
15分钟入门AI动画!Mov2Mov零基础教学,用Stable Diffusio

*觉得笔记不错的可以来个一键三连♡
(16分钟的视频打完发现过去两小时咯)
一、AI动画“古法”逐帧重绘
*视频、动画其实也是由一张张静止的图片连续播放而成的,每一张图片叫做视频的“一帧”

SD中的图生图可以把一张图片“重绘“成任何一种风格
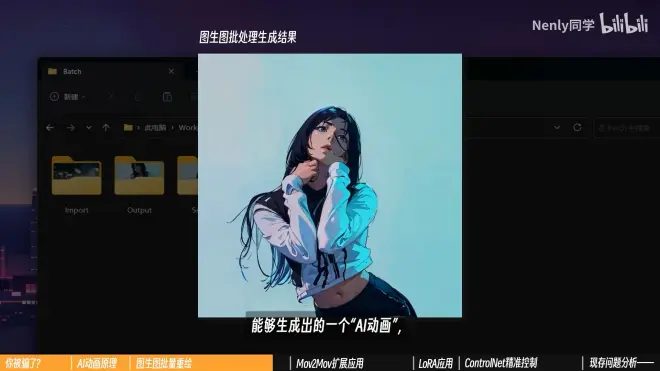
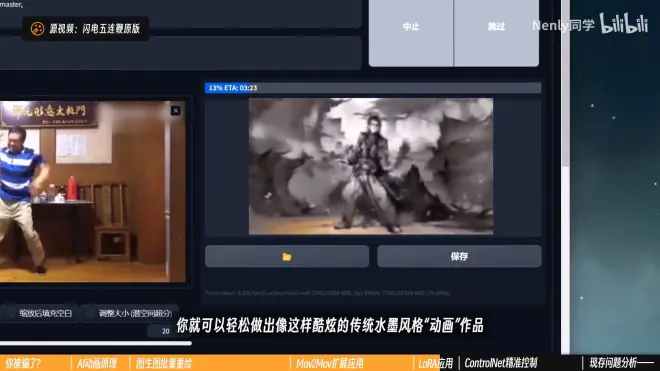
AI动画本质上就是把视频每秒的20-30张画面拆开,单独重绘每一张画面,再拼回去变成一个完整的视频
二、图生图批量重绘
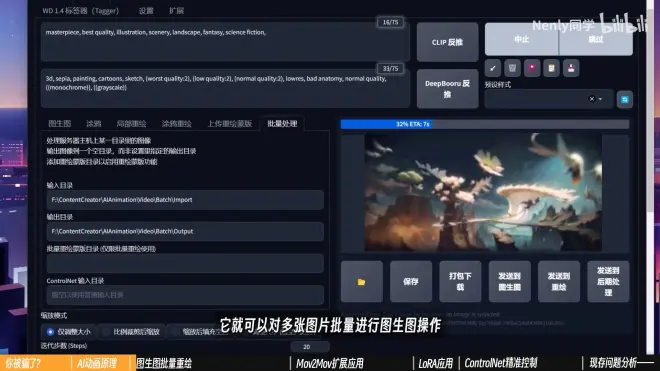
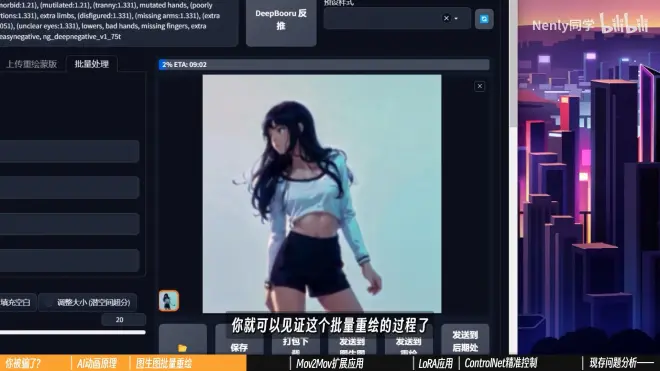
1.SD中图生图标签里有一个“批量处理”功能
设置好输入目录和输出目录就可以对多张图片批量进行图生图操作
*输入目录:存放将要重绘图片的文件夹路径
输出目录:存放重绘完成图片文件夹路径
还可以批量导入重绘模板和骨骼图(进阶,暂时不聊)
2.将视频变为图片
