
CMU 15-445/645-笔记-18-时间戳顺序并发控制

> 这期依然没有 Andy,悲
## 并发控制方案

两阶段锁是一种机制,数据库可以通过它在运行时生成 Serializable Schedule,它依靠锁才能做到这些
但是今天要讨论的是一些不依靠锁的协议(就靠时间戳来实现)
两阶段锁其实就是个悲观锁方案,它假设数据库中执行的事务里面存在着大量的争抢情况
而基于时间戳顺序的方案则是个乐观锁方案,因为它可以允许数据库在不获取锁的情况下对数据进行读和写。然后正确地调整出正确的 Serializable Schedule
## T/O 并发控制

数据库可以基于时间戳这种机制来对时间戳进行分配,以此来预定义这些事务的提交顺序
数据库要保证的是,如果事务 Ti 小于事务 Tj 的时间戳,那么在 Serializable Schedule 中,Ti 会在 Tj 之前执行
那么如何做到呢
## 时间戳分配

这些时间戳其实就是唯一并且有固定长度的数字
时间戳有几个特征
1. 必须单调增加(时间戳的值必须随着时间的流逝而增加)
2. 值是唯一的(永远不能拥有两个具备相同时间戳的事务)
事务执行时,数据库会将这些时间戳分配给事务
需要注意的是,时间戳不一定要和 clock time (CPU 的挂钟时间)有所对应,因为可以在事务执行时的任意时间点给事务分配时间戳
如果是分布式数据库,如果使用挂钟时间,那么很难保证时间同步(因为有很多机器)
在同步时间时,时间轴可能会回调(tiao)
使用系统时钟(System Clock),就会遇到夏令时和冬令时导致的时间调整。比如到了夏令时,时间会往回调整一个小时,那么现在这个所谓的时间就不是单调增加的了,因为它往回调了
逻辑计数器是这样的概念,假设在 CPU 中有一个专门用来保存时间的寄存器,它里面的值是单调增加的,而这些值的长度是 32 Bit 或者 64 Bit
逻辑计数器依然不适合分布式,而且假如你的长度是 32 Bit,如果计数超过 32 Bit,那么到那个时候,计数器也会往回走
最后一种就是 Hybrid 方案,它回让时间戳和物理计数器以及逻辑计数器进行匹配,以此确定所有东西都是正常工作的
## 课程目标

## 基础 T/O

基于时间戳顺序方案的基本思想是,在不获取锁的情况下,要让系统中的事务能够对数据中的对象进行读写操作
怎么做呢,这个就需要往数据库对象中添加一些额外的元数据,特别是,要往数据库系统中每个 tuple 上都要添加两个时间戳
- read timestamp
表示最近读取该对象的事务的时间戳
- write timestamp
表示是该系统中最近对该 tuple 进行写入操作的那个事务的时间戳
当事务执行时,它要确保它可以利用与该 tuple 相关的时间戳来读取这个 tuple
### 基础 T/O Reads

在从数据库系统中读取一个值之前,要确保它是一个不变量
要确保这个事务 Ti 中这个时间戳不小于该系统中这个 tuple 所对应的 write timestamp
也就是说,要确保该系统中没用其他事务对该 tuple 进行写入操作
也就确保了,这个事务不会读取到未来另一个事务在这个数据库中覆写的值
如果这个不变量失效了,就要把这个对应事务中止掉
要更新时间戳,就必须在 read timestamp 和自己的时间戳中选出那个最新的时间戳来进行更新
一旦时间戳得到更新,就必须将该 tuple 的副本保存到一个本地私有工作空间中去(只对你可见),这样才可以确保做到可重复读
> TODO: 这里没怎么懂,后面再看一遍
当另一个事务进来并对系统中的数据进行更新操作时,这种情况下必须能读取到你最初读取的值,但如果你允许另一个事务去更新这里的值,那么就要无效化之前提到的那个不变量,就不能读取到这个值,但实际上应该能够读取到这个值,因为在这个事务中读取到的是一个不一致状态
### 基础 T/O Writes

如果事务的时间戳小于写入的那个对象所携带的 read timestamp,这意味着这是一个新的事务,并且会读取到一个过时的值,这个值就不应该存在,这就违反了时间戳顺序协议
如果事务的时间戳小于另一个对象所携带的 write timestamp,那么一个新事务会覆盖掉这个值,这种情况也违反了协议
如果不是上述两种情况,那么就是一个有效的写操作,就需要去更新该 tuple 的 write timestamp,所以这里也必须要制作一个本地副本,用来支持可重复读(这样就可以从副本读而没必要去数据库读了)
### 例子 1
R-TS(Read TimeStamp)
W-TS(Write TimeStamp)

