
【AI绘画进阶篇】(手把手教你炼丹)喂饭级LoRA模型训练教程(上)

前言
LoRA,全称Low-Rank Adaptation of LargeLanguage Models,直译为大语言模型的低阶适应。LoRA的作用是可以让结果倾向于一种风格,比如使用水墨风LoRA可以使结果是水墨风格,使用人物LoRA可以使人物趋向于一种样貌。
本篇文章的目的就是私人订制(训练)一个专属于你自己的LoRA,可以是你自己,也可以是你身边的人,也可以是游戏人物、一件物品等等。然后使用训练出来的LoRA可以让Ai绘画出来的人完全像你训练的人、画出的物品像训练的物品。
看到这里是不是心动了?心动了就坚持朝下看,相信你不会失望!

准备工作
需要用到Stable Diffusion和LoRA模型训练程序。B站自己找或者我已经整理好了放
在资源大后方(公众hao 十万个肿么办,回sd、Lora)。
学会本地部署Stable Diffusion:喂饭级stable diffusion本地部署教程
学会本地部署LoRA模型训练包:【AI绘画进阶篇】喂饭级LoRA模型训练包安装教程
更多基础教学移步本人主页,相关文章合集《Stable Diffusion人工智能绘图教程(从安装到精通)》

准备并批量处理图片素材、反推提示词Tgas
