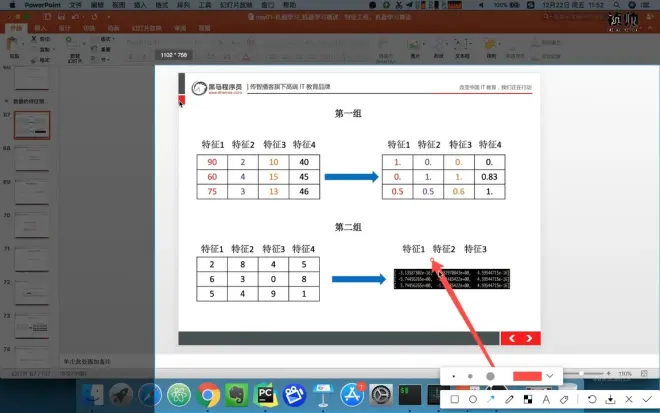
两种方式{1归一化2标准化


sklearn 特征处理API
sklearn.preprocessing(语法


特征值第一个数据运算过程


归一化步骤
1实例化MinMaxScalar
2通过fit_transform转换
[[90,2,10,40],
[60,4,15,45],
[75,3,13,46]]
from sklearn.preprocessing import MinMaxScalar


三个特征同等重要:进行归一化
使得某一个特征对最终结果不会造成更大的影响
如果数据中异常点较多带来的影响:
异常点对最大值最小值影响太大
归一性总结:
在特定场景下最大值最小值是变化的,最大值与最小值非常容易受异常点影响,所以这种方法的鲁棒性较差,只适合传统精确小数据场景
鲁棒性:什么是鲁棒性_鲁棒性和稳定性的区别_鲁棒性和泛化性的区别 - 与非网 (eefocus.com)
标准化特点:
通过对原始数据进行变换把数据变化到均值为0,标准差为一的范围内

异常点对平均值影响不大

sklearn 特征化API
sklearn特征化API:scikit-learn.preprocessing.StandardScaler

标准化步骤:
1,实例化StandardScaler
2,通过fit_transform转化
[[1.,-1.,3.],[2.,4.,2.],[4.,6.,-1.]]
导入:from sklearn.preprocessing import StandardScaler

样本足够多情况下比较稳定,适合现代嘈杂大数据场景
缺失值
1删除:如果每行或者列数据缺失值达到一定的比例,建议放弃整行或整列
2插补(建议):通过缺失值每行或者每列(建议)的平均值,中位数来填补
sklearn缺失值API:sklearn.preprocessing.Imputer

pandas处理空缺值
dropna(直接删除)fillna(直接填补
数据当中的缺失值:np.nan
replace('?',np.nan)


0列
降维:维度:特征数量

数据降维(特征数据减少
1特征选择2主成分分析
特征选择为什么
亢余:部分特征相关度高;容易消耗计算性能
噪声:部分特征对预测结果有影响

特征1,2多余
方差大小:考虑所有样本这个特征的数据情况

过滤式
sklearn.feature_selection.VarianceThreshold



自动把一二四列删除,方差为1的列
主成分分析

通过照片(一维)能够判断是什么物体(二维

特征之间的相关性


二维投射到一维


instacart:把用户分成几个类别
import pandas as pd
fromsklearn.decompation import PCA
pd.read_csv(目录)pd.merge

交叉表pd.crosstab(mt['user_id],mt['aisle'])
cross.head(10)
#进行主成分分析
pca=PCA(n_components=0.9)这个可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目
data=pca.fit_transform(cross)
data.shape
算法是核心,数据和计算是基础

算法判别依据



监督学习
可以输入数据中学到或建立一个模型,并一次模型推测新的结果。输入数据是由输入特征值和目标值所组成。函数的输出可以是一个连续的值(称回归),或是输出是有限个离散值(称分类)
无监督学习
可以由输入数据中学到或建立一个模型,并依此模型推测新的结果。输入数据是由输入特征值所组成。
分类是监督学习的一个核心问题,在监督学习中,当输出变量取有限个离散值时,预测问题变成分类问题。最基础的便是二分类问题,判断是非,从俩个类别中选择一个作为预测结果:

数据1公司本身就有数据2合作过来的数据3购买的数据
建立模型:根据数据类型划分应用种类
算法+数据
1,原始数据:明确问题做什么
2,数据的基本处理:pd去处理数据(缺失值,合并表。。
3,特征工程(特征进行处理)(重要)
回归问题
分类问题
4,找到合适算法去进行预测
5,模型的评估,判定效果(没有合格1换算法(参数
上线使用,以API形式提供
总结:
1特征抽取onehot编码,
文本记录词语重要性或词频
2特征预处理
数值型数据:归一化,标准化
标准化:平均值,标准差
3特征降维:
算法分类:
监督学习
非监督学习
目标值离散还是连续;分类,回归
分类算法
sklearn数据集
1,数据集划分2,sklearn数据集接口介绍3,sklearn分类数据集4,sklearn回归数据集
数据:1,训练模型 2,评估(未知数据
训练集75%测试集25%
建立模型 评估模型
算法(分类回归聚类)
sklearn数据集划分API
sklearn.model_selection.train_test_split
scikit-learn数据集API介绍
sklearn.datasets
加载获取流行数据集
datasets.load_*()
获取小规模数据集,数据包含在datasets里
datasets.fetch_*(data_home=None)
获取大规模数据集,需要从网络上下载,函数的第一个参数是data_home,表示数据集下载的目录,默认是~/scikit_learn_data/





