A卡 ChatGLM2本地部署教程(Linux)
【前言】
本专栏文章适用于AMD显卡在本地部署ChatGLM2-6B模型,该模型是由清华大学
THUDM 开源的项目。
本人实测中文对话上,对比ChatGPT3.5还是有一定差距。但是该项目优势是开源,可以在消费级显卡上本地运行,而且可用较低显存训练微调模型,满足个人定制化需求。
【环境准备】
系统要求:Linux (推荐Ubuntu22.04)
显卡要求:4G显存以上(本人未测试4G,一般推荐6G及以上)
首先要保证显卡驱动已经正确安装,测试方法为在终端中输入:
rocm-smi需要有GPU信息出现。如果还不会安装Ubuntu22.04和显卡驱动,请使用我之前开发的Stable-Diffusion启动器一键安装显卡驱动。如果显卡是7900,请查看个人首页7900专栏文章手动安装显卡驱动。
【部署步骤】
首先在主目录任意文件夹中打开终端,将项目clone到本地后进入项目文件夹:
git clone https://github.com/THUDM/ChatGLM2-6B
cd ChatGLM2-6B创建虚拟python环境并激活:
sudo apt install python3.10-venv
python3 -m venv venv
source venv/bin/activate激活成功后,用户名前方会有 (venv) 字样,代表已经激活python虚拟环境:

安装项目运行所需的pytorch和其他组件(pytorch根据显卡不同选择版本):
//rx7000 rx6000
pip3 install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/rocm5.6
//rx5000
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm5.4.2
pip3 install -r requirements.txt最后,需要下载ChatGLM2的模型文件。有两种模型:
1、标准的ChatGLM2-6B模型,大约需要13G显存
2、ChatGLM2-6B-int4模型需要至少4G显存
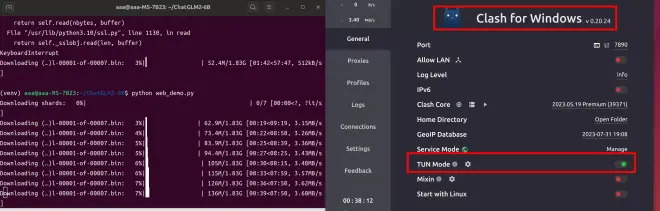
模型在线拉取需要有魔法网络。Linux中一般使用下面这个软件,并启用TUN模式开启魔法,下载模型时请使用全局Global模式,不然容易出错:
16G及以上显卡:
如果你的显卡显存为16G或以上,保证魔法网络环境较好的情况下,在虚拟环境中直接运行:
python web_demo.py即可自动下载需要的相关模型。耐心等待下载完成后,即可自动进入对话页面。以后每次启动,在项目文件夹内部运行这两个命令即可启动:
source venv/bin/activate
python web_demo.py16G以下显卡:
如果显存不够13G,需要编辑项目中的 web_demo.py 文件,将该文件第7行改为:
model = AutoModel.from_pretrained("THUDM/chatglm2-6b-int4",trust_remote_code=True).cuda()保存后。以后每次启动项目需要先激活虚拟环境,然后根据显卡型号选择启动命令:
source venv/bin/activate
//rx7000
python web_demo.py
//rx6000 rx5000
HSA_OVERRIDE_GFX_VERSION=10.3.0 python web_demo.py
//rx Vega
PYTORCH_ROCM_ARCH=gfx906 HCC_AMDGPU_TARGET=gfx906 python web_demo.py启动后,需要保证魔法环境开了全局模式,会自动下载一个3.9G的模型文件,完成后即可正常运行。
另外,如果你的内存小于16G,也请使用之前的stable-diffusion启动器开启虚拟交换内存(命令行开启也可以),不然会有错误提示。