收集整理需要训练的人的图片(下面都以训练人物LoRA模型为例),要各种角度、各种时期、各种着装、各种发型等类型,图片最好清晰度尚可,尤其是五官要清晰。整理出20-50张就差不多了。
注意:👇下面所有文件和文件夹的命名不要用中文!请忽视我图片中的自定义文件名,文章中的图片截取自多次的LoRA训练,所以文件名不能保证一致!
图片只是以游戏人物图片为例 推荐使用真人图片
然后我们要把这些图片批量处理成分辨率512*512或者512*768的图片,方法很多,可以使用专业软件如AE、PS,快速出图。
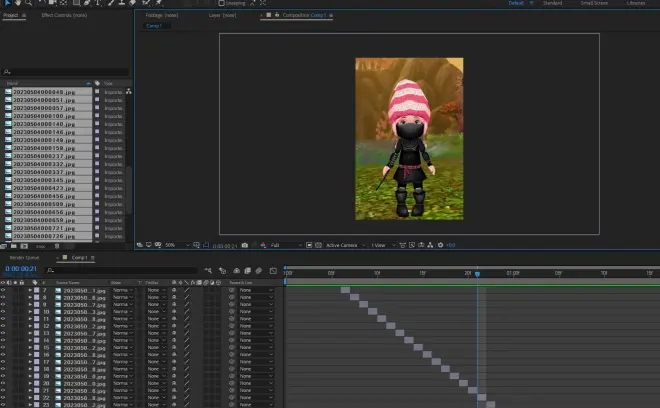
使用AE批量生成相同分辨率的图
也可以使用Stable Diffusion自带的批处理功能(推荐)。
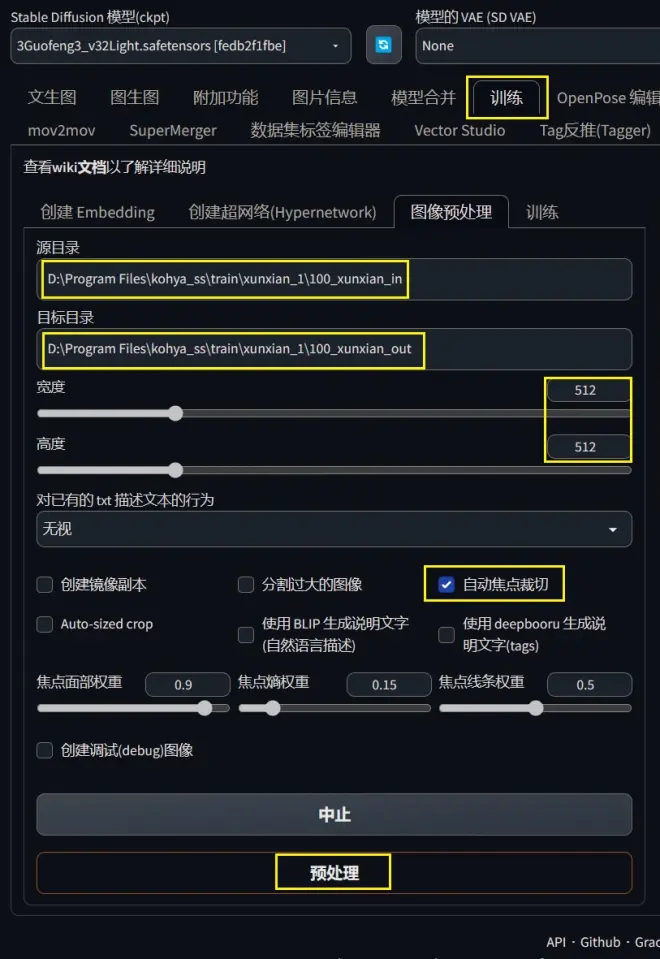
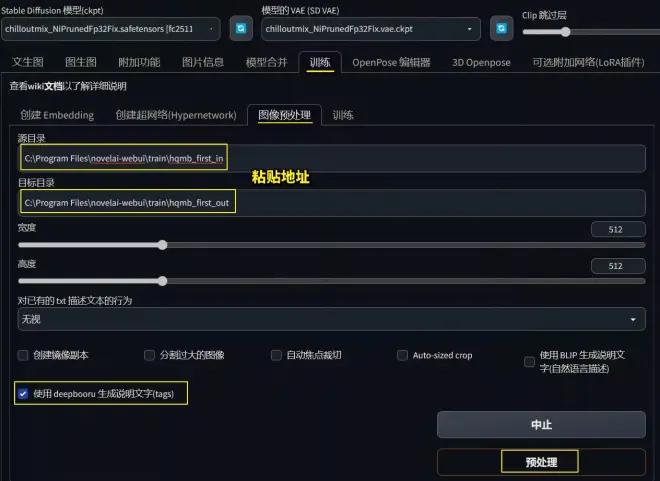
如图,找到训练-图像预处理,粘贴图片所在的文件夹位置,然后再指定一个输出位置,点击“自动焦点裁切”,再点击“预处理”便可以进行自动图片裁切。Ai会智能的裁切并保留图片关键信息,比如人脸部分。但此方法不如用AE一点点手动缩放裁剪调整来的精确,有时候裁切不好的图片可以自行手动裁切。
