
正则化由浅入深的进阶之路(粉丝投稿)
本文之前我假设你已经学习了关于线性回归、logistic回归和梯度下降的相关内容。
正则化(Regularization)方法是为解决过拟合(overfitting)问题,而向原始模型引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。本文将从过拟合问题引入,并通过在线性回归和logistic回归中进行正则化帮助理解思想。最后通过解读应用正则化思想的相关文献来贯通正则化的应用,此部分为选读内容。主要内容来自Andrew Ng的Coursera机器学习课程,符号记法也采用Andrew Ng的记法。
01 过拟合(overfitting)问题
以新型冠状肺炎发病人数y随时间x变化为例(Fig.1)。

Figure1.新型冠状肺炎患病人数的线性回归模型
图中选取了几个不同时间下的发病人数的样本点,时间轴开始时发病人数少,随着时间轴推进,发病人数极速增长在2月中下旬达到峰值,随后增长速率放缓。
(a)模型拟合了一阶线性函数,可以明显看出该模型没有很好地拟合训练数据,具有高偏差,我们称该问题为欠拟合(underfitting)。即该算法不顾数据的不符合,有很强的偏见地认为时间与患病人数时线性相关的,最终导致数据拟合效果很差。
(b)模型拟合了二阶多项式函数,效果不错。
(c)模型拟合了一个四阶多项式函数,该曲线绘制后全部通过每个数据点,看似很好的拟合训练数据 [注1],但曲线扭曲上下波动明显,具有高方差,所以这并不是一个很好的预测模型,我们称该问题为过拟合(overfitting)。即直观上来看,过拟合的算法虽然能集合几乎所有数据,但是拟合的假设函数(hypothesis)会太过庞大、变量太多。虽然该例子只有五项参数不够明显,但倘若我们每一个小时更新患病人数,为完全拟合数据,函数会有极多项,同时这也导致对该假设函数我们没有足够的数据进行训练,因为数据全用来拟合函数。
总结过拟合问题:拥有太多变量的训练好的假设模型会近乎完美地拟合训练集,但会难以泛化(generalize)[注2]新的样本。
[注1]:拟合得好是说该模型的代价函数(cost function)约为零,在线性回归模型中即为Tex parse error
[注2]:’泛化‘术语是指:一个假设模型(hypothesis)应用到新样本的能力。其中,在本例中新的样本是说没有出现在训练集的不同时间的患病人数。
事实上,新冠肺炎的发病人数变化并不仅仅与时间有关,更与在汉医护人员数量、口罩数量、消毒剂酒精的每日使用量、人员流动性程度等诸多变量有关,这也符合我们在实际中机器学习模型会拥有诸多特征变量(features),而不仅仅是单一变量。
但拥有太多变量,显而易见绘图会变得更加困难,因此通过数据的可视化来决定保留哪些特征变量会更为困难。正如我们之前所讲的,多特征变量、数据量不足会导致过拟合问题,为解决过拟合问题,我们有如下的几个思路:
1.减少特征变量(features)的数量
人工检查变量清单
模型选择算法(model selection algorithm)
该思路可以有效的减少过拟合现象的发生,但其缺点是舍弃了一部分变量,即舍弃了一部分关于问题的信息,如我们新冠肺炎的发病人数例子中,舍弃了口罩数量、消毒剂酒精的每日使用量、人员流动性程度等诸多变量,但所有的变量或多或少都对预测有用,实际上我们并不想丢失这些信息。
2.正则化(Regularization)方法
保留所有变量,但减少量级(magnitude)或参数(parameters)Θj的大小。
该思路相较于第一种方法,保留了所有对结果y有用的信息,对过拟合问题效果良好。
02 正则化(Regularization)
2.1 引入正则化思想
前面我们已经得到了解决过拟合问题采用减少量级或减少参数大小的正则化方法最为有效。那我们接下来继续讨论,正则化是怎么做到减少参数值的大小的呢?

我们再次回到最初关于新冠状肺炎的例子中,Fig 2.(b)模型的 二阶函数 [注2]与Fig 2.(c)模型的四阶函数[注3]相比,显然只要四阶函数的参数(parameters)Θ3、Θ4都非常小,两者函数就会相似。为了达到这个目的,我们惩罚(penalize)参数Θ3、Θ4使其变小,我们来看下该过程在线性规划中是如何实现的。

线性回归中,我们的优化目标是要最小化其均方误差代价函数(square error cost function)。在不进行惩罚时,优化目标的函数描述为:


