
一文详解OpenCV中的CUDA模块
如果您使用OpenCV已有一段时间,那么您应该已经注意到,在大多数情况下,OpenCV都使用CPU,这并不总能保证您所需的性能。为了解决这个问题,OpenCV在2010年增加了一个新模块,该模块使用CUDA提供GPU加速。您可以在下面找到一个展示GPU模块优势的基准测试:
注1:文末附【CV】交流群
注2:整理不易,请点赞支持!
作者:天啦噜 | 来源:3D视觉工坊微信公众号
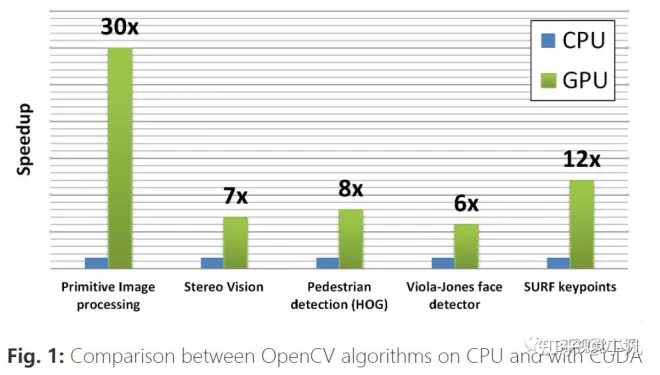
简单列举下本文要交代的几个事情:
概述已经支持CUDA的OpenCV模块。
看一下cv :: gpu :: GpuMat(CV2.cuda_GpuMat)。
了解如何在CPU和GPU之间传输数据。
了解如何利用多个GPU。
编写一个简单的演示(C ++和Python),以了解OpenCV提供的CUDA API接口并计算我们可以获得的性能提升。
一、支持的模块
据称,尽管并未涵盖所有库的功能,但该模块“仍在继续增长,并正在适应新的计算技术和GPU架构。”
让我们看一下CUDA加速的OpenCV的官方文档。在这里,我们可以看到已支持的模块:
Core part
Operations on Matrices
Background Segmentation
Video Encoding/Decoding
Feature Detection and Description
Image Filtering
Image Processing
Legacy support
Object Detection
Optical Flow
Stereo Correspondence
Image Warping
Device layer
二、GpuMat
为了将数据保留在GPU内存中,OpenCV引入了一个新的类cv :: gpu :: GpuMat(或Python中的CV2.cuda_GpuMat)作为主要数据容器。其界面类似于cv :: Mat(CV2.Mat),从而使向GPU模块的过渡尽可能平滑。值得一提的是,所有GPU函数都将GpuMat接收为输入和输出参数。通过这种在代码中链接了GPU算法的设计,您可以减少在CPU和GPU之间复制数据的开销。
三、CPU/GUP数据传递
要将数据从GpuMat传输到Mat,反之亦然,OpenCV提供了两个函数:
上传,将数据从主机内存复制到设备内存
下载,将数据从设备内存复制到主机内存。
以下是用C ++写的一个简单示例:
四、多个GPU的使用
默认情况下,每种OpenCV CUDA算法都使用单个GPU。如果需要利用多个GPU,则必须在GPU之间手动分配工作。要切换活动设备,请使用cv :: cuda :: setDevice(CV2.cuda.SetDevice)函数。
五、代码示例
OpenCV提供了有关如何使用C ++ API在GPU支持下与已实现的方法一起使用的示例。让我们在使用Farneback的算法进行密集光流计算的示例中,实现一个简单的演示,演示如何将CUDA加速的OpenCV与C ++一起使用。
我们首先来看一下如何使用CPU来完成此操作。然后,我们将使用GPU进行相同的操作。最后,我们将比较经过的时间以计算获得的加速比。
FPS计算
由于我们的主要目标是找出算法在不同设备上的运行速度,因此我们需要选择测量方法。在计算机视觉中,这样做的常用方法是计算每秒处理的帧数(FPS)。
CPU端
1.视频及其属性
我们将从视频捕获初始化开始,并获取其属性,例如帧频和帧数。这部分是CPU和GPU部分的通用部分:
2.读取第一帧
由于算法的特殊性,该算法使用两帧进行计算,因此我们需要先读取第一帧,然后再继续。还需要一些预处理,例如调整大小并转换为灰度:
3.读取并预处理其他帧
在循环读取其余帧之前,我们启动两个计时器:一个计时器将跟踪整个流程的工z作时间,第二个计时器–读取帧时间。由于Farneback的光流法适用于灰度帧,因此我们需要确保将灰度视频作为输入传递。这就是为什么我们首先对其进行预处理以将每帧从BGR格式转换为灰度的原因。另外,由于原始分辨率可能太大,因此我们将其调整为较小的尺寸,就像对第一帧所做的一样。我们再设置一个计时器来计算在预处理阶段花费的时间:
4.计算密集光流
我们使用称为calcOpticalFlowFarneback的方法来计算两帧之间的密集光流:
5.后处理
