
AI斋藤妮可露模型配布与经验分享
项目地址
so-vits-svc:https://github.com/innnky/so-vits-svc
SoVits-Gradio:https://github.com/NaruseMioShirakana/SoVits-Gradio

训练ai对电脑配置有一定的要求,请量力而行!!!
如果只是想体验一下请看前期准备和SoVits-Gradio,并到SoVits-Gradio(WebGUI)项目地址进行下载和使用。
如果想从头开始训练请看完本文,并到so-vits-svc项目地址进行下载与使用。
我把可能用到的软件放到百度网盘了
链接:https://pan.baidu.com/s/1R61NQnxkqMbJRYVRPp-_hw?pwd=if2g
提取码:if2g
前期准备
1.安装python,最好是3.10以下的版本,如3.9/3.8——https://www.python.org/
2.安装CUDA
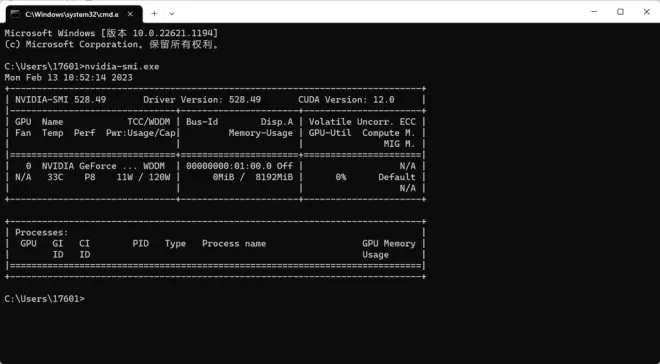
打开cmd,执行 nvidia-smi.exe 命令查看电脑的cuda版本(我的cuda版本为12.0,电脑系统是win11,如图1)
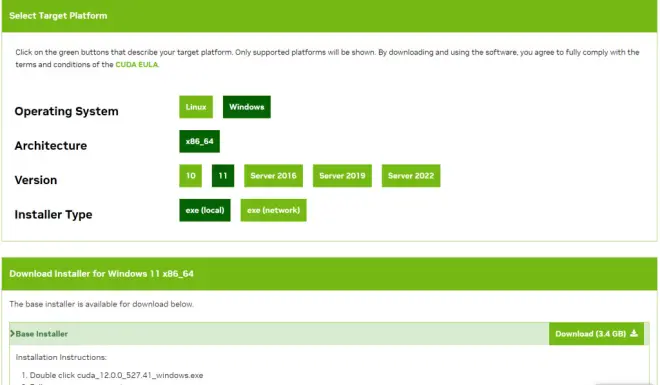
到nvidia官网搜索对应的cuda版本并进行下载——developer.nvidia.com(如图2,图3)
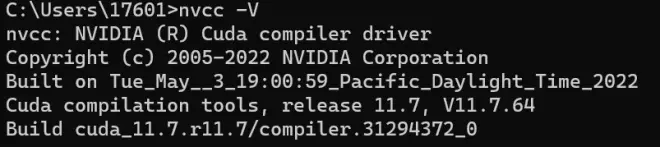
在cmd里执行 nvcc -V 命令查看是否安装成功,如图4(我这个是之前装的,所以是11.7)
3.安装代码编辑器,vscode或者pycharm都行
4.安装运行环境
下载项目后可以看见 requirements.txt 的文件,里面是运行所需要的第三方库,使用 pip install -r requirements.txt 来快速安装环境,但大概率会报错。因此我们采用手动输入的方式执行。。。
打开cmd,依次执行以下内容
5.安装Pytorch——pytorch.org
pytorch需要与cuda和版本对应,我这里按老版本的cuda11.7为例。可以直接在官网上选择对应的版本,复制下面的命令到cmd里安装,如图5
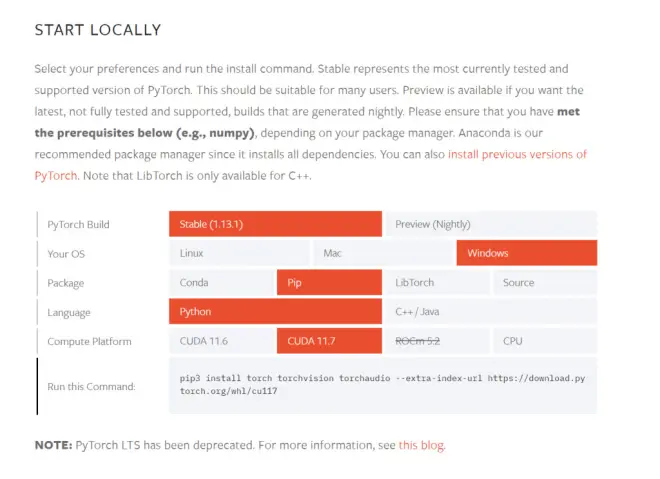
requirements中显示本项目需要:torch==1.10.0+cu113,torchaudio==0.10.0+cu113。其中113为cuda11.3版本,需替换成自己的。因为目前cuda12.0版本对应的pytorch还没出,装11.7就行。其他版本可到这个网站寻找——torch:https://download.pytorch.org/whl/torch/;torchaudio:https://download.pytorch.org/whl/torchaudio/
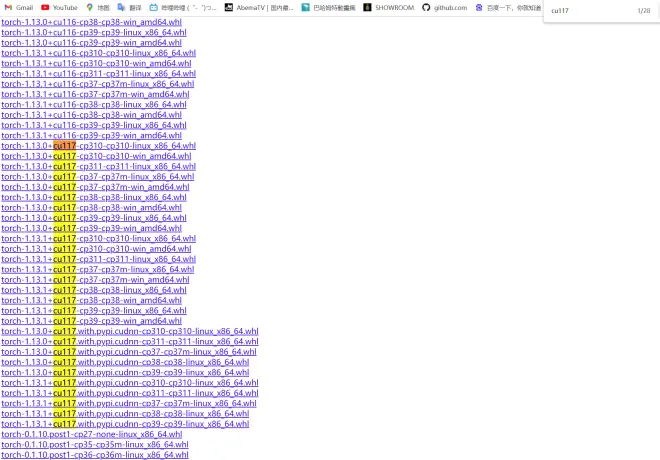
Ctrl+F搜索对应版本,torch和torchaudio都要按,cp310为python版本为3.10,如图6
