
2023.03.27, 03.28, 03.29 ArXiv精选
关注领域:
AIGC
3D computer vision learning
Fine-grained learning
GNN
其他
声明
论文较多,时间有限,本专栏无法做文章的讲解,只挑选出符合PaperABC研究兴趣和当前热点问题相关的论文,如果你的research topic和上述内容有关,那本专栏可作为你的论文更新源或Paper reading list.

Paper list:
今日ArXiv共更新108篇
03.28共更新248篇
03.27共更新128篇
NeRF
HandNeRF: Neural Radiance Fields for Animatable Interacting Hands
https://arxiv.org/pdf/2303.13825.pdf

手势仿真NeRF.
ABLE-NeRF: Attention-Based Rendering with Learnable Embeddings for Neural Radiance Field
https://arxiv.org/pdf/2303.13817.pdf

南洋理工S-Lab的工作.
GM-NeRF: Learning Generalizable Model-based Neural Radiance Fields from Multi-view Images
https://arxiv.org/pdf/2303.13777.pdf
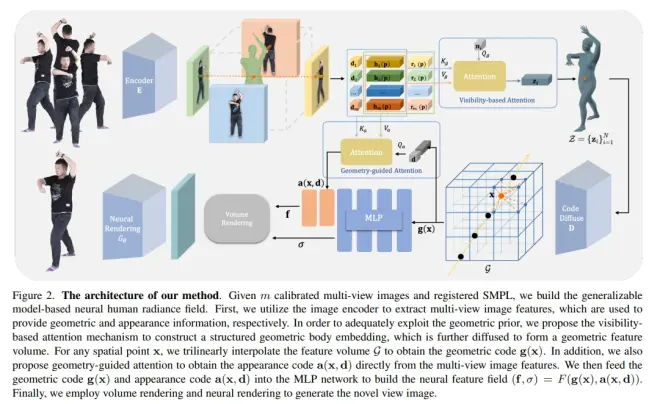
UrbanGIRAFFE: Representing Urban Scenes as Compositional Generative Neural Feature Fields
https://arxiv.org/pdf/2303.14167.pdf

整体思想还是做组合物体生成,但是这篇文章聚焦urban scene. 手速真快啊!
AIGC
MindDiffuser: Controlled Image Reconstruction from Human Brain Activity with Semantic and Structural Diffusion
https://arxiv.org/pdf/2303.14139.pdf

基于脑信号来绘制图像的文章,前段时间非常火.
Fantasia3D: Disentangling Geometry and Appearance for High-quality Text-to-3D Content Creation
https://arxiv.org/pdf/2303.13873.pdf

解耦几何和外观的文本到3D的生成工作,这个领域近半年已经卷成红海了!
CompoNeRF: Text-guided Multi-object Compositional NeRF with Editable 3D Scene Layout
https://arxiv.org/pdf/2303.13843.pdf

又是一篇,组合多物体生成.来自于HKUST. 你们卷吧 我不玩了.
Conditional Image-to-Video Generation with Latent Flow Diffusion Models
https://arxiv.org/pdf/2303.13744.pdf

利用latent flow diffusion model 实现图像到视频的生成任务.
Anti-DreamBooth: Protecting users from personalized text-to-image synthesis
https://arxiv.org/pdf/2303.15433.pdf

一篇防止生成模型类似于DreamBooth,滥用图像的工作.
Debiasing Scores and Prompts of 2D Diffusion for Robust Text-to-3D Generation
https://arxiv.org/pdf/2303.15413.pdf
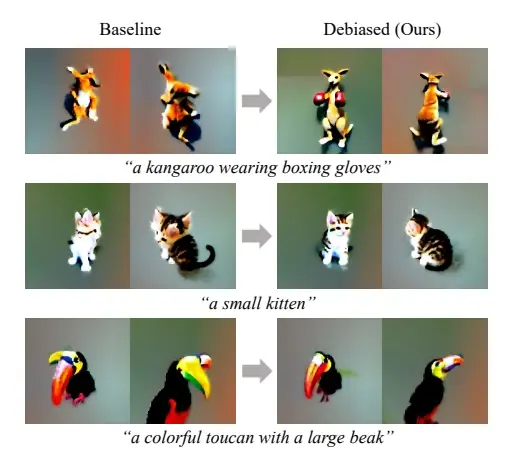
真的是什么样的idea都有,卷不动这个领域.
Text-to-Image Diffusion Models are Zero-Shot Classifiers
https://arxiv.org/pdf/2303.15233.pdf

扩散模型学习到的知识能用来分类吗?很有启发性的工作.
Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior
https://arxiv.org/pdf/2303.14184.pdf

单张图像生成3D物体,感觉做法和Magic3D很类似.
VLP
Best of Both Worlds: Multimodal Contrastive Learning with Tabular and Imaging Data
https://arxiv.org/pdf/2303.14080.pdf

表格数据和图像数据的多模态预训练工作.
Accelerating Vision-Language Pretraining with Free Language Modeling
https://arxiv.org/pdf/2303.14038.pdf

VLP领域做加速的工作,来自腾讯团队.
Prompt Tuning based Adapter for Vision-Language Model Adaption
https://arxiv.org/pdf/2303.15234.pdf

利用prompt tuning来微调VLP大模型