(1)如果会操作Pr等剪辑软件,可以将一个视频导出一张张的图片序列进行重绘
(2)为了照顾不会剪辑软件的同学,争取全部在Webui里完成
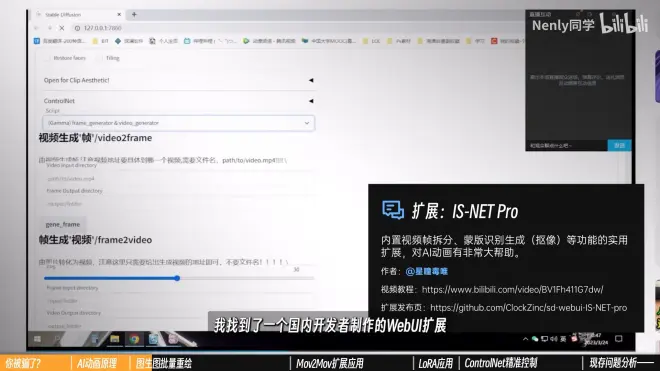
【IS-NET Pro】
作者:@星瞳毒唯
教程:BV1Fh411G7dw
仓库:https://github.com/ClockZinc/sd-webui-IS-NET-pro
安装完成后打开SD找到“IS-NET Pro”的标签
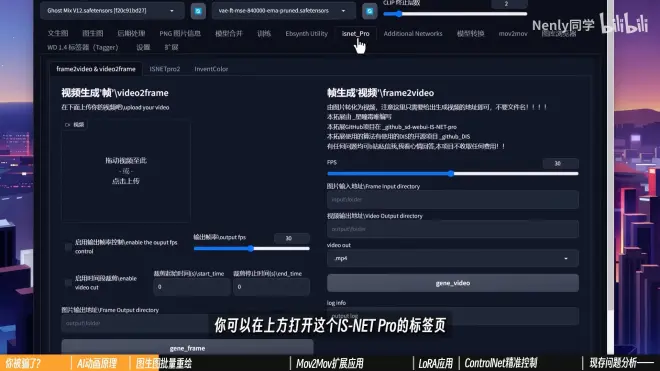
可以将导入的视频拆分成单帧图片
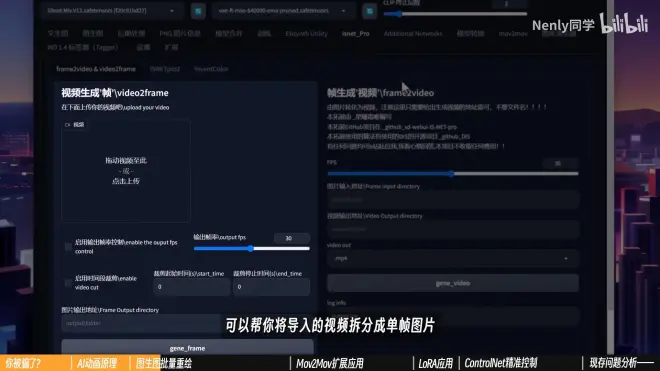
(3)插件具体功能介绍
①视频”拆散“
启用输出帧率控制:调节视频的帧率
不勾选默认帧率输出图片
查看视频帧率:右键一个视频—属性—详细信息—帧速率
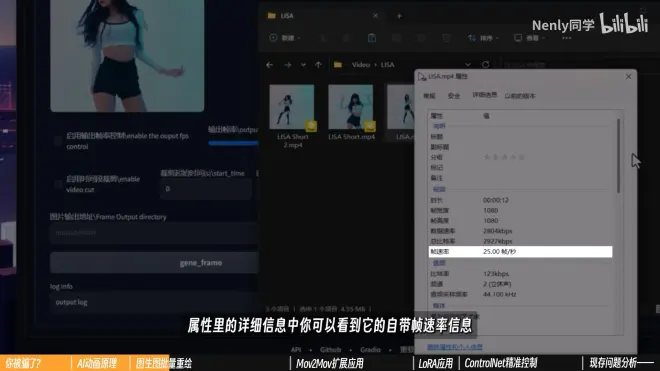
帧速率25.00帧/秒:每秒播放25张图片,30帧:每秒30张图片,60帧:每秒60张图片
启用时间段裁剪:控制裁剪视频从哪开始到哪里结束,比较长的视频可以用这个来截短
