
【Python爬虫教程】Python网络爬虫最全视频教程(含项目实战)

1.什么是爬虫?
请求网站并提取其中所需数据的自动化程序

实例演示:
2.爬虫的基本流程
1》发起请求
通过HTTP库向目标点发送request(可包含headers等信息),等待服务器响应
2》获取响应内容
如果服务器能正常响应,则会返还response,其中包含的内容就是所需的内容(可能有HTML<超文本标记语言>,Json字符串,二进制数据<图片视频等>等类型)
3》解析内容
得到内容后,需要用相应的解析库对内容进行解析,从而对内容进行保存或下一步的处理
4》保存数据
可以存为文本,也可以存于数据库或者其它特定格式文件

3.request与response

实例演示:
4.request的包含
1》请求方式
主要常用的有GET和POST,此外还有不常用的HEAD,PUT,DELETE,OPTIONS等
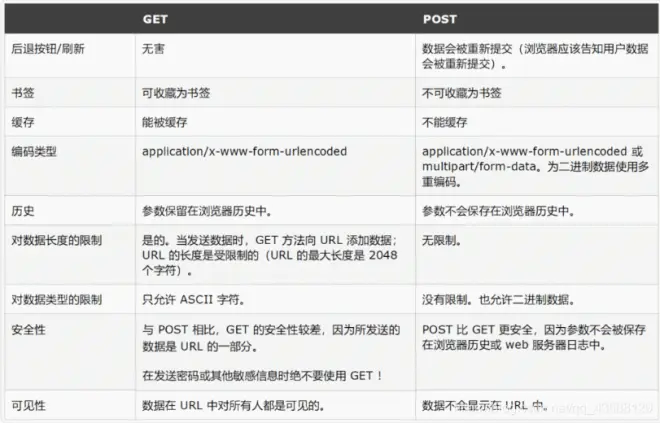
<GET与POST的区别>
1、安全性不同
get请求:GET 方法发送的数据不受保护,因为数据在 URL 栏中公开,它以明文形式保存在浏览器历史记录和服务器日志中,这增加了漏洞和黑客攻击的风险。
post请求:POST 方法发送的数据是安全的,因为数据未在 URL 栏中公开,参数不会存储在浏览器历史记录或 Web 服务器日志中,还可以在其中使用多种编码技术,这使其具有弹性。
2、编码类型(enctype 属性)不同
get请求:application/x-www-form-urlencoded。在表单中使用 GET 方法时,数据类型中只接受 ASCII 字符。
post请求:multipart/form-data or application/x-www-form-urlencoded 对二进制数据使用多部分编码。在表单提交时,POST 方法不绑定表单数据类型,并允许二进制和 ASCII 字符。
3、表单数据长度不同
get请求:表单数据位于 URL 中,并且 URL 长度受到限制。安全 URL 长度限制通常为 2048 个字符,但因浏览器和 Web 服务器而异。
post请求:无限制。
4、添加书签不同
get请求:GET 查询的结果可以加入书签中,因为它以 URL 的形式存在。
post请求:POST 查询的结果无法加入书签中。
5、数据可变大小
get请求:GET 方法中的可变大小约为 2000 个字符。
post请求:POST 方法最多允许 8 Mb 的可变大小。
6、缓存不同
get请求:GET 方法的数据是可缓存的。
post请求:POST 方法的数据是无法缓存的。
7、主要作用不同
get请求:GET 方法主要用于获取信息。
post请求:POST 方法主要用于更新数据。
8、能见度不同
get请求:GET方法对每个人都是可见的(它将显示在浏览器的地址栏中),并且对要发送的信息量有限制。
post请求:POST 方法变量不会显示在 URL 中。
9、发送的数据数量不同
get请求:在 GET 中,只能发送有限数量的数据,因为数据是在 URL 中发送的。
post请求:在 POST 中,可以发送大量的数据,因为数据是在正文主体中发送的。
10、可用性不同
get请求:发送密码或其他敏感信息时,不应使用 GET 方法。
post请求:发送密码或其他敏感信息时应使用 POST 方法。
2》请求URL
URL:统一资源定位符,如网页文档,一张图片,一个视频等都可用URL唯一来确定
3》请求头reques-headers
请求时的头部信息,即请求内容中比较重要的配置信息,如User-Agent(用户代理)Host(端口),Cookies(小型文本)等信息
4》请求体
请求时额外所带的数据,如表单提交时的表单数据
一般来说,请求体在进行GET请求时不会携带任何内容,但在POST请求中,请求体会处于from-data的形式
5.response的包含
1》响应状态
如200(响应成功),301(跳转),404(找不到资源),502(服务器错误)
2》响应头
如内容类型,长度,服务器信息,设置cookie等
3》响应体
最主要部分,包含了请求资源的内容,如网页HTML,图片二进制数据等
6.运用
7.爬虫的抓取范围

8.解析数据的方法
1》直接处理
适合处理最简单的字符串,只需要进行最简单的处理即可,如去除头部或尾部的空格
前提:构造网页简单,返还数据简单
2》JSON解析
适合那些运用AJAX数据加载的网页,这些网页返还的数据往往是js格式的字符串,这时就需要JSON解析
3》正则表达式
实际上就是规则字符串,能把一些HTML代码里的一些相应文本提取出来,应用较为普遍
4》利用解析库
如BeautifulSoup,PyQuery,XPath
7.疑问解答
1》 抓取数据与所求数据不同
8.解决JavaScript渲染问题
1》分析Ajax请求
2》使用Selenium或WebDriver模块模拟网页加载
3》利用splash软件模拟网页
4》利用PyV8,Ghost.py
9.如何保存数据
1》纯文本
2》关系型数据库
3》非关系型数据库
4》二进制文件
