
关于使用 VITS对模型进行推理的时候自己的一点思考+搜寻模型并完成推理新手教程

起因是本人在下载了模型和配置文件(.pth和..json文件)后,使用CjangCjengh 大佬的moegoe GUI想直接进行推理。然后发现了一个问题,我下的明明是一个人的模型的啊,怎么说话人里那一栏都是其他角色没有我想要的呢?本文章以推理禅雅塔的模型为例,分析原因以及教你正确的姿势进行推理。在这里先感谢CjangCjengh、huggingface里的zomehwh等大佬提供的免费资源。
附图,可见有很多角色但是翻完都翻不到禅雅塔(我这里说明一下,我产生这个问题也是因为我在huggingface的这个空间里下的模型和config.json,才会出现这个问题,如果你也是下载的huggingface里排名第一空间里的模型,有小概率出现这个疑惑):

甚至为了这个问题我还到处到Google、github、bilibili去找类似的解决办法,都没有找到...于是我还提出过这个在各位大佬们看起来很蠢的问题“为什么我下的单人模型只能让他扮演原神里的音色,而且说话的声音很怪?”,当时获得的回答是“我没听懂你的问题..."
好了,多的废话不说了,总之最后我解决了这个问题并且知道了发生的原因。如果你跟我一样是一个这个领域的纯新手,目前已有的整合包不能满足你的对某些特定角色音色的需要,你也可以参考一下我的解释(不看问题也不大,如果你不会用现有的模型进行推理的话想直接推理可以转到我下面的教程):
---------------------------------------------------------------------------------------------------------------------
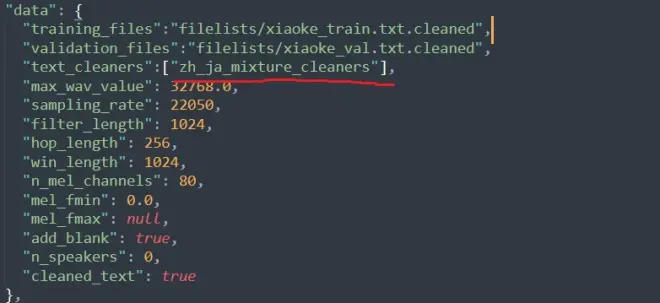
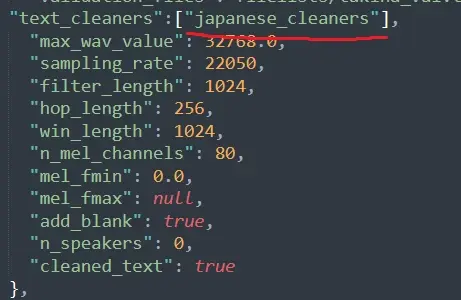
我解释一下这个问题发生的原因,原因出现在配置文件config.json上。这里面有一个叫n_speakers的东西,如果你下的模型里的config.json的这个n_speakers不为0,那么它多半是个多人模型,至于最下面的speakers没有特殊的意义,这是对每一个音色打的标签。
(附图)
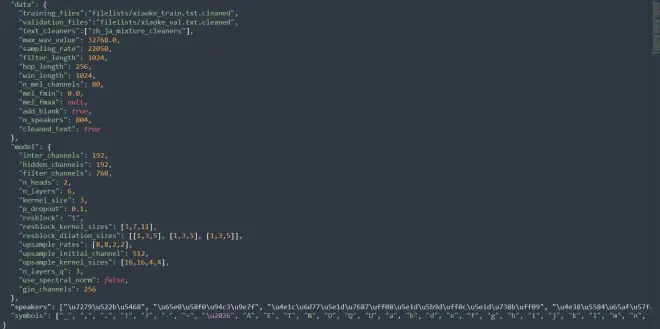
speakers里的'\u7279...'之类的是中文的编码,没有特殊的意义。
下面我解释一下它是怎么实现在一个模型中多音色的转变,也就是在你的说话人里面选择不同的角色出现了不一样的语调和语速之类的现象。多人模型中,通常会有一个叫speaker embedding的东西,这是一个嵌入向量,它被训练用于捕捉和模拟每个特定说话者的音色特征。这个嵌入向量在训练过程中被学习,并在合成语音时使用。当你选择一个特定的说话者作为输入时,模型会查找该说话者对应的嵌入向量,并用它来影响语音的生成,从而模拟该说话者的音色。
你变换标签(说话者姓名)实际上就是通过调整嵌入向量来模拟多种不同的音色,所以在多人模型中我们无需为每个说话者单独训练一个完整的模型。
里面的speakers顺序排列,和它对应的这个嵌入向量是一一对应的。所以你要是出现了和我一样的问题,你可以先检查n_speakers这里,那个speakers一般不是问题所在..(前面什么都不知道的情况下我还在这里卡了很久)
不过一般你在其他地方下的打包好的模型都会有配置文件整合在一起,很难出现这样的问题。我是因为在huggingface上下载模型然后和自己现有的config搞错乱了。。
---------------------------------------------------------------------------------------------------------------
以上就是原理的部分解释..BTW,如果你也有喜欢的角色,但是电脑配置不太支持训练自己的模型,建议你可以去Huggingface找一些大佬们的模型下载,和我一样的小白可以参考一下我这个浅浅的教程...
下面是用你已经下载好了的现有模型和配置文件进行推理(让你的模型说话)教程:
第一步,在space里找一个你喜欢的模型:

第二步,下载模型,下载config.json:

第三步,检查config是不是我们之前那个问题:

第四步,可以用moegoe进行推理了:
(moegoe下载地址:https://github.com/CjangCjengh/MoeGoe
这个界面是gui,需要搭配上面的moegoe.exe使用,更方便,建议安装在同一目录。下载地址:https://github.com/CjangCjengh/MoeGoe_GUI)

第五步,输入文本,推理,成功输出音频,成功截图就不演示了,到这一步基本也没有问题了:
到这里就全部结束了。当然,我也只是一个还在学习的纯小白,要是你和我碰到了这个一样的不可描述的问题,至少有了解决办法orz...
如果这篇文章对你有帮助的话,请给我留下一个赞,谢谢。再次感谢付出的大佬们。