T1 事务执行 R(B),此时得到的时间戳 1 > 0,于是将 B 的 read timestamp 值更新为 1

现在切换到 T2,执行 R(B),然后可以对它的 read timestamp 进行更新,取当前 read timestamp 和新时间戳这两者间的最大值作为它的新 read timestamp,就是 2

然后执行 W(B),通过查看 B 的 write timestamp,发现真实的时间戳要大于它,所以要将 B 的 write timestamp 更新为 2

然后切回 T1,T1 执行 R(A),它去查看 A 的 write timestamp(这里为啥是 write 不是 read?),发现 1 > 0,所以就更新对应的 A 的 read timestamp 为 1

然后切回到 T2,执行 R(A),此时看 A 的 write timestamp,2 > 0,将 A 的 read timestamp 更新为 2

最后,T2 执行 W(A),它去查看 A 的 read 和 write timestamp,此时的时间戳要比这两个时间戳都要来的大,即 2

所以此时就不存在违反协议的情况
### 例子 2

T1 执行 R(A),那么 T1 会去更新 read timestamp

接着切换到 T2,执行 W(A),它会检查 A 的 read timestamp 和 write timestamp,此时有效,然后它会将 A 的 write timestamp 更新为 2

然后再切换回 T1,此时执行 W(A),它会检查 A 的 read timestamp 和 write timestamp,此时无效,因为 A 的 read timestamp 是 1,而这个 1 小于 A 的 write timestamp 的 2,这就造成了一个协议违反,所以 T1 不能进行提交,需要对它进行中止

那么这里可不可以优化呢
可以的,因为每个事务会为它所操作的 tuple 制作一份本地副本,本质上来讲,这个 T1 的 W(A) 就可以被系统所忽略了。尽管在事务内部,T1 依然需要这个写操作,因为需要能够读取到这个写操作所做的修改
## 托马斯写入规则

基本思路是,如果试着对对象 X 进行写入操作,如果当前时间戳小于该对象的 read timestamp,则依然需要中止该事务,并开启一个携带新时间戳的事务
但如果该时间戳小于该对象的 write timestamp,这意味着有一个比较新的事务已经修改过该对象了,实际上就可以忽略掉这个写操作
此时可以读取这个对象的本地存储副本
从外界来看,将这个写操作忽略掉是 OK 的
在特定场景下,这种优化是有用的,这会允许数据库去提交这种 Schedule
例子
T1 执行 R(A),并更新它的时间戳

T2 执行 W(A)

切回到 T1,执行 W(A),此时 T1 执行的这个写操作应该是无效的

此时就不用去更新 A 的 write timestamp 或者对应的值,但会维护一份本地副本,忽略掉这个问题,并让 T1 继续执行
对于 T1 中所有对于 A 接下来的进行读操作时读取到的值,都是本地副本中的这个值
## 基础 T/O

和两阶段锁类似,只要不使用托马斯写入规则,数据库可以通过这种机制生成 Conflict Serializable Schedule
通过使用这种方法可以防止死锁问题
对于在数据库中执行的每个操作来说,要确保这是一个有效的操作,就要逐步生成这种 Serialization Graph,一旦检测到有环存在,就在两阶段锁中让这个事务无效,并中止该事务
而基于这些时间戳,那么就要逐步检查每个操作是否有效,然后尽早中止它们
对于 Starvation 的情况,假设有一个已经运行了很长一段时间的事务,然后还有一些执行时间很短的事务,这些短事务只是对一些 tuple 进行更新,然后提交事务,就结束了。本质上来讲,它们会让那些引起冲突和连环中止的老事务无效化
时间戳顺序协议规定了 Schedule 是不可恢复的
那么什么是可恢复的 Schedule?
## 可恢复的 Schedule

一个事务只有当它所依赖数据的对应的事务都已经提交的情况下,它再进行提交,这样的 Schedule 是可恢复的
例子

T1 执行 W(A),T2 执行 R(A),接着执行了 W(B)

在这种 Serial Order 情况下,T1 先执行,然后 T2 再执行,那么 T2 中的这个读操作是可以读取到 T1 中的这个写操作修改过的值
然后 T2 又执行了 W(B),进行提交