图片输出地址:生成的图片存放路径
②图片“重组”
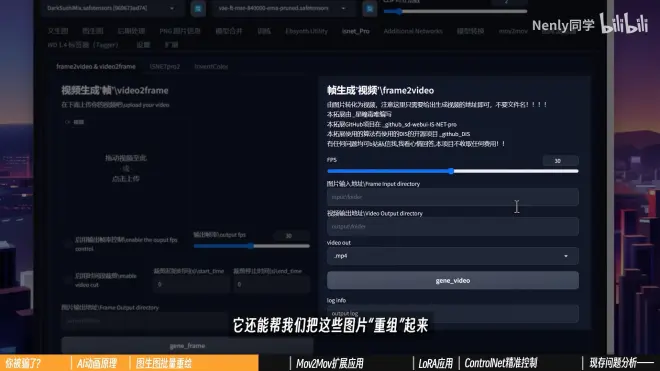
FPS:帧率
原视频帧率是多少,输出视频帧率要保持一致,不然视后期处理的视频速度对不上
图片输入地址:刚刚批处理输出的文件夹路径
视频输出地址:保存视频的文件夹路径
3.风格测试
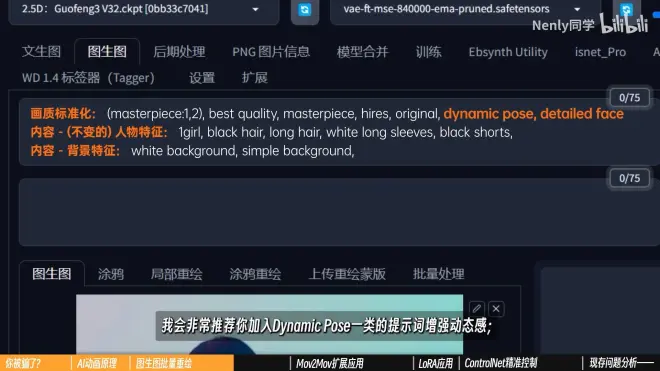
写tag:一般精确到从头到尾都适用的外貌特征就够了,画质标准化+(内容,不变的)人物特征+背景特征
*视频转绘幅度较大,推荐加入dynamic poise提示词增强动态感,detailed face提示词可以确保在半身或全身画面下人物的脸部不至于太过模糊
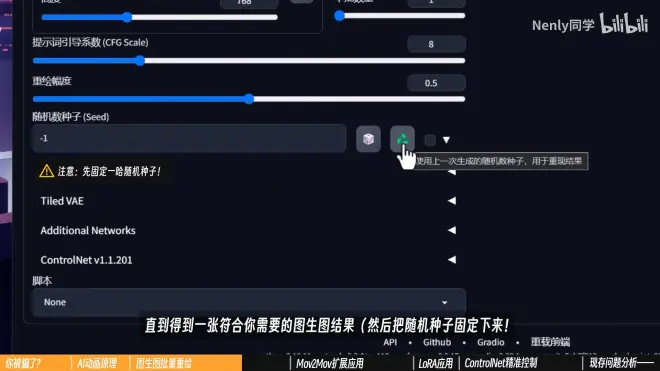
设置完成后点击生成,直到有一张符合自己需要的图生图结果,然后把随机种子固定下来
打开批处理,把输入输出文件夹设置好,点击生成,批量重绘就开始了
三、Mov2Mov扩展应用(真正视频到视频的转换)
扩展插件:
【Mov2Mov】
作者:@小丁NaNd
教程:BV1Mo4y1a7DF