图片裁切完毕,我们开始进行图片的提示词反推。就是要把每张图片用若干提示词Tag描述一下,这里也不用手动一个个弄,还是使用强大的Stable Diffusion自带的Tag反推功能。
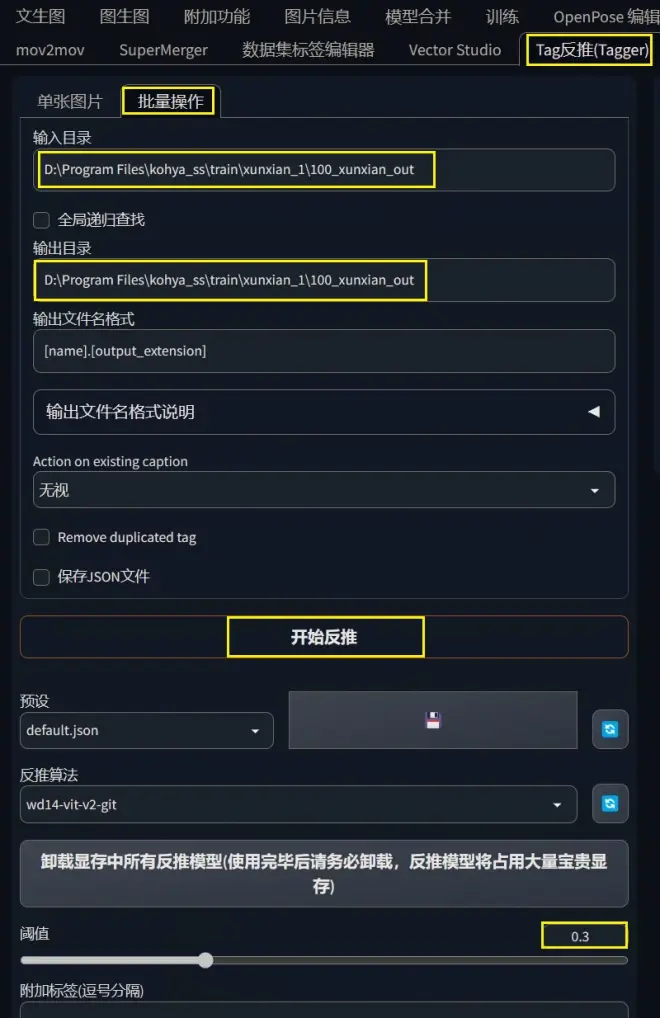
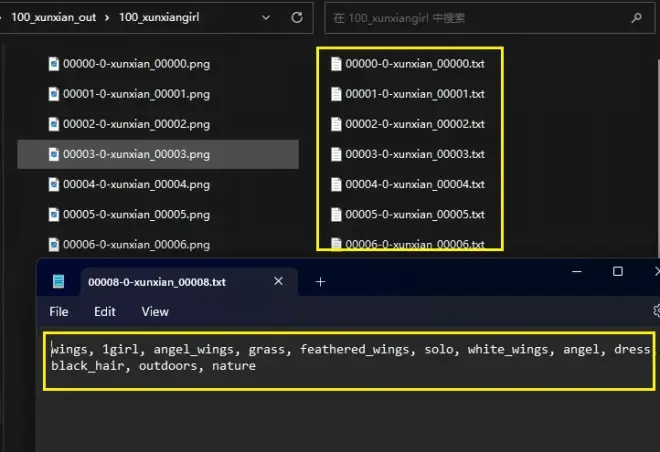
如图所示,来到Tag反推-批量操作,填入图片所在位置路径到输入目录,输出目录和输入目录保持一致,然后点击“开始反推”,稍等片刻,便可以看到图片文件夹里多了txt文本文档,打开之后就可以看到自动反推出的提示词。
PS:另外也可以使用训练-图像预处理中的“使用deepbooru生成说明文字(tags)”来进行提示词的反推。
提示词Tag打标。
这是本篇的重点和难点。
这一步我们要对上一步Ai批量反推出来的提示词Tag进行“打标”操作。所谓提示词打标,也就是一张张核对反推出来的提示词是否准确、是否需要补充一些提示词,然后需要删除一些提示词,添加触发。
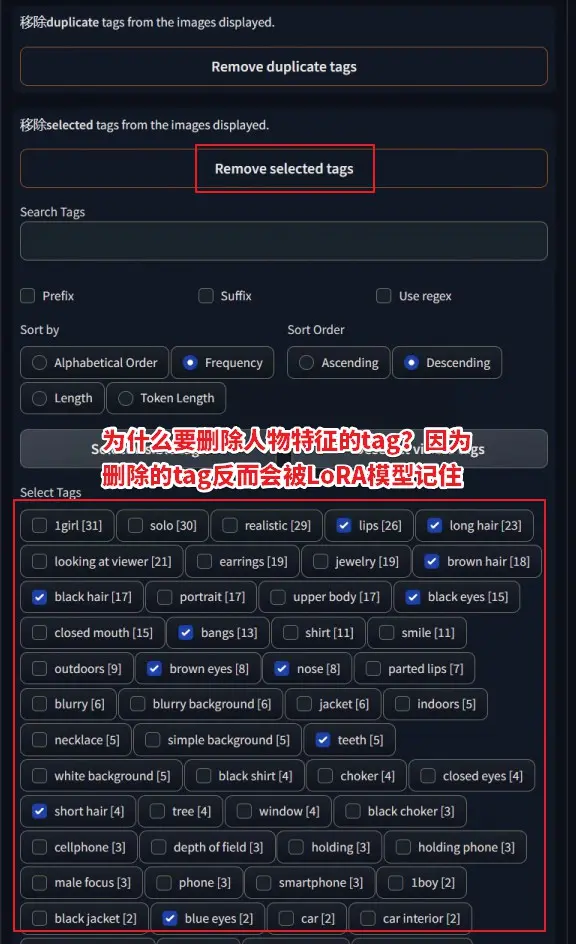
下面针对人物LoRA模型的提示词来说,具体删除哪些类型的提示词,请看下表。

看到这里,有人一定会问,为什么要删除表现人物特征的提示词呢?留着岂不是更有利于Ai训练?
