
文本摘要技术概述
文末福利,自取~
自然语言处理(NLP)是一种使计算机能够理解人类语言的技术。在NLP中,文本摘要是一种将长篇文章或文本压缩为简短摘要的技术,可以简明扼要地对繁杂的信息进行概括,提取关键信息,其在许多领域都有广泛的应用,如新闻报道、市场调查、医学、法律等。
01文本摘要的种类
按照输入文本类型的不同,可以分为单文档文本摘要和多文档文本摘要;按照实现技术方案的不同,可以分为抽取式文本摘要、生成式文本摘要;
抽取式摘要
什么是抽取式摘要?
抽取式文本摘要是一种从原始文本中选择最相关的句子或段落来构成摘要的技术。这种技术使用自然语言处理技术来分析文本并找出其中的重点。重点可以是词、短语、句子或段落。抽取式文本摘要的好处在于它不需要重新编写文本,因为它只是从原始文本中提取信息。
抽取式摘要存在的问题
抽取式摘要在语法、句法上有一定的保证,但是也面临了一定的问题,例如:内容选择错误、连贯性差、灵活性差等问题。生成式摘要允许摘要中包含新的词语或短语,灵活性高,随着近几年神经网络模型的发展,序列到序列(Seq2Seq)模型被广泛的用于生成式摘要任务,并取得一定的成果。
生成式摘要
生成式文本摘要是一种使用自然语言处理技术从原始文本中生成摘要的技术。这种技术需要计算机具有理解语言的能力,并且能够以自然的方式编写文本。生成式文本摘要的好处是它可以生成更自然、更流畅的文本,但缺点是需要更多的计算资源和时间。
生成式摘要存在的问题
生成式摘要优点是相比于抽取式而言用词更加灵活,因为所产生的词可能从未在原文中出现过。但存在以下问题:
1、OOV问题。源文档语料中的词的数量级通常会很大,但是经常使用的词数量则相对比较固定。因此通常会根据词的频率过滤掉一些词做成词表。这样的做法会导致生成摘要时会遇到UNK的词。2、摘要的可读性。通常使用贪心算法或者beam search方法来做decoding。这些方法生成的句子有时候会存在不通顺的问题。3、摘要的重复性。这个问题出现的频次很高。与2的原因类似,由于一些decoding的方法的自身缺陷,导致模型会在某一段连续timesteps生成重复的词。4、长文本摘要生成难度大。对于机器翻译来说,NLG的输入和输出的语素长度大致都在一个量级上,因此NLG在其之上的效果较好。但是对摘要来说,源文本的长度与目标文本的长度通常相差很大,此时就需要encoder很好的将文档的信息总结归纳并传递给decoder,decoder需要完全理解并生成句子。
02常用的文本摘要技术
基于统计学的技术
基于统计学的技术使用统计学方法来确定最相关的句子或段落。它使用诸如词频、文档频率和句子长度等指标来确定重点。这种技术的优点是它简单易用,但它不能捕捉到词语之间的复杂关系。最早的时候人们主要是基于统计学进行抽取式文本摘要,需要计算统计特征,如词频、句子之间的相似性、句子位置、句子与标题(如有)的相似性、句子的相对长度等,首先使用“词频”这一简单的文本特征对文档的重要句子和词组进行抽取生成,根据经验可知,除去停用词以外,文中出现频率越高的单词,其重要性也就越高。根据单词的词频高低分别设置相应的词权重,词频越高,对应的权重也就越高;句子的权重是组成句子单词的权重之和。然后从文档中抽取权重高的单词和句子组成摘要,这就是简单的基于词频的文本摘要方法(这个思路也是很简单易懂)。其它的还有基于tf-idf的文本摘要算法以及其各种改良版。
基于图的技术
基于图的技术使用图来表示文本中的词语和句子之间的关系。图中的节点表示词语或句子,边表示它们之间的关系。使用图来表示文本使得可以更好地捕捉到词语之间的复杂关系。这种技术的缺点是它需要更多的计算资源和时间。如:TextRank仿照PageRank,句子作为节点,构造无向有权边,权值为句子相似度。
基于机器学习/深度学习的技术
基于机器学习的技术使用机器学习算法来确定最相关的句子或段落。它使用已有的文本作为训练数据,然后使用这些数据来训练模型。训练好的模型可以用来预测新的文本中最相关的句子或段落。这种技术的优点是它可以自动学习文本中的关键信息,但需要大量的训练数据和计算资源。其中,机器学习使用较为广泛的有朴素贝叶斯算法、隐马尔可夫算法、决策树算法等。而深度学习生成式摘要方法是有Seq2Seq、PGN、GPT、BART、T5等模型。
Seq2Seq模型
生成类模型的基本建模思想是语言模型:

这是一个序列生成过程:每个time step(时间步)都在一个预先设定好的固定词库中选一个词。实际上,每个时间步都在做多分类,我们通过计算固定词表中的每个词在当前条件下出现的概率,来选出当前时间步下应该出现的词。传统seq2seq + attention语言模型存在的问题:
OOV问题:seq2seq模型的输出只能输出词汇表范围内的词,无法输出输入序列中OOV的词。生成不准确。
容易产生重复的内容
PGN模型
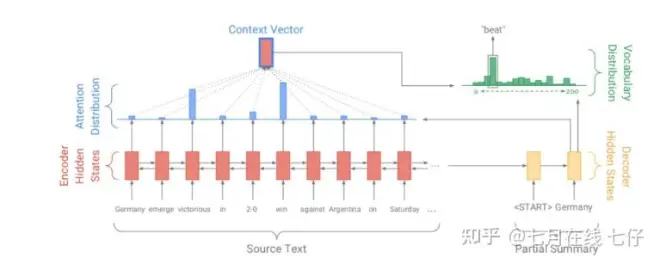
PGN模型既解决了文本生成过程中的OOV问题,又解决了文本生成过程中重复生成问题。一方面将Pointer Network与seq-to-seq中的encoder结合起来,使得生成的结果中既有seq-to-seq从全部词典中生成的,也有从源文本中复制过来的,既可以通过pointing直接从原文中复制单词又保留了通过generator生成新词的能力,同时也一定程度上解决OOV的问题,还使用coverage机制来追踪摘要的部分来避免容易重复的问题。PGN模型结构如下:

Baseline Seq2seq 部分
encoder:双向的LSTM,可以捕捉原文本的依赖关系及位置信息。decoder:单向的LSTM.训练的时候,decoder t 时刻的输入是target中 t - 1 时刻的词;测试的时候,decoder t 时刻的输入是 decoder t-1 时刻的输出。attention(类似于Luong attention)

h_i 表示的是encoder中第 i 个词的hidden_states_t 表示的是decoder中 t 时刻的hidden_state(其实是将decoder中lstm得到的hidden_state和cell_state拼接在一起)加权求和后得到 context vector

s_t 与 h_t * 拼接后过两层线性变换得到词表 P_vocab 的分布

Pointer network 部分
a_t 和 h_t * 在上一部分已经得到,p_gen 为【0,1】

如果source有重复的词,会将重复词的得分求和。
Coverage机制
将先前时间步的注意力权重加到一起得到所谓的覆盖向量 c_t,

如果之前该词出现过了,那么它的 c_t 就很大,为了减小loss,就需要 ai_t 很小,也就是说给attention之前生成词的信息,如果之前生成过这些词那么后续要抑制。
总结
文本摘要是NLP领域中一个非常重要的技术。通过将长篇文章或文本压缩为简短摘要,文本摘要技术可以帮助人们更快地理解文本内容,并快速获取重要信息。不同的文本摘要技术各有优缺点,可以根据具体需求和场景选择使用。在实际应用中,文本摘要技术有许多应用场景。例如,在新闻报道领域,可以使用文本摘要技术快速生成新闻摘要,使读者可以快速了解新闻内容;在市场调查领域,可以使用文本摘要技术对大量用户反馈进行快速分析,提取出关键信息,从而更好地了解市场需求;在医学领域,可以使用文本摘要技术从海量医学文献中快速找到相关研究成果,以帮助医生更好地做出诊疗决策。总的来说,随着NLP技术的不断发展和进步,文本摘要技术将会变得越来越普及和成熟。未来,它将在更多领域中得到应用,并为人们提供更加高效和准确的信息处理和分析手段。
想在NLP领域更系统、深入提升的同学,我建议你看下【NLP高级小班 第十一期】

第十一期,除了继续维持上一期的:
五大技术阶段:分别从NLP基础技能、深度学习在NLP中的应用、Seq2Seq文本生成、Transformer与预训练模型、模型优化等到新技术的使用,包括且不限于GPT、对抗训练、prompt小样本学习等
八大企业项目:包括机器翻译系统、文本摘要系统、知识图谱项目、聊天机器人系统,以及基本文本的问答系统、FAQ问答机器人、文本推荐系统、聊天机器人中的语义理解
标准流程:环境配置与特征工程、模型构建与迭代优化、模型评估与优化上线;
就业指导:就业部辅助BAT大咖讲师做简历指导、面试辅导、就业内推。
本期更对技术和项目阶段做了大力度改进:
对于技术阶段,新增文本检索系统中的关键技术以及22年年底爆火的ChatGPT原理解析
对于项目阶段,新增第五大企业级项目:短文本相关性语义搜索系统
面向群体: 本课程适合已经在做AI的进一步在职提升,比如在职上班族跳槽涨薪/升职加薪,采用严格筛选制(通过率不到1/3),需要具备一定的基础能力才能报名通过,故以下同学优先:
985或211高校的CS、数学理工科相关专业的应届或往届研究生
已有一定的AI在职开发经验,如AI岗想在职提升
已有一定的AI项目经验,如学过七月在线的机器学习集训营
【NLP高级小班 第十一期】已开营,放5个免费试听名额,有意找苏苏老师(VX:julyedukefu008 )或七月在线其他老师申请试听了解课程
看完本篇如果对你有用请三连,你的支持是我持续输出的动力,感谢,笔芯~