仓库:https://github.com/Scholar01/sd-webui-mov2mov
1.功能介绍
打开SD中的Mov2Mov标签
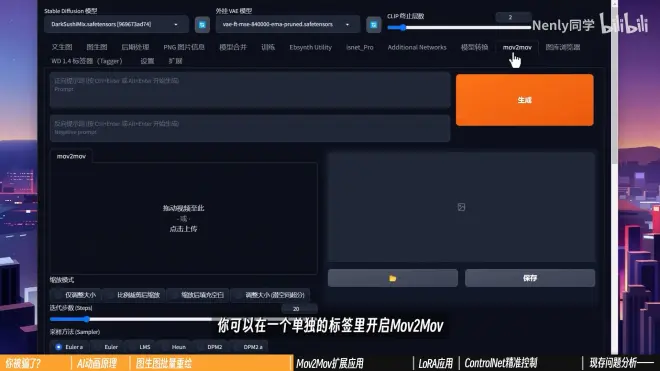
功能设置选项与图生图基本一致,导入图片变成了导入视频
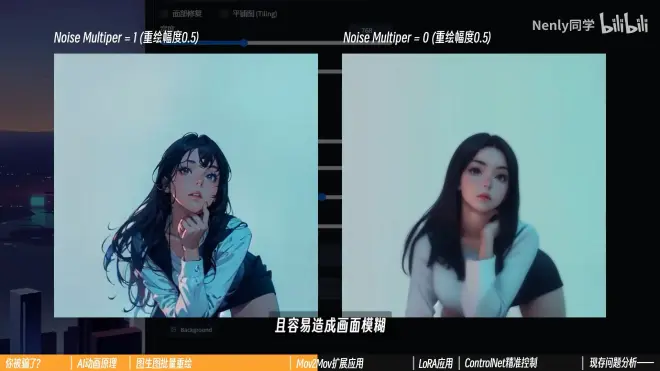
噪声(重绘幅度)乘数 [Noise multiplier](不常用)
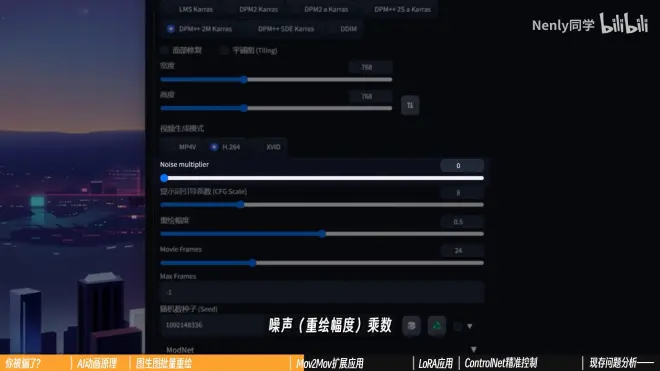
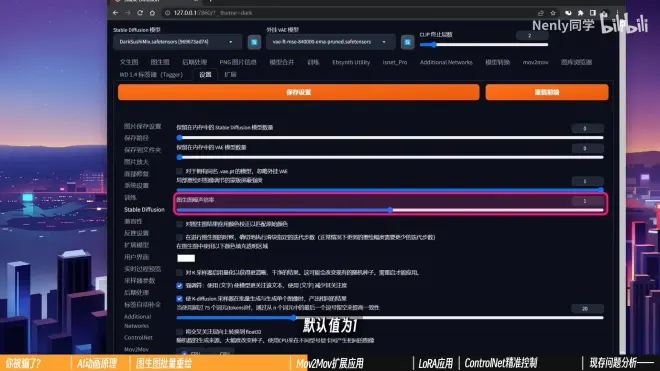
它被藏在设置—Stable Diffusion中,默认值为1
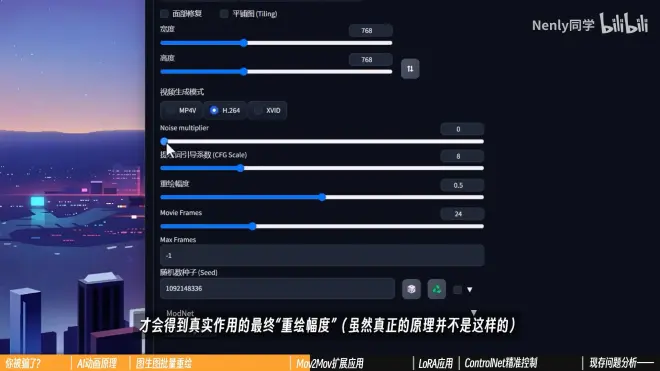
简单理解:输入的重绘幅度乘以这个数才会得到真实作用的最终“重绘幅度”(虽然真正的原理并不是这样)
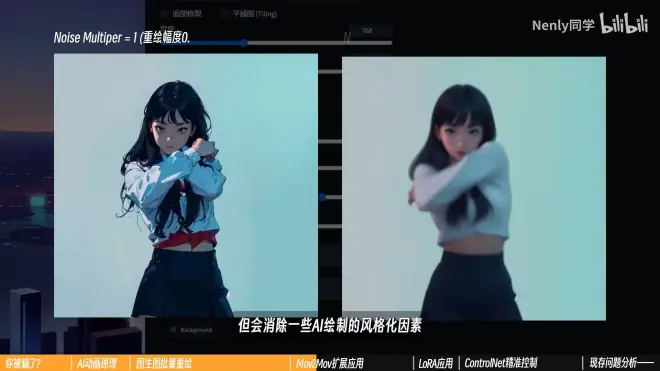
很多AI动画创作者会设置一个很低的数值(甚至是0),以确保稳定度以及产出作品和原视频足够像,但是会消除一些AI绘制的风格化因素,容易造成画面模糊