假设过了一段时间后, T1 被中止了。然而此时对于外界来说,T2 已经被提交了,但它读取到了一个来自已经被中止的事务(T1)中的值,实际上这是无效的,这不是一个可恢复的 Schedule
那么也就不应该将 T2 中的写操作落地
虽然这个 Schedule 不可恢复,但对于 basic timestamp ordering 并发协议来说,这种情况是允许发生的
## Basic T/O 的性能问题

basic timestamp ordering 协议的开销很大,因为每当要执行读写操作时,都需要将数据复制到本地工作空间中
在执行长时间运行的事务时,会遇上 starvation 的情况,那些执行时间不长的事务会快速更新 1 个或者 2 个 tuple,而这会让那些执行时间很长的事务被中止并重启
## 一个观察

在两阶段锁中,只要对数据库中的值进行读写,那么就必须获取某个 Lock,以防止数据库系统中其他事务跑过来影响
而 timestamp ordering 协议也是这样,每当要对某个 tuple 进行读写时,必须确保时间戳与要执行的那个操作对齐
而这两种方案都假设系统中存在大量争抢锁的场景,并试着阻止那些错误的事情发生
那么假设系统中没有这么多争抢锁的场景会怎么样呢?
假设这些事务的存活周期很短,并且彼此之间没有冲突,该怎么优化?
## 乐观并发控制

即以乐观的角度来看待系统中事务执行的方式
(由 CMU 的 HT Kung 发明)
思路是,在基本的 timestamp ordering 协议中,每次要执行一个操作时,首先要将要操作的那个数据的副本放入一个线程私有的工作空间中。每当要从数据库读取某个元素时,先去制作该元素所在的数据的副本,然后再对它进行操作
要更新的话,将它的副本放入本地工作空间中,然后对这个本地副本进行更新(这个更新不是在数据库中的)
一旦所有工作完成,准备提交事务时,要去验证所有修改与数据库系统中并发执行的其他事务是相一致的
验证完成,将在私有工作空间中所做的所有修改,都落地到全局数据库空间中
## OCC 阶段

OCC 的作用是用来验证该事务是否依然有效,并且不与其他的产生冲突
当 validation 阶段结束时,就必须要将在私有工作空间所做的修改落地到主数据库中
write 阶段,以原子的方式将所有修改落地到主数据库中
例子

开始执行 T1,此时它构建了一个私有工作空间
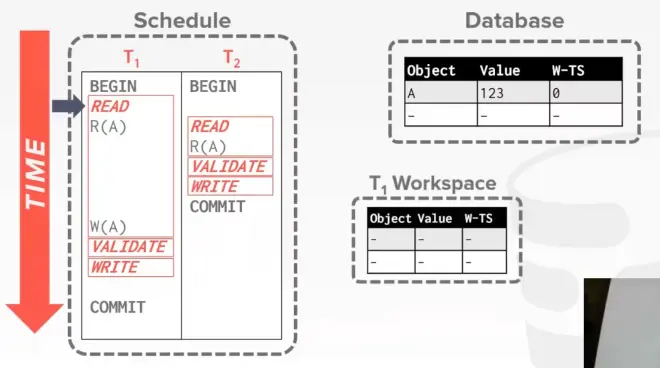
然后将 A 的副本放入它的私有工作空间中,该副本携带着它从数据库系统中所读取到的 write timestamp
接着执行 T2,此时它也构建了一个私有工作空间

T2 会在它的私有工作空间中执行 R(A),A 会携带着它的 write timestamp
然后 T2 进入 validation 阶段,此时它所拿到的时间戳是 1

目前来说因为 T2 是一个只读事务,它不需要做任何验证方面的事情
然后 T2 进入 write 阶段,由于没什么东西可写,直接提交

现在切换回 T1,T1 要执行 W(A),那么此时 T1 要对它的本地副本进行修改,它的 write timestamp 就被设置成 ∞
(只有当个事务进行 validation 阶段时,才会被分配一个时间戳,而这里 T1 此时没有 validation 阶段,所以就没有时间戳)

T1 进入 validation 阶段,此时它拿到的时间戳是 2,若此时系统中没有其他并发执行的事务,那么 T1 的 validation 阶段就算完成了

T1 的 write 阶段,需要将其操作的 tuple 的 write timestamp 更新为它开始进行验证时所分配的 timestamp(也就是 2)
### OCC-验证阶段

数据库要确保它所生成的 Schedule 是 Serializable/Conflict Serializable 的,对于每个事务来说,需要去确保这些被修改的东西不存在任何冲突,并且不会与系统中所有其他并发执行的事务产生读写/写写冲突

拿到一个时间戳后,用这个时间戳去查看系统中所有其他并发之心的事务,确保 read set 和 write set 不会相交,确保有一个正确的 Serial Order

