
2023.03.23 ArXiv精选
关注领域:
AIGC
3D computer vision learning
Fine-grained learning
GNN
其他
声明
论文较多,时间有限,本专栏无法做文章的讲解,只挑选出符合PaperABC研究兴趣和当前热点问题相关的论文,如果你的research topic和上述内容有关,那本专栏可作为你的论文更新源或Paper reading list.

Paper list:
今日ArXiv共更新134篇
NeRF
SHERF: Generalizable Human NeRF from a Single Image
https://arxiv.org/pdf/2303.12791.pdf

南洋理工,ziwei Liu老师团队的工作,实现了第一个输入单张人体图像,实现3D人体重建.
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions
https://arxiv.org/pdf/2303.12789.pdf

UC伯克利的工作,能够实现基于文本的3D场景编辑,属于文本引导的NeRF编辑工作.可拓展到真实场景和大规模场景.
FeatureNeRF: Learning Generalizable NeRFs by Distilling Foundation Models
https://arxiv.org/pdf/2303.12786.pdf

Foundation Model促进NeRF泛化性,促进其在其他下游任务,语义理解和解析等都能取得不错的性能.
Pre-NeRF 360: Enriching Unbounded Appearances for Neural Radiance Fields
https://arxiv.org/pdf/2303.12234.pdf

比Mip-NeRF 360性能还要强大的Pre-NeRF.
AIGC
A PERCEPTUAL QUALITY ASSESSMENT EXPLORATION FOR AIGC IMAGES
https://arxiv.org/pdf/2303.12618.pdf

上海交大的工作,研究了如何评估AIGC产生的图片质量.
SALAD: Part-Level Latent Diffusion for 3D Shape Generation and Manipulation
https://arxiv.org/pdf/2303.12236.pdf

KAIST的工作.主要提出了使用Diffusion model来实现part-level的3D shape的生成和编辑.
VLP
Is BERT Blind? Exploring the Effect of Vision-and-Language Pretraining on Visual Language Understanding
https://arxiv.org/pdf/2303.12513.pdf

本文探讨了,视觉语言预训练能否促进纯文本任务.
CLIP2 : Contrastive Language-Image-Point Pretraining from Real-World Point Cloud Data
https://arxiv.org/pdf/2303.12417.pdf
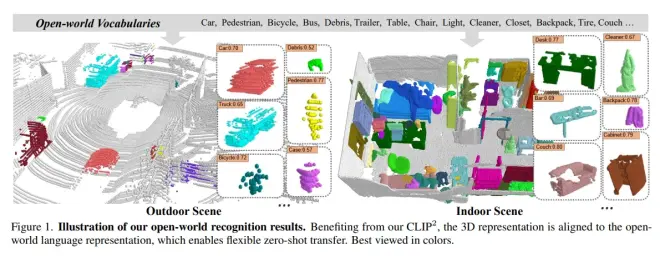
华为诺亚的工作.探讨了CLIP如何促进3D场景级别的理解.
医学图像
Less is More: Unsupervised Mask-guided Annotated CT Image Synthesis with Minimum Manual Segmentations
https://arxiv.org/pdf/2303.12747.pdf

