
CPU/GPU封装第二期——多芯封装的命运前夜
上期我们梳理了芯片生产的整个过程,并着重分析了芯片封装从打线封装到覆晶封装的技术进步,感兴趣的网友可以移步上期专栏;再次重申,本人技术力有限,如有错误,欢迎网友们指出纠正,我将不胜感激
我们这期看看厂家为了提升芯片性能,都做了哪些努力

其一是优化架构
增加架构规模可以很好的提升芯片的计算能力,实现相同周期内执行更多的简单指令或者执行同样数量但功能更强大的复杂指令(如光追和AVX512);但随着架构规模的增大,晶体管数量也会增加,更高效率的架构设计显然可以节省晶体管,毕竟在制造工艺不变的情况下,晶体管数量越多,功耗自然越大


其二是提升工作频率(也就是超频)
这个也很好理解,提升频率就相当于缩短每个计算周期的用时,哪怕一个周期内的执行能力没有改变,但在同样时间内执行了更多的周期次数,也能提升性能;假设一颗芯片原本跑在1GHz的频率,让它超频跑在1.5Ghz,这样可以马上让它的执行速度提升50%,然而提频的代价是会让芯片变得不稳定;为了使芯片稳定跑在高频,将需要更高的驱动电压,这会催生功耗的急剧上升

其三就是使用更先进的制造工艺
提升制造工艺的目的就是制造尺寸更小、漏电率更小的晶体管,这可以让单位面积内的硅片塞下更多晶体管,并且能以更低的电压驱动芯片,这两项进步共同抵消架构规模和频率提升造成功耗增加的负面影响

然而芯片的集成电路规模越来越大,晶体管数量也越来越多,随之面临的芯片设计和生产难度成指数级上升(成本也噌噌往上涨)
提升芯片性能面对的挑战
芯片设计师设计芯片时,会首先规划好一些可以实现特定计算任务的简单电路,它们由若干晶体管组成,这被称为标准单元库(Satndard Cell Library);将单元库模自由组建成适应市场需求的核心IP,这可以减少大量的冗余工作,使架构设计标准化、模块化,大大提高设计速度(划重点,待会儿会考到)
打个比方,假如我们拼乐高积木,不可能从买桶合成塑料开始手搓乐高零件,正常人(确信)所理解的最小组成单位是一个个乐高零件;芯片架构师眼中的标准单元库就相当于乐高中的基础零件,在乐高芯片设计师的步步构建下,一个核心IP,设计出来力

一个有趣的共通点是,所有现代芯片都采用了多核心设计:截至目前,消费端CPU,AMD有16核32线程,英特尔有8大核16小核32线程;服务器端的EPYC堆到了96核192线程,甚至是128核256线程;GPU的每个流处理器都算一个核心的话,更是成百上千的规模
我们常听到“一核有难,九核围观”之类调侃多核无用论的笑话,不禁要问:为什么不设计一个超强的单核去完成几个核心才能完成的事呢?这样不就没有多核优化的难题了吗?
答案是可以,但代价很大
正如我前面所说,提升架构规模的前提是保证晶体管效率,当一个核心晶体管增加的幅度远大于实际执行能力的提升幅度,这意味着单核性能的提升开始接近瓶颈,堆多核是个更有效的选择
让我们拿一个实例分析,这里借用极客湾对12900K的测试数据,请关注蓝色部分(不参考橙色功耗部分原因:小核功耗是拿核心全开功耗减去关闭小核的功耗,这168.2W的“大核功耗”其中包含如内存控制器、PCIE控制器等外围设备的非核心功耗,这些非核心功耗极客湾未另作标识,纯核心功耗和整体功耗不具有比较意义,因此不予采纳)