当准备验证时,调用 commit,那么数据库就会执行 validation 阶段,因为它能看到数据库系统中所有的事务,所以它要确保这个要提交的事务和其他事务有没有冲突
有 2 种验证技术: backward 和 forward

backward validation
指的是,当某个事务准备提交时,数据库系统就会去查看该系统中所有较老的事务

以 T2 为基准,找到所有比 T2 的时间戳还要小的的事务,并对它们进行验证操作

画红圈的是 T2 的 backward scope,T1 比 T2 老
有可能会遇到这种情况,数据库系统从主数据库中读取到了某个新数据,但这个数据在执行 T1 的时候就已经读过了,因为 T1 修改的是它自己空间中的那个副本,如果发生了这种情况,就需要中止 T1
forward validation


找到所有并发执行但还没有提交的那些事务,对它们进行验证操作
假如 T2 对它本地私有空间中的数据进行了更新,在 Serial Order 中,它在 T3 之前执行,但它已经从数据库中读到了一个过时的值,如果发生这种情况,就必须中止该事务
所有事务在执行验证的时候都是沿着同一方向进行的(要么向前,要么向后)
### OCC-验证步骤-1

例子

在 T2 执行任何操作之前,T1 就完成了它的所有步骤
### OCC-验证步骤-2

如果 Tj 在开始执行它的写阶段前,Ti 就完成了它的工作,那就需要确保,在这种情况下,事务中写操作要处理的东西不会与其他事务的读操作要涉及的东西相冲突
即其他事务不会去读取这个事务要写入的东西
例子

如上图所示

T1 在执行验证操作时,需要中止 T1,因为它是 read set,它的时间戳要比 T2 小,因为 T1 先开始执行验证操作,T1 的 write set 与 T2 的 read set 冲突了。所以这就违反了之前拥有的不变量,就需要中止 T1
那假如 T2 在 T1 之前先执行验证操作呢?

T2 执行 R(A),接着开始验证,这里它并没有 write set,也就没有任何和 T1 这个事务冲突的部分
T1 也做了相同的事情

T1 的 write set 不与其他并发事务中的操作冲突
### OCC-验证步骤-3

要确保 Tj 开始它的读阶段之前,Ti 完成了它的读阶段
要确保该事务中的 write set 不与其他事务的 read set 和 write set 冲突,或者不与其读阶段重叠
例子

T1 执行 R(A) 和 W(A),T2 执行 R(B)

然后 T1 执行它的验证阶段,它拿到的时间戳是 1
此时 T1 可以进行提交,因为 T1 中的 write set 此时并没有与 T2 中的 read set 冲突

更新 A 的 Value 为 456,并将它的 write timestamp 设置为 1
切换回 T2,T2 执行 R(A),现在它去主数据库那边,读取到由 T1 更新过的 A 的值,并将它写入本地副本

验证后数据可以成功写入,因为这里没有任何其他的并发事务
### OCC-序列验证

数据库保证事务是真正 Serializable 的方式是,用一种全局视野,能够看到系统中所有正在运行的活跃事务,那么也就能看到每个事务在系统中所做的所有修改,那么也就可以通过用这种机制来决定系统中事务的执行顺序
在整个系统中,在 validation 阶段会有一个很大的 latch,它用来确保一次只有一个事务在执行验证操作
### OCC-读阶段

当试着要对某个值进行读写时,要去制作对应的副本,并且只对本地副本进行更新,确保支持可重复读
### OCC 观察

当没有什么冲突的情况下,乐观并发协议中这些基于时间戳的协议的效果非常好,因为这允许在不获取 Lock 以及不做那些代价很高的操作的情况下,去处理事务
然后做一些(半)轻量级的验证来确保事务有效
### OCC 性能问题

开销就是,要维护进行读写操作的那些对象的本地副本
验证阶段和写阶段会按照顺序执行,一次只会有一个事务进行验证,所以这个就成为了一个巨大的瓶颈

当一个事务要提交时,从逻辑上来将,即便这些事务彼此不会重叠,依然必须要维护要访问的对应数据结构的物理正确性
加 latch 的情况下,尽管冲突率低,但只要并发一大,这个依然会慢
因为即便在逻辑上 read set 和 write set 不相交,但它们依然存在争抢问题,比如并发验证,可能同时会有多个线程查看同一事务中的本地副本中的数据,这个就需要 latch
那么假如,对整个数据库进行分区会怎么样呢?
一个事务所有的工作都只在一个分区上,那么就可以移除掉这个事务上所有的 lock/latch,这种做法可行吗?
可行
## 基于分区的 T/O

