
谷歌推出MobileDiffusion:0.2秒就可以在iphone文生图
"MobileDiffusion: Subsecond Text-to-Image Generation on Mobile Devices" 这篇论文介绍了一种新型的文本到图像扩散模型——MobileDiffusion。该模型通过在架构和采样技术上的大量优化,实现了在移动设备上生成高质量图像的高效性。它通过减少冗余、提高计算效率,并最小化模型参数数量,同时保持图像生成质量。
此外,通过蒸馏和扩散-GAN微调技术(之前我们提到的UFOGan),MobileDiffusion实现了8步和1步推理。实证研究表明,该技术在生成512x512像素图像时,能在移动设备上实现令人瞩目的亚秒级推理速度,树立了新的行业标准。

论文:https://arxiv.org/pdf/2311.16567.pdf
Readpaper:https://readpaper.com/paper/4827443622626459649
详细介绍
1 模型结构
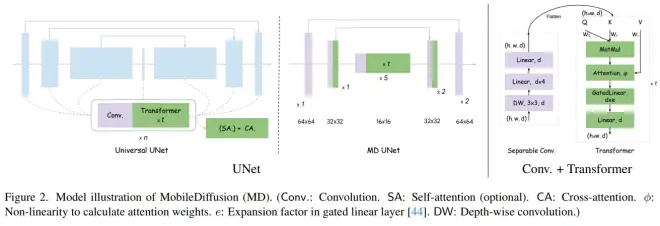
UNet是diffusion的主要结构,由Transformer block和convolution block组成。所以优化也是针对这两个主要模块进行。首先是降低他们的层数,然后让self-attention只在低分辨率的图片上计算,而cross-attention只保留一个在中间层。而且还提出可以用sperable convolution代替现在的卷积层。
在采样上,参考了目前最流行的两种加速方法:Progressive Distillation 和 UFOGen。
2 实验

量化评估如上图。首先,通过使用cfg-aware蒸馏和UFOGen微调技术,重点提高了样本效率,并展示了这些技术的数值结果。在评估中,通过调整cfg比例,DDIM和蒸馏模型实现了较低的FID分数。同时,为了公平比较,复制了SD的训练设置以匹配MD。在比较中,MD DDIM模型在体积和速度上均有显著提升,接近SD复制基线模型的性能。此外,蒸馏的8步模型和UFOGen微调的1步模型在FID分数上表现相当。最后,通过计算CLIP-ViT-g/14分数,进一步证明了这些方法在提高样本效率方面的有效性。

定性分析如上图。比较了 SD-XL、MD(一种模型)、经过不同步骤优化处理的 MD,以及微调后的 UFOGen。重点在于展示 MD 模型在多种采样器中能够产生高质量结果的能力,甚至能够与SD-XL这样的强基准模型相媲美。这一发现对于在设备端(如智能手机、嵌入式系统等)应用这类模型具有重要意义。
观点
学术上,它展示了通过架构和算法优化实现高效AI模型的可能性,把目前的几个有效的加速方法都整合在了一起看能不能一起加速,是一个很有益的尝试。
商业上,这种快速、高效的图像生成技术将极大地推动移动设备上的创意内容生产,为广告、社交媒体和游戏行业带来革命性的变化。此外,它还可能为低功耗设备上的实时图像处理开辟新的应用场景,如增强现实和虚拟现实。

特邀作者:日本早稻田大学计算机系博士生 王军杰