打开下载的文件夹,右键——在终端中打开——执行 pip install .\torch-1.13.0+cu117-cp39-cp39-win_amd64.whl 安装torch——执行 pip install .\torchaudio-0.13.0+cu117-cp39-cp39-win_amd64.whl 安装torchaudio(橙色部分替换成自己下载的文件名称)
6.推荐装个ffmpeg
SoVits-Gradio
1.下载地址:https://github.com/NaruseMioShirakana/SoVits-Gradio/releases/tag/1.0.0
2.在网盘里下载模型:nicole.zip
3.将nicole文件夹放在 SoVits - Gradio\checkpoints 文件夹内
4.右键——在终端中打开——执行 python sovits_gradio.py
5.浏览器中打开 http://127.0.0.1:7860/
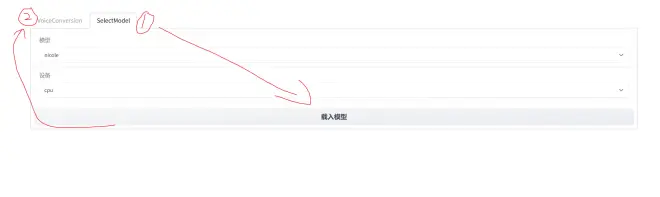
6.先点击 SelectModel 载入模型,再点击 VoiceConversion 进行音频转换。音频一定要是干声!关于干声处理可以往下看。
so-vits-svc
训练AI
一、准备素材
1.下载底模
hubert——https://github.com/bshall/hubert/releases/download/v0.1/hubert-soft-0d54a1f4.pt
G_0.pth——https://huggingface.co/innnky/sovits_pretrained/resolve/main/G_0.pth
D_0.pth——https://huggingface.co/innnky/sovits_pretrained/resolve/main/D_0.pth
将hubert放在 so-vits-svc-32k\hubert 文件夹内
将G_0.pth和D_0.pth放在 so-vits-svc-32k\logs\32k 文件夹内
2.准备训练素材
想训练哪个人物就去找对应的素材,最好是干声素材,即只有训练的那个人说话且没有背景音。音源的处理方法可往下翻。
3.切分音频素材
大部分声音素材都是很长的,我们要把他切分成6-10秒左右的wav格式的音频。
可以使用ffmpeg进行切分。D:\ai\voice.mp3 为文件路径;-segment_time 00:00:06 为切分成6秒的片段;D:\ai\voice%d.mp3 为输出路径,其中%d为输出整数,即自动命名为voice0,voice1,以此类推。
这里的voice最好替换成训练人的姓名,如xiaoai(即:D:\ai\xiaoai%d.mp3),这个名字就是之后要训练的模型的名字,在推理时要用到。
mp3转wav可以用格式工厂或者ffmpeg。
二、数据预处理
1.重采样至32khz
在 so-vits-svc-32k 文件夹内右键在终端中打开
执行 python resample.py
查看 \dataset\32k 文件夹内是否有wav格式的音频,有就是成功了
2.自动划分训练集 验证集 测试集 以及自动生成配置文件
执行 python preprocess_flist_config.py
3.生成hubert与f0