其中,10000是我们随便选取的较大的数方便直观理解。此时,因为参数Θ3、Θ4都与10000相乘,为了最小化整体的函数,我们就需要使参数Θ3、Θ4尽量接近于0。而如果、都很小的话,我们的四阶函数假设模型就大致相当于二阶函数模型了,这就是我们正则化惩罚的思想。
但我们在实际中,比如新冠肺炎发病人数的例子,口罩数量、消毒剂酒精的每日使用量、人员流动性程度等诸多特征变量(features)都与预测结果有关,而每个特征变量在我们总体的衡量得失中所占有的比重我们并不能一开始就准确地知道,那我们要如何跟上述例子一样选择具体确切的变量Θ3、Θ4进行惩罚(penalize)呢?
因此实际问题上对每个变量权重并不准确了解,对此我们就采用将所有变量均缩小的办法。
回到上述例子中,我们就是要将所有参数(parameters)Θi均缩小,通过将代价函数(cost function)后加一个额外的正则化项实现,该项的作用是缩小每一个参数Θi的值,修改后如下:

其中,正则化项中的λ为正则化参数[注4],其作用是控制两个不同目标[注5]之间的取舍来避免出现过拟合的情况。

[注5]:两个不同的目标,第一个目标是指前面项的累加,是为更好地拟合数据和训练集;第二个目标是指我们要尽可能地是参数值小,这与目标函数的第二项即正则化项有关 。
在新冠肺炎的例子中,如果我们采用上述正则化后的代价函数J(Θ),那我们拟合的曲线虽然不会如二阶函数般契合,但是一定比四阶函数模型曲线更加平滑更加简单。
2.2 从线性回归说起正则化
通过前一小节的引入,我们已经介绍了正则化后的线性回归模型的代价函数和优化目标分别为:

接下来我们将分别介绍两种求解线性回归模型算法(梯度下降算法和正规方程法)的正则化形式。
在不加入正则化的时候,我们使用了梯度下降(gradient descent)进行常规的线性回归,算法如下:

我们可以注意到算法中标红出处,我们是将j=0的情况单独拿了出来进行迭代更新(update),为什么要这么做呢?
不知道大家有没有注意,我们前面正则化对参数进行的惩罚对象是从参数Θ1开始的,并不包含参数Θ0!!!我们从参数Θ1开始加入正则化项后,算法修改如下:

我们假设了大家已经阅读了本系列文章关于梯度下降的内容,我这里就不具体用微积分展开证明:算法中方括号部分就是J(Θ)对Θj的偏导数,要注意J(Θ)是我们正则化后的包含正则化项的函数。
梯度下降算法中对于变量Θ从1到n的更新(update),去掉中括号后更新式变为如下:

该变式的第二项,实际上与我们未进行正则化的梯度下降更新项是一样。
我们来看下线性回归模型求解的第二种算法:正规方程法(normal equation)的正则化形式。
该方法原有形式为:

即经过最小化代价函数,我们可以得到:

如果我们使用正则化,那该式需要增加一个矩阵,修改后如下:

该式中的矩阵为n+1·n+1阶的矩阵,n表示特征变量的数量。进行正则化后还有一个好处是,即使样本总量小于特征变量数,也不需要担心该修改后的式子是不可逆(non-invertible)[注6]的。
[注6]:不可逆问题是线性代数关于逆矩阵方面的基本问题,请自行参考线代知识。这里需要提及的一点是:即使是未进行正则化的式子存在不可逆的可能,但我们在使用matlab进行计算时,采用的pinv函数会直接求伪逆。
2.3 从logistic回归续谈正则化
logistic回归章的讲解在大家已经阅读完线性回归内容后,很多内容会不再进行赘述,主要通过代码实现让大家理解更深刻。
回归的代价函数为解决过拟合现象,在添加正则化项以达到惩罚参数的目的后,代价函数变为如下形式:

与线性回归的正则化类似,该正则化项的作用是减小参数。
logistic回归的梯度下降算法形式上与线性回归相似,其区别在于假设模型(hypothesis) 是不一样的,logistics回归的假设模型为:

但梯度下降算法的形式与线性回归一致:

我们在本章更为关注如何实现正则化后的logistic回归模型,并且我们会通过学习率的取值分别展现出过拟合(overfitting)、欠拟合(underfitting)和正则化(regularize)后的情况。
首先,我们建立一个命名为costFunction的函数,该函数需要返回两个值,第一个值是计算代价函数的J(Θ)值,第二个需要返回值是梯度(gradient),即分别对于每个i值的梯度我们进行求导:

我们建立的costfunction函数返回的两个值需要返回到我们的主函数中,主函数要做的主要功能是将costfunction最小化。
另外为了清晰地绘制简单明了的图像方便大家理解,编写了函数mapfeature来将数据绘制在图中;函数plotDecisonBoundary绘制决策边界(DecisonBoundary);函数sigmoid表示假设模型(hypothesis);这些简易函数与本章无关就不尽兴一一赘述,具体可参考Github中吴恩达的作业。
我们可以得到在学习率λ为1的情况下我们正则化后的决策边界较为理想,如Fig.3所示。

那如果我们的学习率λ为0和100情况分别会怎么样呢?