Movie Frame:帧率,保持与原视频一致
Max Frame:用来“测试”的选项,先生成一小段视频查看效果
设置成-1时不生效,输入50,就是先画50帧
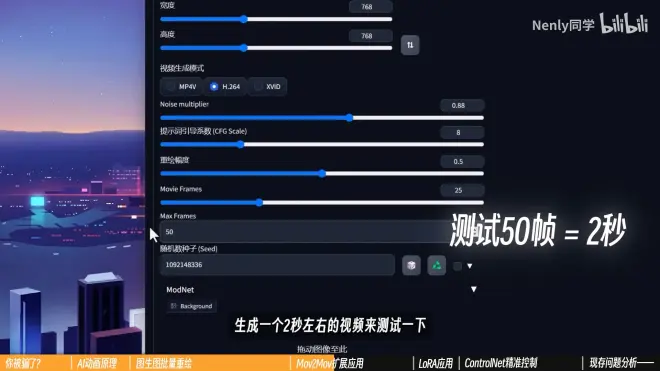
ModNet:清除背景的选项,似乎需要加载额外模型,可以维持默认不开启
2.设置完成后点击生成,生成完可以直接在页面中预览

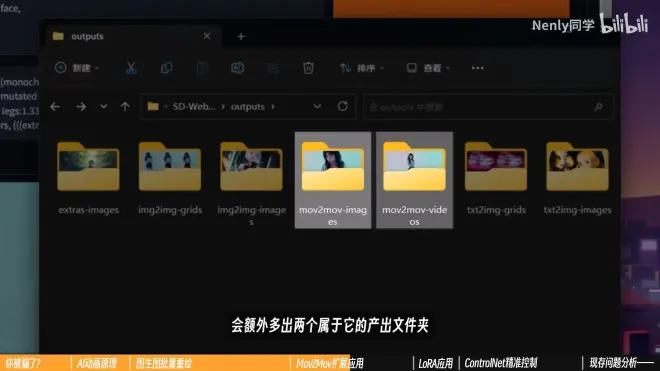
3.如果通过Mov2Mov生成的视频
在你根目录下的outputs文件夹里,会多出两个文件夹,videos存放成品视频,images存放单帧绘制的图片
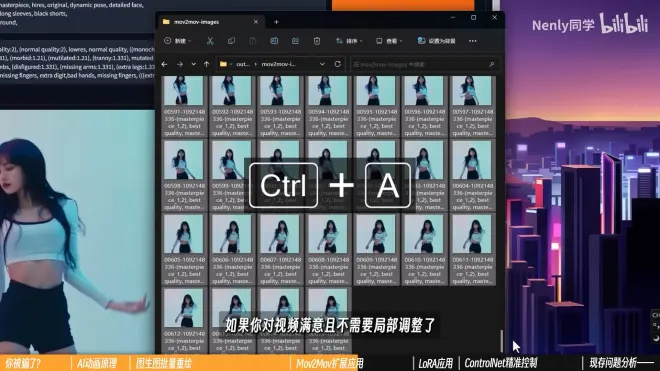
对生成的视频满意且不需要局部调整可以将images文件夹里的图片删除
4.两者对比
批处理和Mov2Mov没有太大区别