答案是否定的,通俗的理解就是:删除的提示词所表现出的人物特征会被训练进LoRA模型里面,也就是刻进LoRA模型的骨子里,这些特征(比如相貌特征)就无法被改变了,那样才能保证训练出来的模型像指定的人。
而被保留下来的提示词则恰恰相反,是容易被改变的,比如你保留了衣服的提示词,就代表后面我们用这个LoRA模型绘图的时候,可以改变人物的衣服。
下面开始整理提示词,当然这里也有批量处理的工具。
打开Stable Diffusion,安装一个插件【数据集标签编辑器】(具体Stable Diffusion插件安装方法请看这里:Stable Diffusion扩展插件的四种安装方法)。
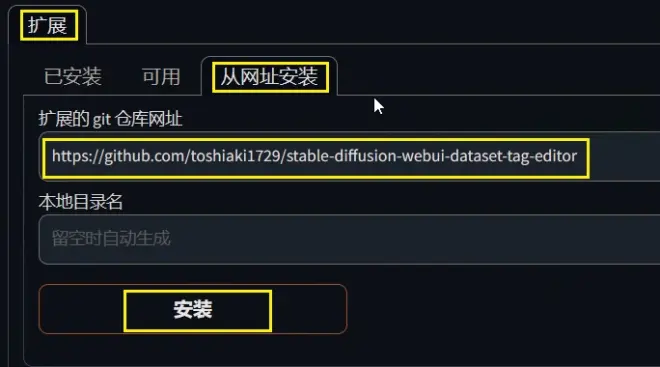
可以通过扩展-从网址安装,填入网址https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor来安装这个插件。
来到【数据集标签编辑器】页面,如下图,填入图片集的目录,点击载入,便可以看到图片被载入进来。
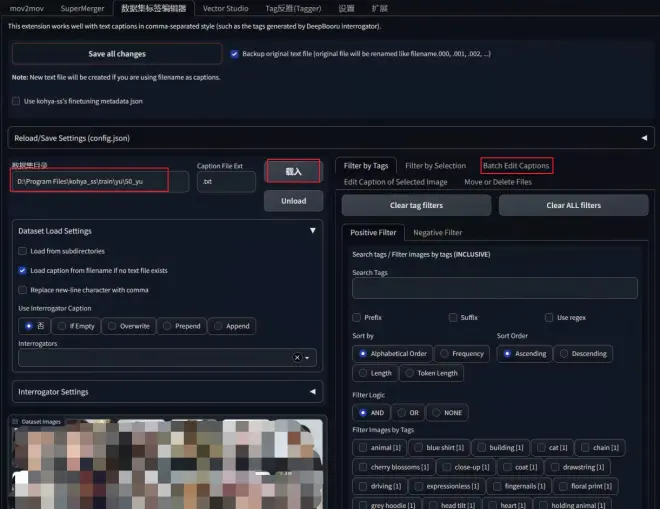
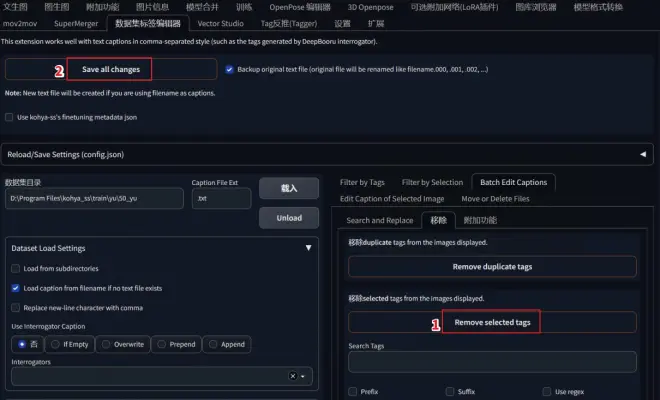
接着来到Batch Edit Captions(批量编辑标题)-“移除”页面,便可以看到图片集中txt文本中的所有提示词都被整理到了这里。可以按照出现频率Frequency排序,我们从中勾选出表现人物特征的提示词。
勾选完毕,点击Remove selected tags,再点击Save all changes,这样txt文本文档中的提示词才会被删除。所以不要忘了点击Save all changes!