36%的数值似乎不多,那我们结合Die Shot对比大小核面积

假如一个大核的面积是1,八个大核的面积是8,八小核的面积是2,那么从面积上考虑
2÷8×100%=25%
八个小核用不到25%的面积达到了八个大核36%的性能,这样好像还不够明显,那就假设把原先大核的位置全部替换成小核,得到一个面积上和原先差不多的纯40小核处理器
如果八个大核的性能是100%,八大核八小核的性能就是
100%+36%=136%
40个纯小核的性能就是
40÷8×36%=180%
两种设计的性能差距就是
(180%-135%)÷135%≈33.3%
通过将核心全换成小核的操作,我们立即获得了超过33%的全核性能提升
假如处理器就是一个工厂,一个核对应一条生产线,我们可以下大价钱优化设备,培训工人熟练度,提升单条产线的速度;但产速不可能无限增加,最终会达到瓶颈,死亡流水线是不可取的,要照顾工人情绪的嘛(你明白我要说什么)既然一条产线不够,那就再加一条,没什么是加产线所不能解决的!对应的,处理器核心就越加越多了~
现在明白英特尔为什么要梭哈大小核了吧?要单核多核性能两手抓,还要严格控制成本,这既要又要的要求不上大小核的话,很难做呀~(暴论:AMD的Zen4c也算小核~)
至于多核优化,我认为这是现代软件开发所必须考虑的问题,假如程序对计算系统有更高的性能请求,操作系统拨分了更多的资源,就更应做好硬件调度,否则就不应该觊觎更多的计算机资源,软件对硬件需求的无理增长是非常无耻的行为(告诫の心)
我预计未来处理器的进步方向是:核心数有进一步增加的可能,并且大小核设计也将越来越常见
除了加核心,咱还可以加缓存(这个也划重点,待会儿会考到)
在一个典型的计算机系统中,处理器(CPU)执行运算是要向内存(Memory)读写数据的,随着CPU性能快速进步,内存的读写速度逐渐开始跟不上CPU,这造成了性能瓶颈,为了避免CPU干等内存传输数据的窘况,设计师开始引入缓存(Cache)这一结构

缓存的设计目标是存储访问热点高的数据,减少CPU等待时间;CPU请求数据时,先在缓存内找:假如恰好是需要的数据,高速的缓存将显著减少CPU的等待时间,这称之为缓存命中(Cache hit);假如缓存内没有想要的数据,CPU再向慢得多的内存请求,这称之为缓存未命中(Cache miss)
衡量一个缓存系统的性能,除了看它的读写速度、容量、延迟,还有个重要指标:即缓存命中率(Cache hit rate),关于它的计算方法可表示为
命中率=命中数÷总请求数×100%
缓存的出现极大解决了CPU运算速度与内存读写速度不匹配的矛盾;缓存的速度非常快,可以与CPU的运算速度相匹配,假如缓存的命中率很高,CPU需要计算的数据大概率都能在缓存内找到,那么就能大大减少等待内存传输数据的频次,提高运算速度,这催生了分层存储的概念
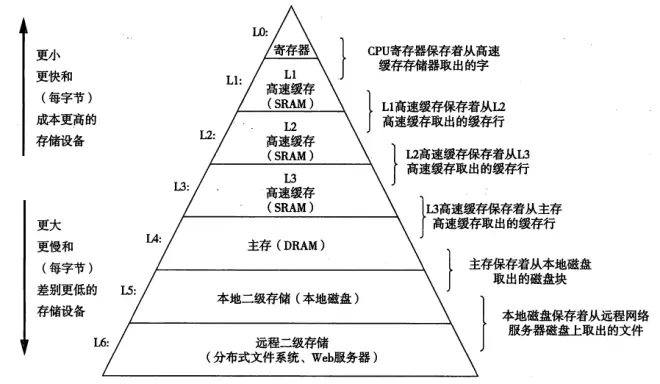
匹配CPU速度的缓存制造成本非常高,容量很低,容量做大,成本爆炸~这也是缓存不能完全替代内存的原因;既然设计师采用了分层存储理念,索性贯彻到底:将一部分缓存速度缩减,但容量增加不少,为了表示区分,和CPU同速的缓存称L1缓存,较之慢一些的称L2缓存;虽然L2比L1慢了不少,但是只要它的速度、延迟还是比内存快,这样的缓存结构设计仍然是值得的