优点和缺点

*通病:都不能把音频整合进来,可以用任意一款剪辑软件把音频导入
5.注意模型和重绘幅度
模型:决定画风的最大要素,不同模型出来的效果不一样
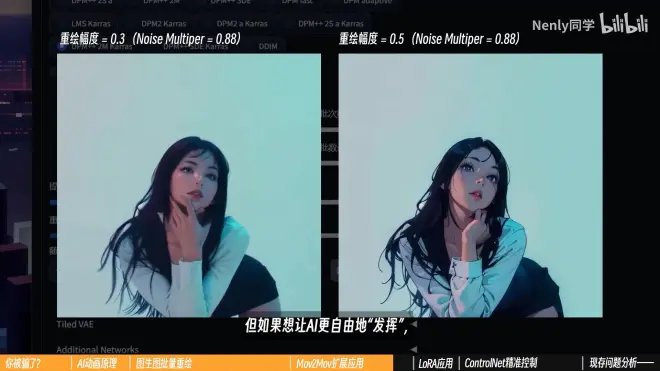
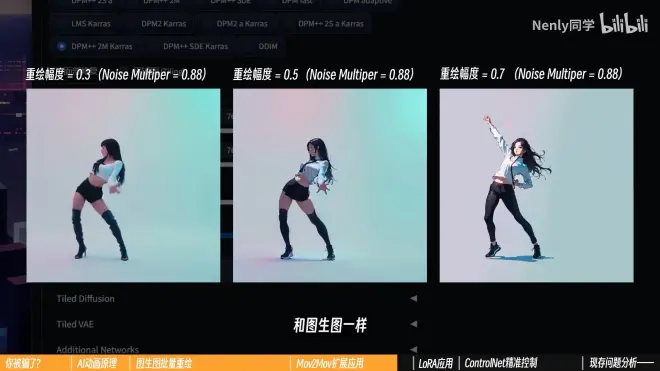
重绘幅度:没有绝对的正确答案
追求与原视频“更像”,就设置比较低一些
想让AI自由”发挥“,保留更多模型特质,就设置高一些,但最好不要超过0.5,高了图像一般不稳定
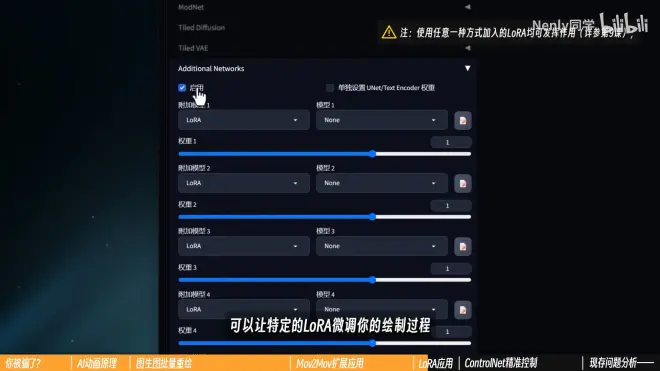
四、LoRA应用
在批处理或者Mov2Mov中开启Additional Network
可以让特定的LoRA微调
LoRA具体作用看前面的第9课
AI动画中最常见的应用是使用一些画风LoRA让画面增强某种风格特色
水墨风格LoRA:泼墨 lnk Splash
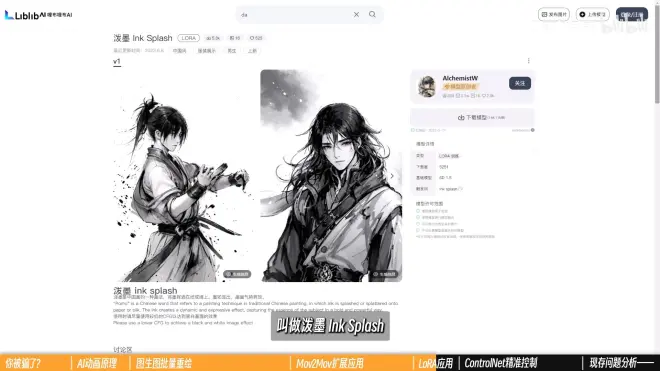

