
Huggingface学习:用AI做情感分析
Huggingface 入门
学会使用huggingface就能够调用人工智能的各种模型和数据集来开展语言教学和研究。
下面以句子情感分析(sentiment analysis)为例,演示一下如何安装使用huggingface的transformers库。直接上代码:
第一次运行的结果如下:
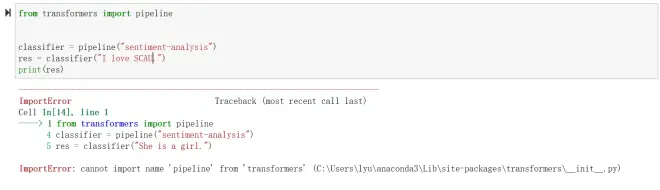
无法导入pipeline!
可能的原因:transformers的版本太低了。因为安装Anaconda时,默认安装了2.1.1版本。现在需要升级。如需查询版本,可以在jupyternotebook中输入以下代码,运行,即可查看结果:
升级办法:
然后重启jupyternotebook,再次检验版本

果然是最新版了,但要求再安装PyTorch或TensorFlow.
那就安装一个TensorFlow试试:

安装过程需要时间,耐心等待。TensorFlow安装成功后,再次运行最开始的情感分析代码。
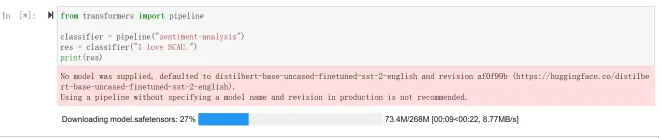
在自动下载一些model和package,成功后,即给出情感分析结果。

自动判定“I love SCAU."这句话的情感是积极的,结果正确。
再测试一下,可以输入一个列表,里面很多句话。

虽然还是有警告,但结果也还不错。
补充知识:什么是transformers?什么是pipeline?
在自然语言处理领域,Transformers库是一个备受欢迎的工具。这个库提供了各种各样的模型和工具,可以用于许多任务,如文本分类、命名实体识别、问答系统等。其中最为方便的工具之一就是Pipeline。
Pipeline是Transformers库的一个高级API,可以轻松地将多个处理步骤(如分词、实体识别、文本分类等)组合成一个管道,从而实现一条指令完成多个自然语言处理任务。可以说,Transformers库中最基本的对象是pipeline(管道),将模型与其他必要预处理和后处理步骤组合起来,使我们可以直接输入任何文本并获得可理解的答案。
Pipeline
1. Pipeline的介绍
在自然语言处理中,常常需要执行多个任务,例如将一段文本分词、去除停用词、提取关键词等。使用Pipeline可以将这些任务连接成一个完整的处理流程。Pipeline的API简单易用,可以自动选择最合适的模型,并且在处理时实现自动批处理。具体来说,Pipeline提供了一种简单的方法,可以将以下任务链接在一起:
文本预处理(分词、停用词处理、标点符号去除等)
特征提取(向量化、TF-IDF权重计算等)
模型选择和调参
输出结果(如文本分类、情感分析等)
使用Pipeline,只需要提供文本输入,即可轻松地获取输出结果。这种API非常适合快速开发原型,并且在生产环境中提供了方便的部署方式。
2. Pipeline的原理
在Pipeline内部,首先对输入文本进行预处理。这通常涉及到将文本转换成tokens序列,并且进行停用词处理、标点符号去除等操作。接着,Pipeline将序列输入到模型中,这个模型通常是由Transformers架构组成的。
对于每个任务,Pipeline都会选择一个适当的模型和适当的参数。例如,对于文本分类任务,Pipeline可能会选择一个适当的分类器,并且使用适当的参数来优化这个分类器。这个过程通常是由预先定义的管道组件组成的。
最后,Pipeline将模型的输出转换为特定任务的输出格式。例如,对于文本分类,输出可能是一个字符串,表示文本属于哪个类别。对于命名实体识别,输出可能是一个包含实体名称和实体类型的列表。
3. Pipeline的代码演示
让我们来看一个实际的例子,使用Pipeline对一些电影评论进行情感分析。
首先,我们需要安装Transformers库,这可以通过以下命令完成:
然后,我们可以使用以下代码来加载Pipeline:
我们在pipeline中仅传入任务名称sentiment-analysis(情感分析),此时,管道默认选择一个特定的预训练模型,该模型已经对英文情感分析进行了微调。第一次运行会下载并缓存该模型。
这个代码将打印出以下输出:
这个输出表示,输入的文本是“积极”的,并且对应的置信度非常高。
这里的Pipeline自动选择了适当的模型和参数,以最大化分类的准确性。我们可以通过更改分类器来尝试不同的模型,例如:
这个分类器使用了一个不同的模型,并且针对情感分类任务进行了微调。
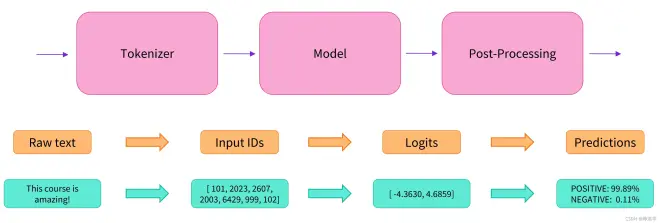
将一些文本传递到管道时涉及三个主要步骤:
预处理: 文本被预处理为模型可以理解的格式
输入模型: 构建模型,将预处理的输入传递给模型
后处理: 模型预测的结果经过后处理,变成人类可理解的格式
目前可用的一些管道有:
feature-extraction (获取文本的向量表示)
fill-mask填充给定文本中的空白(完形填空)
ner (named entity recognition)词性标注
question-answering问答
sentiment-analysis情感分析
summarization摘要生成
text-generation文本生成
translation翻译
zero-shot-classification零样本分类
4. Pipeline的优势
Pipeline的一个优点是,它提供了一个简单易用的API,可以快速地开发原型,从而快速地检测模型的性能。另一个优点是,Pipeline自动选择适当的模型和参数,从而提高了模型的准确性。Pipeline还可以通过将多个任务组合在一起来实现复杂的自然语言处理任务。
此外,Pipeline还可以在CPU和GPU上运行,从而实现更高的处理速度。对于大型数据集,Pipeline可以自动进行批处理,从而提高了处理速度。最后,Pipeline提供了一种简单的方式,可以将模型部署到生产环境中。
Pipeline的背后
让我们从一个完整的例子开始,看看当我们在执行以下代码时,幕后发生了什么:
运行结果:
这个管道将三个步骤组合在一起:预处理、传递输入到模型和后处理:
更详细的说明请参考官网教程(https://huggingface.co/docs/transformers/index)或https://blog.csdn.net/yjw123456/article/details/125192900。
参考文献:
1. http://www.xbhp.cn/news/92821.html
2. https://blog.csdn.net/yjw123456/article/details/125192900
3.官网教程:https://huggingface.co/docs/transformers/index