我们可以看到Fig .4的处理相当于没有正则化处理的logistic回归模型,即具有过拟合问题。近乎很好的拟合所有数据,但带来的问题是边界曲线显然扭曲,上下波动明显,具有高方差。
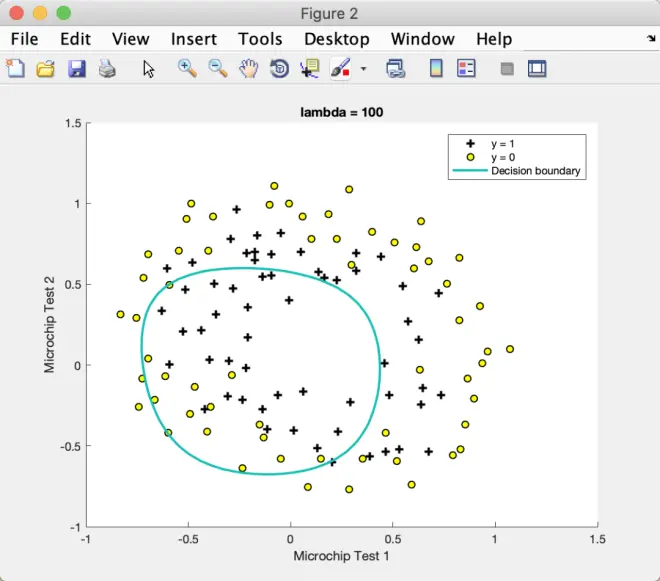
Fig .5的处理情况,就是我们的欠拟合现象,即具有高偏差,与数据集是显然不符合的。
03 正则化的应用之路
我们以一篇文献EEG-Based Emotion Recognition Using Regularized Graph Neural Networks(基于正则化图神经网络的脑电情绪识别)来应用正则化的思想。
我们只关注其中的正则化内容,略掉其余的不同领域的背景相关知识,包括关于作者利用脑电图信号的拓扑结构建立稀疏邻接矩阵,以及简单图卷积网络(graph convolution network)和对无向连接图采用切比雪夫多项式(Chebyshev polynomials)来代替卷积核的图傅里叶变换进行滤波 。
对相关知识感兴趣可以参考文献和一篇该方向研究生的论文解读,本部分主要基于两者。
参考文献:
https://arxiv.org/pdf/1907.07835.pdf
研究生的论文解读:
https://mp.weixin.qq.com/s/R0B3gE1X69D1HYOcmZgtPA


RGNN整体框架
FC表示全链接的图层(fully-connected layer),CE表示交叉熵损失(cross-entropy loss),GRL是节点域对抗训练中采用的梯度反转层(GRL)具体后述会展开,KL表示Kullback-Leibler散度是我们情感分布学习中的模型函数。
该整体框架表述的思想简而言之,就是对训练数据集(Training Samples)一方面采用分布学习计算损失函数,另一方面,训练数据集和训练测试集(Texting Samples)共同经过领域分类器即NodeDAT采用梯度反转层(GRL)计算可得其主损失函数和相关的分类标签。
其伪代码如下:

上面的伪代码有没有熟悉的感觉?对于变量的更新(update)与我们线性回归模型的梯度下降算法是不是很相似!梯度下降算法中的方括号部分内容正是对代价函数的求导,我们下面附上梯度下降算法在线性回归中的形式以供对比参考:

我们可以看到还是RGNN的实现只不过在一般梯度下降算法中采用了结合两个代价函数的方法,即对13、14步中对W和A的更新是混合节点域对抗训练(NodeDAT)和基于情绪感知的分布学习(EmotionDL)的损失函数的梯度,β表示节点域对抗训练中域分离器所使用梯度反转层(GRL)[注7]的比例因子。
[注 7]:梯度反转层是指在反向传播期间反转域分类器的梯度。
节点域对抗训练就是一个域分类器。
下面我们分别介绍节点域对抗训练(NodeDAT)和基于情绪感知的分布学习(EmotionDL)。对于域分类器我们只写出其损失函数,不具体展开推导以及详细优势和实现过程,选择展开讲解情绪感知的分布学习。
领域分类器的目标是最小化以下两个二进制交叉熵损失的总和:

在SEED与SEED-IV脑电图数据集上,分别可以划分为三类和四类情绪。SEED有积极、中性和消极三类情绪,并有相应的类指标分别是 0 1 2,将每个训练样本标签


注8: KL散度(Kullback-Leibler Divergence)是一个用来衡量两个概率分布的相似性的一个度量指标。
一般来说,我们无法获取数据的总体,我们只能拿到数据的部分样本,根据数据的部分样本,我们会对数据的整体做一个近似的估计,而数据整体本身有一个真实的分布(我们可能永远无法知道),那么近似估计的概率分布和数据整体真实的概率分布的相似度,或者说差异程度,可以用 KL 散度来表示。
具体可以参考关于KL散度的CSDN博客:
https://links.jianshu.com/go?to=https%3A%2F%2Fblog.csdn.net%2Fmatrix_space%2Farticle%2Fdetails%2F80550561
已获作者或跃在渊_NUE授权
原文链接:https://www.jianshu.com/p/f275072a6927
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