对画面“改动”不是那么大,添加一些细节,进行润色
Detail Tweaker丰富细节
Fashion Girl“美颜”
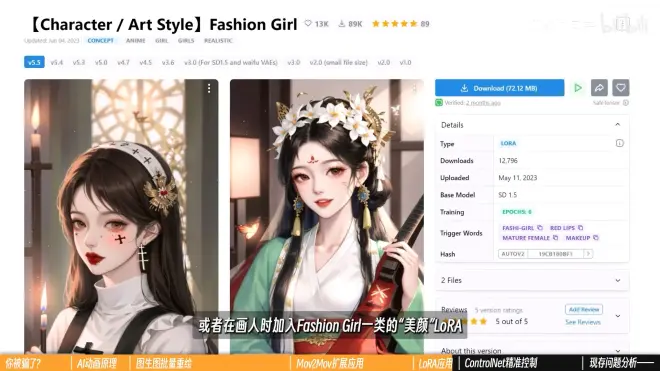
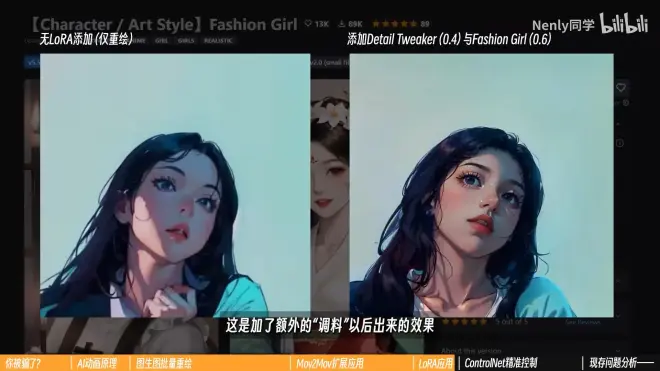
五、ControlNet:精准控制
*在第10课有具体讲解
每种ControlNet在AI动画中都可以发挥一定的效果
1.AI动画视频内的效果控制
(1)还原人物姿势:使用Openpose,开启Face,增强对表情复现的生动程度
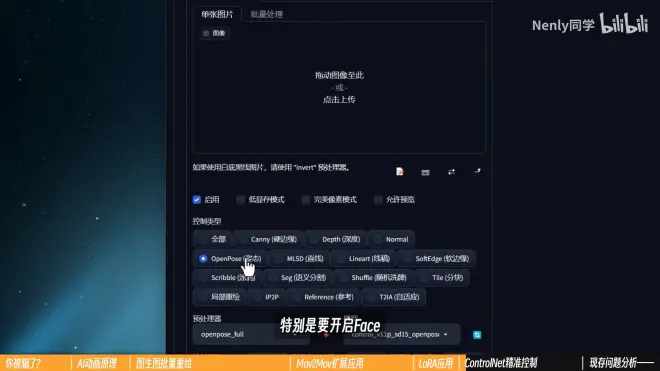

近身镜头会拍到手部的要开启Hand
嫌麻烦开Full,一步到位
(2)还原场景特征:开启Depth,极大程度降低发生在复杂背景里闪烁程度
(3)画面变化幅度不大,主体比较固定:
开启Canny和SoftEdge,能还原准确的主体形象
(4)如果使用的是最新1.1的ControlNet,还可以开启Lineart(线稿)的模型
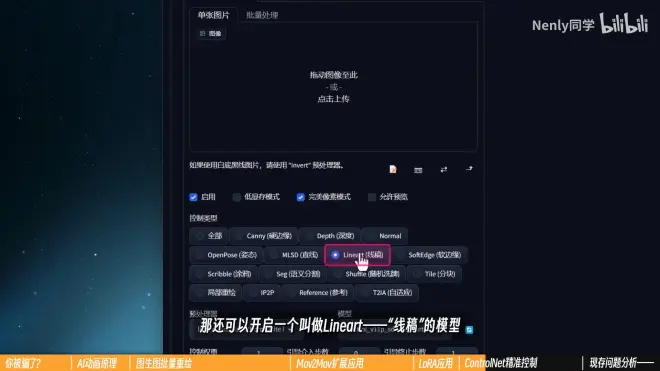
提取比Canny更为精细且富有连贯的线条

在输入不同属性的信息图时,记得选择对应的预处理器,让结果变得更准确
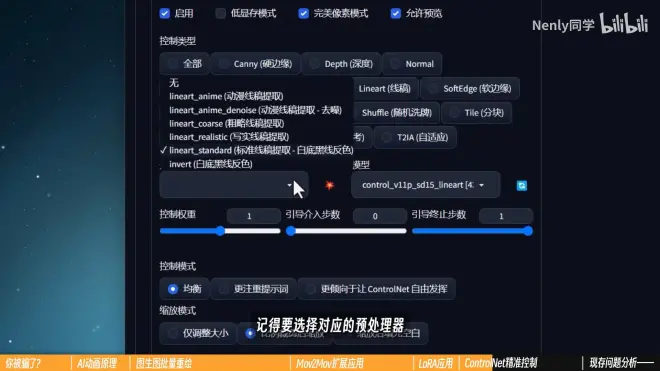
2.没人炼LoRA
最新1.1的ControlNet推出一个新的模型Reference ONLY,作用是可以提供“参考”
把记载主体形象的图片置入到ControlNet中,开启Reference ONLY,在生成过程中都去“复现”这张图上的特征,让生成出来的每张图跟原始图足够像