执行 python preprocess_hubert_f0.py
三、训练
用vscode打开so-vits-svc-32k项目(直接把文件夹拖进去就行)
执行 python train.py -c configs/config.json -m 32k 进行ai训练
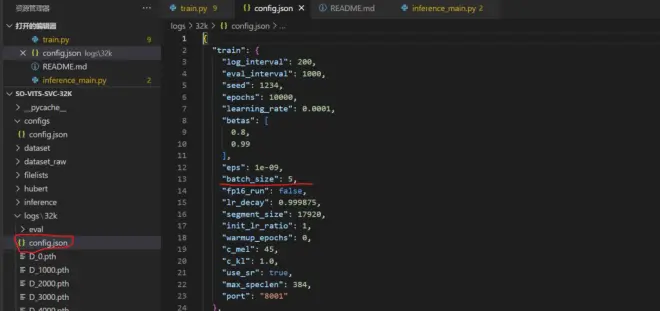
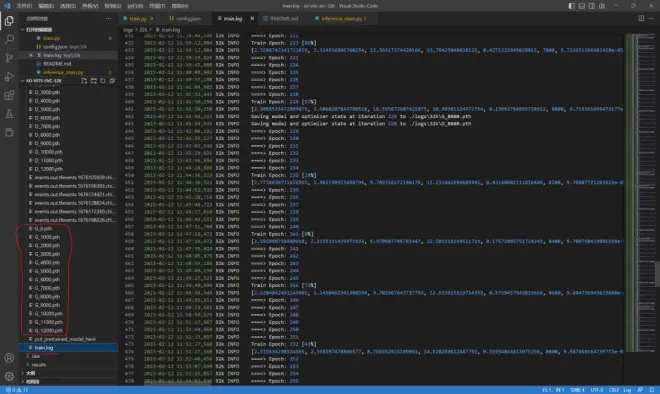
如果报CUDA out of memory的错,就是超显存了。此时需要适当修改batch_size的值。打开config.json,将batch_size改成小一点的数。我的是RTX 3070 Laptop,值是5,如图8。
出现epoch=1就是成功了。
四、小结
到这一步ai就正式跑起来了,日志可以查看\logs\32k\train.log,如图9。如果音源质量好,一般到G_6000左右ai的声音效果就很好了。
处理与推理音频
一、寻找与制作干声素材
1.以一首歌为例,先去网上找这首歌,下载
2.分离人声与伴奏
推荐软件:
①SpleeterGUI——https://makenweb.com/SpleeterGUI
有点:快速,配置要求低,有中文。
缺点:效果不是很好。
这个软件在运行时可能会报找不到文件的错,是因为缺模型文件。网盘里的2(4,5)stems就是,需解压后放到 SpleeterGUI\pretrained_models 文件夹内。
②Ultimate Vocal Remover——https://github.com/Anjok07/ultimatevocalremovergui
有点:效果好
缺点:对电脑配置要求高,无中文。
以上两款软件操作很简单,把文件拖进去就行。出现问题可自行百度解决。
二、开始推理
1.切分音频
如果直接把整首歌放进去转换可能会超显存,因此要对音频进行切分,分段替换。
推荐软件:
①Adobe Audition
②Audacity——https://www.audacityteam.org/download/
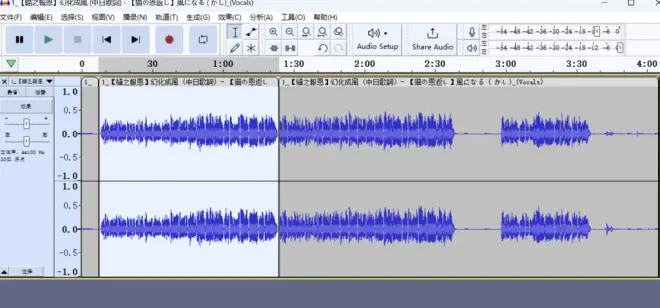
重点说一下Audacity,软件如图10所示。Ctrl+滚轮是放大缩小音轨显示范围,Shift+滚轮是左右移动。拖入音频,框住一段音频后右键——点击split clip切分音频。文件——导出——导出选择选择的音频可以将这段音频导出。切记要导出为wav格式!
2.推理
将上一步的音频放入 /raw 文件夹内
修改 inference_main.py 里的内容
执行 python ./inference_main.py
结果将在 /results 文件夹里呈现
3.小结
如果推理出来的音频效果不好有大致有两个原因,一是训练不够,我的模型训练到G_15000左右效果就已经很好了。二是干声处理不好。尤其是对音频的处理,拿翻唱歌曲为例,一定要找提取效果好的音乐进行人声分离,而且必须是一个人演唱的歌曲,最好没有混响,或者人声与伴奏音色相近。这些都会使分离出来的干声效果不好。相信我,你绝对不想听到一个可爱的美少女用烟酒嗓唱歌。。。
总结
十分感谢观看,我也是刚刚开始学习使用这些软件,难免会有纰漏出现,如果文中出现错误请大家指正批评!!!