我们假设一个缓存系统,L1缓存的命中率为70%,这意味着CPU请求的每100条数据中,有70条可以在L1缓存中找到,但仍有30条需要在内存里找;可当我们再引入L2缓存,命中率还是70%,那在L1未命中的30条数据再在L2中找,我们可以找到21条,于是,最后只剩下9条数据需要去内存里找了,这样算下来,这个二级缓存系统的命中率就达到了91%
1-(100%-70%)²=91%
以此套娃,设计师在现代处理器中创造了多级缓存系统,目的就是为了优化缓存效率,提高缓存系统的命中率;CPU查找数据时依照读写速度,从快到慢为L1缓存、L2缓存、L3缓存……最终到内存,容量则依次递增

(据说十四代酷睿要引入L4缓存的说)
还有就是CPU附件的集成和加入针对特定应用场景优化的加速模块(如视频编解码模块)或者说协处理器,结合下面生产工艺马上就会说到
设计之后的生产挑战
晶圆厂表示,道理我都懂,但是突然要加核心、加缓存,我生产压力很大呀~(要加钱!)
现代芯片都是拿光刻机造的(路边小作坊手搓的不算)顾名思义,光刻机就是利用光在硅片上曝光、显影、蚀刻电路的,想要在一定面积内塞下更多晶体管,必然要把电路蚀刻得更精细,我们常听说的14nm、10nm、7nm等等名词,就是厂家在宣传他们缩小晶体管所做的努力
这里不得不提到一段非常著名的话
“集成电路芯片上所集成的电路的数目,每隔18个月到24个月就翻一番”
业内称之为“摩尔定律”,但其实我个人更倾向于称为“摩尔战略”,因为这并不是一个真的物理定律,这句话更像是一家企业对于芯片行业与消费者的庄严承诺:即在18到24个月的时间里,提供晶体管翻倍的处理器;这就是我个人不愿称之为“摩尔定律”的原因,这更像是芯片厂对于自身技术快速迭代进步的严格要求,推动芯片行业高速进步的同时保持在业内的领先地位,同时也在逼迫竞争对手追赶,赶不上就面临快速淘汰的败局
在紧凑的时间节点内快速推出迭代产品,这对设计端和生产端都是极大的挑战,稍有不慎就会面临架构或工艺翻车的情况
早期CPU受限于设计和生产能力,设计非常纯粹,纯粹到只有计算功能,以致于需要许多附件芯片,也就是芯片组才能搭建一个完整的计算机系统,这与现代处理器高度集成化有着巨大差异


像前面提到的L2缓存,早期也是不集成在CPU内部的

当时对缓存的命名,除了L1、L2的区分方式,还可称CPU内部的缓存叫内部高速缓存(Internal Cache),主板上的缓存叫外部高速缓存(External Cache)

就以提到的L2缓存举例,以现在的眼光看,我们是希望将它和CPU集成到一起的,这能提高计算速度,为什么这么说呢?

假如我们在家肚子饿了,楼下和十公里外各有一家饭店,味道都还行,你更愿意到楼下还是走十公里去吃个饭呢?反正我是到楼下~
甚至现在外卖产业蓬勃发展,连楼都不用下,我们可以足不出户,一日三餐靠外卖就能解决了,肥宅的钱真好赚啊(不是)
将CPU和L2缓存集成到一起,可以进一步降低CPU的等待时间,而且数据传输的物理距离更短,也能节省一定功耗,但正如前面所言,前途是光明的,道路是曲折的,一口气把CPU和缓存制造在同一晶片上,对于当时芯片厂的设计和生产端,都是不小的挑战
于是芯片厂一合计,既然目前的技术难以支撑一次性完成如此巨大的架构革新,那就把带L1缓存的CPU部分和L2缓存部分分开制造,再将它们封装到一起,这样也能解决问题啊,等到未来的设计和工艺成熟,再将CPU和缓存完全融合到一片晶片上也不迟
在这样的背景下,划时代的平面多芯封装技术诞生了

所以说,多芯封装的出现平衡了芯片规模增长和制造成本之间的矛盾,这种“偷鸡”虽带着妥协的意味,但也体现了芯片工程师的巧思
说到底,懒还是人类科技进步的动力呀~
人越懒,科技就越进步,越进步,工作完成量越高,完成量越高越显得人勤快,所以人越懒,人越勤快~

点赞投币越多,三连越积极,更新下期的视频就越快~(图穷匕见了属于)
To be continued…
