
深入理解人工智能的基石
一、前馈神经网络概述
前馈神经网络(Feedforward Neural Network, FNN)是神经网络中最基本和经典的一种结构,它在许多实际应用场景中有着广泛的使用。在本节中,我们将深入探讨FNN的基本概念、工作原理、应用场景以及优缺点。
什么是前馈神经网络
前馈神经网络是一种人工神经网络,其结构由多个层次的节点组成,并按特定的方向传递信息。与之相对的是递归神经网络,其中信息可以在不同层之间双向传递。

结构特点: 由输入层、一个或多个隐藏层和输出层组成。
信息流动: 信息仅在一个方向上流动,从输入层通过隐藏层最终到达输出层,没有反馈循环。
前馈神经网络的工作原理

前馈神经网络的工作过程可以分为前向传播和反向传播两个阶段。
前向传播: 输入数据在每一层被权重和偏置加权后,通过激活函数进行非线性变换,传递至下一层。
反向传播: 通过计算输出误差和每一层的梯度,对网络中的权重和偏置进行更新。
应用场景及优缺点
前馈神经网络在许多领域都有着广泛的应用,包括图像识别、语音处理、金融预测等。
优点:
结构简单,易于理解和实现。
可以适用于多种数据类型和任务。
缺点:
对于具有时序关系的数据处理能力较弱。
容易陷入局部最优解,需要合理选择激活函数和优化策略。
二、前馈神经网络的基本结构
前馈神经网络(FNN)的基本结构包括输入层、隐藏层和输出层,以及相应的激活函数、权重和偏置。这些组成部分共同构成了网络的全貌,并定义了网络如何从输入数据中提取特征并进行预测。本节将详细介绍这些核心组成部分。
输入层、隐藏层和输出层
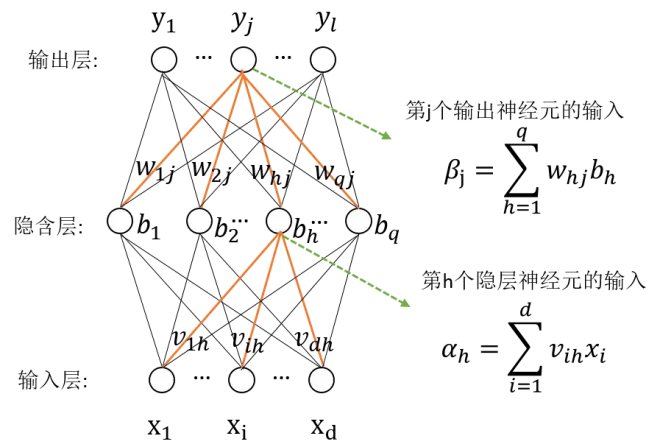
前馈神经网络由三个主要部分组成:输入层、隐藏层和输出层。
输入层: 负责接收原始数据,通常对应于特征的维度。
隐藏层: 包含一个或多个层,每层由多个神经元组成,用于提取输入数据的抽象特征。
输出层: 产生网络的最终预测或分类结果。
激活函数的选择与作用
激活函数是神经网络中非常重要的组成部分,它向网络引入非线性特性,使网络能够学习复杂的函数。

常见激活函数: 如ReLU、Sigmoid、Tanh等。
作用: 引入非线性,增强网络的表达能力。
网络权重和偏置

权重和偏置是神经网络的可学习参数,它们在训练过程中不断调整,以最小化预测错误。
权重: 连接各层神经元的线性因子,控制信息在神经元之间的流动。
偏置: 允许神经元在没有输入的情况下激活,增加模型的灵活性。
三、前馈神经网络的训练方法

