
【深度学习】 CMU | 双语CC字幕 Deep Learning CMU 11
2023-07-14 11:25 作者:Blitzkrecg | 我要投稿

l1




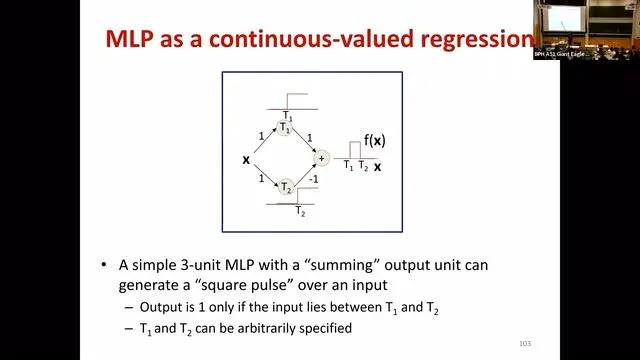
what can a network represent:
affine ax + by + c include linear ax + by


one hidden layer only approximated
L3


激活函数
threshold activation function vs
continuous activation - sigmoid


L4 重要 - 反向传播算法 Back Propagation
argmin_x -> min 时的x

梯度下降 gradient decent (找最小,x=x-L * sig_x_f(y)^T

局部最优 local optimum 当梯度=0
convex凸函数时 为 global 全局最优
分类问题
one-hot encoding 一种输出格式 + softmax 损失函数 loss function


multiclass 多类 - softmax - 用KL
Kullback-Leibler散度(分歧度)与相对熵
d,y 都是0或1时 kl_div(d,y) = 0
各为0和1,不同时= INF
但是斜率会在d y 相等时梯度下降时不为0
分别为1 和 -1



L5




当必须对向量求导,例如softmax


当无法求导的 RELU

argmax



L6 向量求导






L7