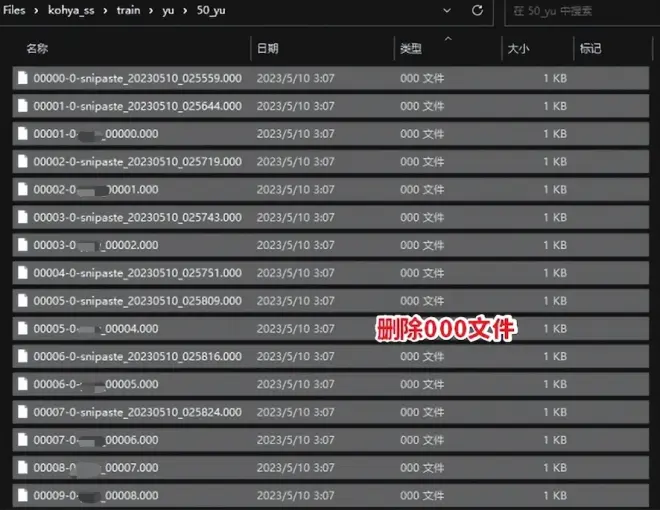
这时候图片文件夹中会出现“000文件”,删除即可。
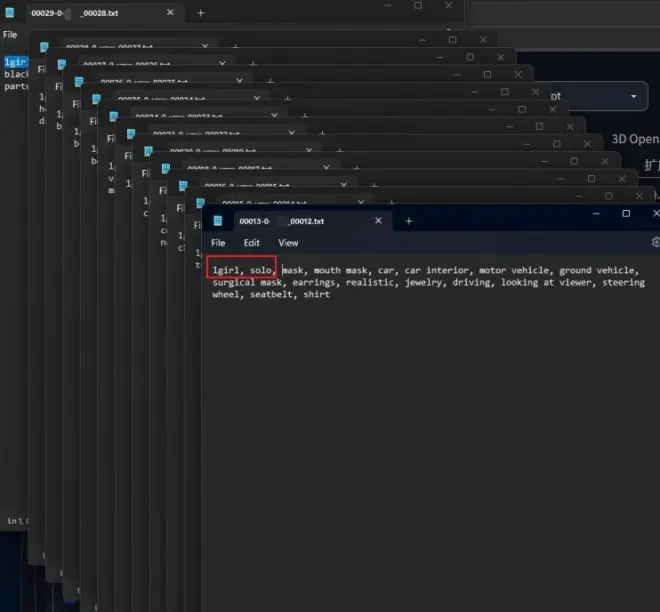
然后手动逐个检查下修改后的txt文本中的提示词,顺便把“1girl,solo,(你的自定义名字)”填到最前面,作为触发词使用。
到这里,提示词打标也差不多做完了。这时候把上面打标好的含有txt文件的文件夹命名为标准格式(很重要,必须以这个格式命名!):
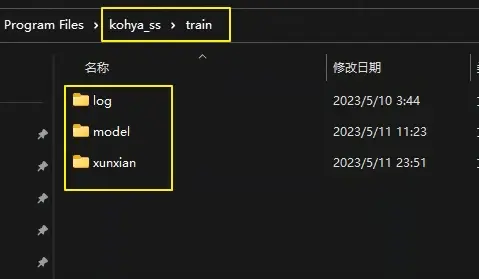
比如,我这里把文件夹命名为50_xunxian,然后在LoRA模型训练包安装的位置:\kohya_ss文件夹下面新建一个train的文件夹用来存放训练数据,并新建log(存放日志)、model(存放训练生成的LoRA模型)、自定义名字文件夹(存放上面做好的图片集,比如这里把50_xunxian文件夹存放到xunxian文件夹中)。