Farneback的“光流法“输出二维流矢量。我们将这些输出转换为极坐标,以通过色相获得流动的角度(方向),并通过HSV颜色表示的值获得流动的距离(幅度)。对于可视化,我们现在要做的就是将结果转换为BGR空间。之后,我们停止所有剩余的计时器以获取经过的时间:
6.可视化
我们将尺寸调整为960×540的原始帧可视化,并使用imshow函数显示结果:
这是一个示例“ boat.mp4”视频的内容:

7.时间和FPS计算
我们要做的就是计算流程中每一步花费的时间,并测量光流部分和整个流程的FPS:
GPU端
该算法在将其移至CUDA时保持不变,但在GPU使用方面存在一些差异。让我们再次遍历整个流程,看看有什么变化:
1.视频及其属性
此部分在CPU和GPU部分都是通用的,因此保持不变。
2.读取第一帧
注意,我们使用相同的CPU函数来读取和调整大小,但是将结果上传到cv :: cuda :: GpuMat(cuda_GpuMat)实例:
3.读取和预处理其它帧
4.计算密集光流
我们首先使用cv :: cuda :: FarnebackOpticalFlow :: create(CV2.cudaFarnebackOpticalFlow.create)创建cudaFarnebackOpticalFlow类的实例,然后调用cv :: cuda:FarnebackOpticalFlow :: calc(CV2.cuda_FarnebackOpticalFlow.calc)计算两个帧之间的光流,而不是使用cv :: calcOpticalFlowFarneback(CV2.calcOpticalFlowFarneback)函数调用。
5.后处理
对于后处理,我们使用与CPU端使用的功能相同的GPU变体:
可视化、时间和FPS计算与CPU端相同。
结果
现在,我们可以在示例视频中比较来自CPU和GPU版本的指标。
我们用于CPU的配置为:
Intel Core i7-8700
Configuration
- device : cpu
- video file : video/boat.mp4
Number of frames: 320
Elapsed time
- full pipeline : 37.355 seconds
- reading : 3.327 seconds
- pre-process : 0.027 seconds
- optical flow : 32.706 seconds
- post-process : 0.641 seconds
Default video FPS : 29.97
Optical flow FPS : 9.75356
Full pipeline FPS : 8.53969
用于GPU的配置为:
Nvidia GeForce GTX 1080 Ti
Configuration
- device : gpu
- video file : video/boat.mp4
Number of frames: 320
Elapsed time
- full pipeline : 8.665 seconds
- reading : 4.821 seconds
- pre-process : 0.035 seconds
- optical flow : 1.874 seconds
- post-process : 0.631 seconds
Default video FPS : 29.97
Optical flow FPS : 170.224
Full pipeline FPS : 36.8148
当我们使用CUDA加速时,这使光流计算的速度提高了约17倍!但是不幸的是,我们生活在现实世界中,并不是所有的流程阶段都可以加速。因此,对于整个流程,我们只能获得约4倍的加速。
总结
本文我们概述了GPU OpenCV模块并编写了一个简单的演示,以了解如何加速Farneback的Optical Flow算法。我们研究了OpenCV为该模块提供的API,您也可以重用该API来尝试使用CUDA加速OpenCV算法。
备注:作者也是我们「3D视觉从入门到精通」知识星球特邀嘉宾:一个超干货的3D视觉学习社区
本文仅做学术分享,如有侵权,请联系删文。
3D视觉工坊-CV交流群
已建立3D视觉工坊-CV微信交流群!想要进CV学习交流群的同学,可以直接加微信号:CV_LAB。加的时候备注一下:CV+学校+昵称,即可。然后就可以拉你进群了。
强烈推荐大家关注3D视觉工坊知乎账号和3D视觉工坊微信公众号,可以快速了解到最新优质的3D视觉与SLAM论文。
