
1. 从头开始,把概率论、统计、信息论中零散的知识统一起来

- 事件与概率
1.0
可能性描述

2.0


3.0





密度就是概率空间里面一个点的权重值,质量就是一个线段或多个线段的权重值。密度与质量与实数空间中距离相区分
概率空间就是带权重的实数轴
边缘概率


由于是压缩,所以整体质量归一
条件概率


只是原来二维空间一部分,整体质量不归一,需要对权重进行等比放大

面对P的不同描述方式

概率论部分
博雷尔函数

用函数变换的方式可以发现不同随机变量之间的关联,准确的说是两个随机变量代表的概率空间之间的关系
例如

我们通过X轴的权重分配情况,可以确定Y轴的权重分配情况。
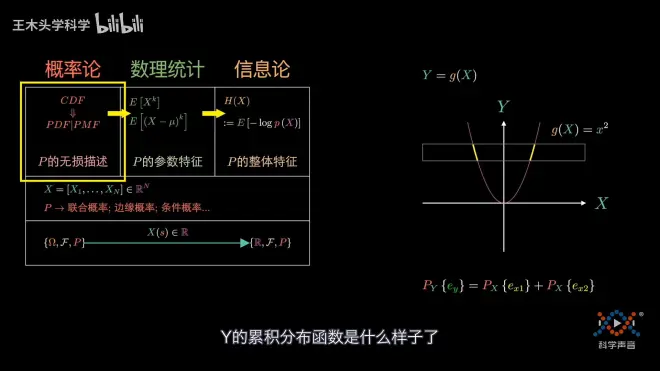
所以当我们知道了一个随机变量的P的信息,还知道了一个随机变量和另外一个随机变量的变换关系,也就知道了另一个随机变量对应的P的全部信息了。
例子


换元的本质,就是坐标变换,线性变换中,有旋转,图像的拉伸和压缩,拉伸和压缩对密度有影响
雅可比矩阵行列式, 就是在积分换元时对ds和ds’进行拉伸的比例调整,也就是一个坐标变换后面积的拉伸和压缩的比例,行列式有正负号,也就是方向,我们这里不考虑方向,所以求行列式的绝对值。雅可比矩阵就可看成从XY坐标系换成UV坐标系的操作,

X,Y独立,就得到了卷积公式,也就是X+Y=a的概率密度函数
数理统计部分

归纳分析包括两个问题:
1.如何归纳分析出现实问题属于哪个分布
2.如何归纳分析出具体的参数取值是多少

首先不是所有的随机变量都是有期望的,先假设它是有的 。

通过抽样样本构建出来,没有包含任何未知参数的新随机变量都称为统计量,统计量也是随机变量。统计学的一个重要工作就是通过统计量取评估样本遵循的概率分布

最大似然
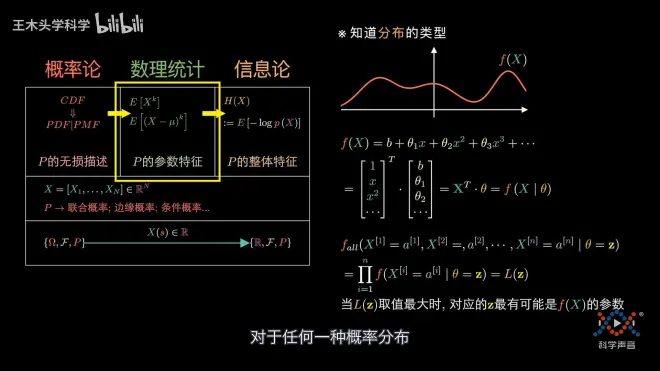

可以用多个我们熟悉的子概率分布去叠加而成复杂的概率分布。这里有个关键的概念是我们人为创造出来的随机变量H是用来拆解原来的概率分布的,可以认为是辅助线,因此H被称为隐变量。
信息论
离散情况下的熵称为信息熵,连续情况下的熵称为微分熵。
下面熵指信息熵

曲线的位置不同,E(X)的值也就不同。
H(X)中x被替换成log(x),那么就消除了x位置的影响。这样计算出来的熵,仅仅表示它的形状特征,而与位置特征没关系

log运算把随机变量之间通常的乘法运算转换成了加法运算,log的底的选取任意。




通过熵,我们就能对一个或多个随机变量的整体特征进行考虑和分析。
