
【教程】纯原生异步特性,教你用JavaScript快速获取壁纸站
节目编号:[08-1202S/08-1203R]
切记请勿用于违法用途,一切后果与作者无关!请尊重原作者著作权,除学习外禁止未经同意随意抓取数据,禁止应用于商业化行为!

原理架构分析
众所周知网页渲染出来还是html,而html都是由一部分一部分的标签组成的,对于表格,图库这类网站来说,这一部分和一部分是相似的结构,比如<tr><td>,<div class="xxx">,通过class,id,tagName的规律,不难找到相似元素,本期就以壁纸站为例:

第一步,打开F12,开发者工具分析结构

这一个个整齐的DIV,就是每一个图块对应的结构,他们的query选择器为'.thumb-container-big'
再把元素展开看看




我们正好只要这两部分,原图和标题
接下来展开boxgrid


控制台里发现最大的一张

600*375显然不是我们要的分辨率,进入图片详情看看

1920*1080的,他们的URL分别如下:
缩略:533/thumbbig-533007.png
原图:533/533007.png
多看几张,缩略图都是thumbbig-xxx.webp,原图都是xxx.png
所以我们只需要替换掉thumbbig-为空,.webp为png即可
或者如果我们注意到元素id正好对应图片的名称
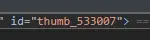
替换掉thumb_即可,但是我们就无法获取上级目录了
如果要获取,就得用indexOf索引内容,太过于复杂,所以还是老老实实根据Picture里面的source属性吧
理论存在实践开始
考虑到一些网站没有jquery,所以整个过程全部是原生js运行
捕捉父级元素
案例中的元素class为thumb-container-big
所以引入方法

已经捕获到了31个元素,先用第一个元素分析
捕捉子元素
一步一步抓下去

PS:这里用jQuery会更方便些
最后得到代码:
这时候已经获取到我们的Picture元素了
只需要获取他的属性srcset就能获得缩略图地址
所以我们用attributes对象获得属性:

正是我们想要的链接
但是获取出来的确实一个xml格式的内容:
转化为文本:.textContent
这就是我们第一个元素捕获的方法,接下来就很简单了,把它封装为一个方法,方便调用:

获得原图
根据上面的分析,我们对链接进行字符串替换:

遍历循环
由于class的数量正好是图片数量,所以直接根据class进行遍历

我们的代码已经很完美,但是我不希望在控制台里输出,想要保存到文本文档怎么办?直接post到一个支持保存文件的后端即可,在这里不介绍
代码运行速度非常地快,回车一瞬间就全部跑完了,可见异步执行的威力
技术总结
优点:迅速,轻量,便捷
缺点:需要手动翻页,手动运行代码,半自动化