加了东西要比不加的要稳定、自然得多
3.推荐
在AI动画中使用多重控制网

但up主并没有推荐在AI动画中使用太多ControlNet,因为过多的控制会丧失AI的创造力
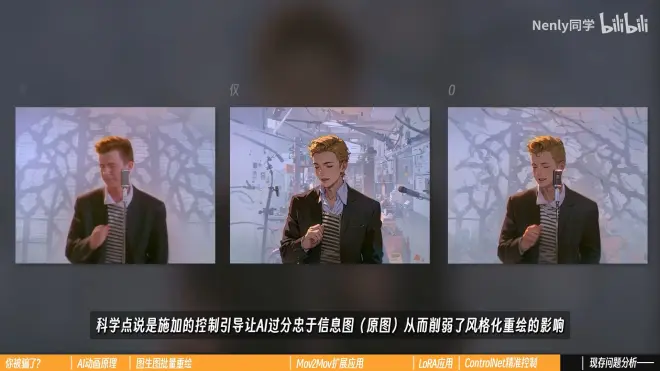
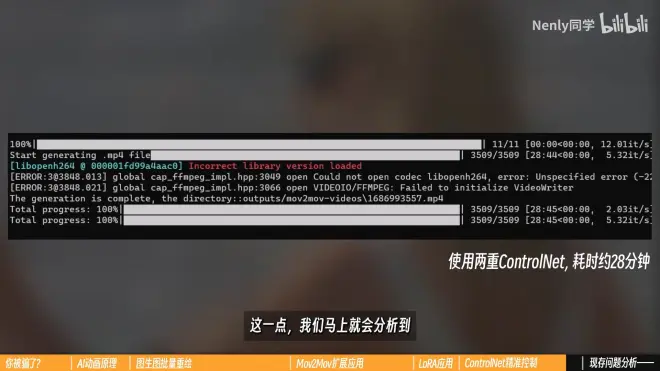
使用多重ControlNet,会降低绘制速度
六、AI动画现存在的问题
AI动画目前还不是很成熟,有三点原因:
“错乱”:AI不能正确读取每一张图片上的内容,且无法理解一些动作表现与空间关系,在画面越来越复杂时,变得越来越严重
“闪烁”:AI在刻画前后的帧时经常存在“不一致”的现象,从人物外观特征到服饰到场景,都有可能变化,从而造成类似画面一直在闪动的效果

“速度慢”:每生成1秒25帧的视频大概要40秒左右的时间
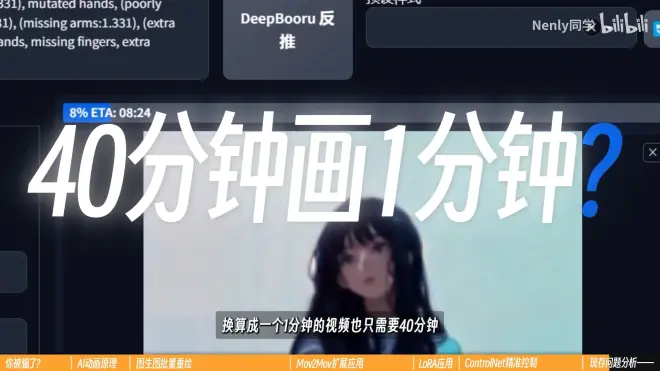
好像速度还行?但up的显卡是4090

再进一步开启ControlNet等扩展,时间会两倍、三倍往上翻,还没算上反复调试、测试用的时间


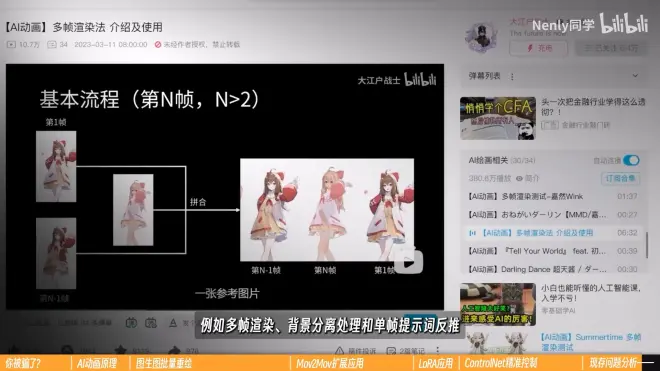
扩展:多帧渲染

时长变为原来的3倍
那如何既轻松、又稳定地把这个动画做出来呢?
请看下集