前馈神经网络(FNN)的训练是一个复杂且微妙的过程,涉及多个关键组件和技术选择。从损失函数的选择到优化算法,再到反向传播和过拟合的处理,本节将深入探讨FNN的训练方法。
损失函数与优化算法
损失函数和优化算法是神经网络训练的基石,决定了网络如何学习和调整其权重。
损失函数: 用于衡量网络预测与实际目标之间的差异,常见的损失函数包括均方误差(MSE)、交叉熵损失等。
优化算法: 通过最小化损失函数来更新网络权重,常见的优化算法包括随机梯度下降(SGD)、Adam、RMSProp等。
反向传播算法详解
反向传播是一种高效计算损失函数梯度的算法,它是神经网络训练的核心。
工作原理: 通过链式法则,从输出层向输入层逐层计算梯度。
权重更新: 根据计算的梯度,使用优化算法更新网络的权重和偏置。
避免过拟合的策略
过拟合是训练神经网络时常遇到的问题,有多种策略可以减轻或避免过拟合。
早停法(Early Stopping): 当验证集上的性能停止提高时,提前结束训练。
正则化: 通过在损失函数中添加额外的惩罚项,约束网络权重,例如L1和L2正则化。
Dropout: 随机关闭部分神经元,增加模型的鲁棒性。
四、使用Python和PyTorch实现FNN
在理解了前馈神经网络的理论基础之后,我们将转向实际的编程实现。在本节中,我们将使用Python和深度学习框架PyTorch实现一个完整的前馈神经网络,并逐步完成数据准备、模型构建、训练和评估等关键步骤。
4.1 准备数据集
准备数据集是构建神经网络模型的第一步。我们需要确保数据的质量和格式适合神经网络训练。
选择合适的数据集
选择与任务匹配的数据集是成功训练模型的关键。例如,对于图像分类任务,MNIST和CIFAR-10等都是流行的选择。
数据预处理
预处理是准备数据集中的重要步骤,包括以下几个方面:
数据标准化/归一化: 将数据转换为具有零均值和单位方差的形式,有助于模型的训练和收敛。
数据增强: 通过旋转、剪裁、缩放等手段增加数据的多样性,有助于提高模型的泛化能力。
划分训练集、验证集和测试集: 合理的数据划分有助于评估模型在未见数据上的性能。
PyTorch数据加载器
PyTorch提供了DataLoader类,可用于批量加载和混洗数据,使训练过程更加高效。
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
4.2 构建模型结构
在准备了适当的数据集之后,我们将转向使用Python和PyTorch构建前馈神经网络(FNN)的模型结构。构建模型结构包括定义网络的架构、选择激活函数和初始化权重等关键步骤。
定义网络架构
我们可以使用PyTorch的nn.Module类来定义自定义的网络结构。以下是一个具有单个隐藏层的FNN示例。
import torch.nn as nnclass SimpleFNN(nn.Module): def __init__(self, input_dim, hidden_dim, output_dim): super(SimpleFNN, self).__init__()
self.hidden_layer = nn.Linear(input_dim, hidden_dim)
self.output_layer = nn.Linear(hidden_dim, output_dim)
self.activation = nn.ReLU() def forward(self, x):
x = self.activation(self.hidden_layer(x))
x = self.output_layer(x) return x
选择激活函数
激活函数的选择取决于特定的任务和层类型。在隐藏层中,ReLU通常是一个良好的选择。对于分类任务的输出层,Softmax可能更合适。
权重初始化
合适的权重初始化可以大大加快训练的收敛速度。PyTorch提供了多种预定义的初始化方法,例如Xavier和He初始化。
def init_weights(m): if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
m.bias.data.fill_(0.01)
model = SimpleFNN(784, 256, 10)
model.apply(init_weights)
构建与任务相匹配的损失函数
损失函数的选择应与特定任务匹配。例如,对于分类任务,交叉熵损失是一个常见的选择。
loss_criterion = nn.CrossEntropyLoss()
4.3 训练模型
一旦构建了前馈神经网络(FNN)的模型结构,下一步就是训练模型。训练过程涉及多个关键步骤和技术选择,如下所述:
选择优化器
优化器用于更新模型的权重以最小化损失函数。PyTorch提供了多种优化器,例如SGD、Adam和RMSProp。
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.001)
训练循环
训练循环是整个训练过程的核心,其中包括前向传递、损失计算、反向传播和权重更新。
for epoch in range(epochs): for data, target in train_loader:
optimizer.zero_grad()
output = model(data)
loss = loss_criterion(output, target)
loss.backward()
optimizer.step()
模型验证
在训练过程中定期在验证集上评估模型可以提供有关模型泛化能力的信息。
调整学习率
学习率是训练过程中的关键超参数。使用学习率调度程序可以根据训练进展动态调整学习率。
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.7)
保存和加载模型
保存模型权重并能够重新加载它们是进行长期训练和模型部署的关键。
# 保存模型torch.save(model.state_dict(), 'model.pth')# 加载模型model.load_state_dict(torch.load('model.pth'))
可视化训练过程
使用例如TensorBoard的工具可视化训练过程,有助于理解模型的学习动态和调试问题。
4.4 模型评估与可视化
完成模型的训练之后,接下来的关键步骤是对其进行评估和可视化。这可以帮助我们理解模型的性能,并发现可能的改进方向。
评估指标
评估模型性能时,需要选择与任务和业务目标相符的评估指标。例如,分类任务常用的指标有准确率、精确率、召回率和F1分数。
from sklearn.metrics import accuracy_score# 计算准确率accuracy = accuracy_score(targets, predictions)
模型验证
在测试集上验证模型可以提供对模型在未见过的数据上性能的公正评估。
混淆矩阵
混淆矩阵是一种可视化工具,可以揭示模型在不同类别之间的性能。
from sklearn.metrics import confusion_matriximport seaborn as sns
cm = confusion_matrix(targets, predictions)
sns.heatmap(cm, annot=True)
ROC和AUC
对于二元分类任务,接收者操作特性(ROC)曲线和曲线下面积(AUC)是流行的评估工具。
特征重要性和模型解释
了解模型如何做出预测以及哪些特征对预测最有影响是可解释性分析的关键部分。
可视化隐藏层
通过可视化隐藏层的激活,我们可以深入了解网络是如何学习和表示输入数据的。