事实上,它就叫做,Partition-Based Timestamp Ordering
将数据库拆分为水平分区,然后通过时间戳来对该分区所涉及的事务进行排序,让它们以 Serial Order 的顺序执行
如果事务都是按照顺序执行,那么在一个数据库中,也不需要用 lock/latch 了,因为此时不存在并发
例子

上图中的 Schema,有 3 个表,Customer 表、Orders 表、Oitems(某个 order 涉及的 item) 表

通过使用这种外键引用结构,可以将一些客户信息、这些客户对应的订单信息、订单中涉及的商品信息都保存在一个分区中

想象一下,将 c_id 1 ~ 1000 的客户信息放入一个数据库中,将 c_id 10001 到 2000 的客户信息放入另一个数据库中
假设此时要去更新某个客户的信息、订单信息之类的

某个客户落在这个分区,那么这个事务就会在这个分区上进行操作,它能安全的做到这些,因为所有的事务都会放在一个队列中,这个队列是用一个单线程去执行的
想象一下,如果能将数据库分区的粒度分的更细,那么在执行事务时,所能获得的并行性就越高,这样每个事务执行的速度就会变得更快,因为此时不用去获取 lock/latch 了
当更多事务以这种并发的方式去访问那些不相交的数据集时,并行性就越高

这个协议很流行
当然这里依然需要给这些事务分配 id,然后要根据这些 id 对这些事务进行排序
### 读操作

如果读取存在于多个数据库分区中的几行数据时,情况就会变得复杂,比如通过一个事务来对 2 个不同分区内的 Customer 信息进行修改,那么情况就会变得复杂
在执行这个操作之前,必须要获取这 2 个不同分区的 lock 才行
当然这种方式就会损耗性能了,所以用基于分区的 T/O 时就要注意这些问题
### 写操作

因为在基于分区的 T/O 的方式看来,会保证同一时间只有一个事务在执行,那么就可以在数据库中直接更新数据,回滚也是,但是可以在不需要制作本地副本的情况下做到这点,这样就能减少通常存在于 OCC 系统中那些数据复制所带来的开销
### 例子

假设这里 2 个服务器都要试着去访问第一个分区中的某个客户的数据

它们发起的 BEGIN 请求,就会进入一个事务队列进行排队,然后被分配时间戳(100 和 101)

然后执行时间戳较小的那个事务,即 server1,它会去获取这个数据库分区对应的 lock

操作完成后,server1 提交了该事务,这样做是安全的,因为同一时间没有其他事务在执行

那么 server2 就可以排在队列前面,获取 lock 并执行
### 性能问题

如果数据库在开始执行事务之前就知道这些事务需要用到哪些分区,那么这些系统的速度就会很快,但是在这种事务协议中,这样的做法并不现实
如果事务要接触多个分区,就必须先执行一下该事务,接着中止该事务,获取更多的 lock 并重新执行该事务,这样系统就会变得很慢
这种多分区设置,可能会使得有些分区处于闲置状态
## 动态数据库

如果在执行事务的过程中,数据可以被插入,被更新,被删除,那么就违反了协议中制定的那些假设
## 幻读问题

这里有一个 People 表,里面有 name、age、status 字段

执行第一个 SQL,得到 72

T2 执行插入,然后切回 T1,T1 试着执行和刚才相同的查询,那么得到的结果和第一次不同

T2 要往数据库中插入一个新 tuple,它们的操作中没有用到 lock,那么这个就是一个问题
如果遇上这种幻读问题,就要确保这里可以进行可重复读
没必要获取 tuple 中的 lock,但是可以获取抽象对象对应的 lock
比如获取上述表达式中的 (status = 'lit') 的 lock,可行吗?
可行
实际上就是这么做的
## 条件锁

上述的解决方案的术语就叫做 Predicate Locking,但是实现这个方案的成本非常高,大部分数据库系统都不会去实现它
## 索引锁

假设在 status 这个字段上建立了索引,那么就对索引中 status = 'lit' 的 slot 加锁,然后任何新的插入操作都需要去遍历索引,并对索引进行更新
如果 status = 'lit' 不在索引中,就要去获取一个叫 Gap Lock(间隙锁) 的东西
> 在索引中有一个间隙,获取了该间隙对应的 lock 之后,如果另一个插入操作试图将符合 (status = 'lit') 条件的 tuple 插入索引中的这个间隙,就不允许它这么做
## 不使用索引加锁

对 page、table 加锁,或者使用层级锁(hierarchical lock)
## 重复扫描

在事务提交前,进行反复扫描
读的数据在提交的这一刻就是最新的,如果不是,就重启事务
## 结论
暂无