运行LoRA训练程序
下面就要打开我们安装好的LoRA训练软件来进行训练了。
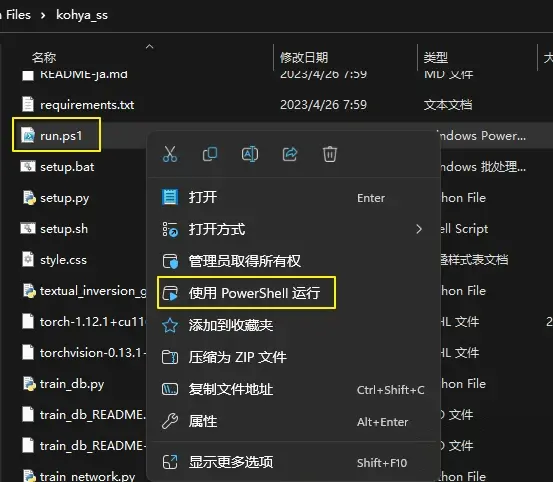
在LoRA训练安装目录\kohya_ss文件夹找到run.ps1文件,右键使用powershell运行。
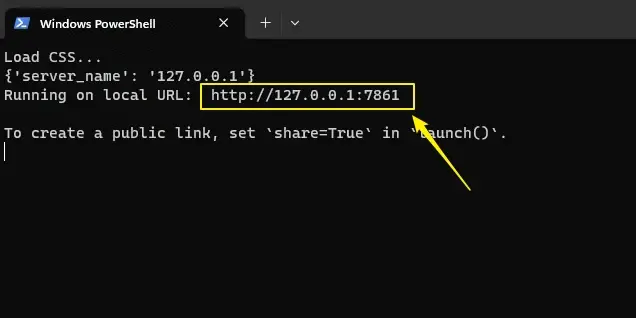
ctrl+鼠标左键点击如图所示网址,便可以进入LoRA模型训练WebUI界面。
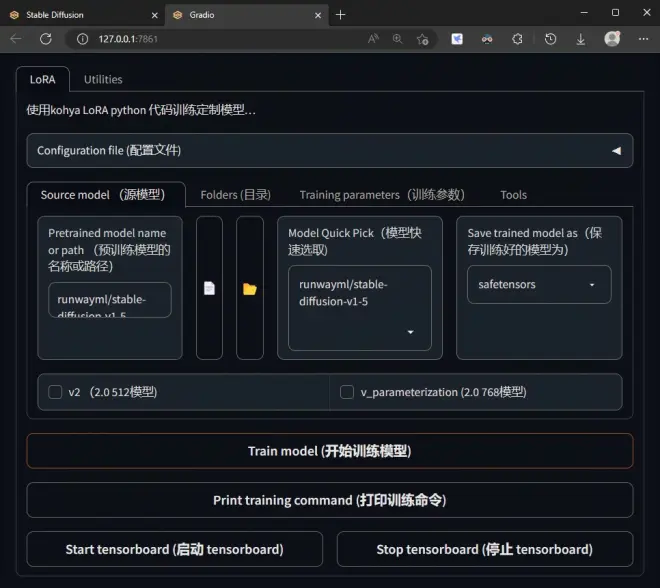
未完待续,请继续阅读合集文章《【AI绘画进阶篇】(手把手教你炼丹)喂饭级LoRA模型训练教程(下)》,下篇的内容着重讲解参数的设置与原理。
更多Stable Diffusion Ai绘画教程请看本人主页 头条@好奇漫步,持续更新更多Ai相关学习教程,保持关注哦~
